 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanoid Robot RHP Friends: Seamless Combination of Autonomous and Teleoperated Tasks in a Nursing Context
Dec 30, 2024



This paper describes RHP Friends, a social humanoid robot developed to enable assistive robotic deployments in human-coexisting environments. As a use-case application, we present its potential use in nursing by extending its capabilities to operate human devices and tools according to the task and by enabling remote assistance operations. To meet a wide variety of tasks and situations in environments designed by and for humans, we developed a system that seamlessly integrates the slim and lightweight robot and several technologies: locomanipulation, multi-contact motion, teleoperation, and object detection and tracking. We demonstrated the system's usage in a nursing application. The robot efficiently performed the daily task of patient transfer and a non-routine task, represented by a request to operate a circuit breaker. This demonstration, held at the 2023 International Robot Exhibition (IREX), conducted three times a day over three days.
Leveraging Large Language Model-based Room-Object Relationships Knowledge for Enhancing Multimodal-Input Object Goal Navigation
Mar 21, 2024Object-goal navigation is a crucial engineering task for the community of embodied navigation; it involves navigating to an instance of a specified object category within unseen environments. Although extensive investigations have been conducted on both end-to-end and modular-based, data-driven approaches, fully enabling an agent to comprehend the environment through perceptual knowledge and perform object-goal navigation as efficiently as humans remains a significant challenge. Recently, large language models have shown potential in this task, thanks to their powerful capabilities for knowledge extraction and integration. In this study, we propose a data-driven, modular-based approach, trained on a dataset that incorporates common-sense knowledge of object-to-room relationships extracted from a large language model. We utilize the multi-channel Swin-Unet architecture to conduct multi-task learning incorporating with multimodal inputs. The results in the Habitat simulator demonstrate that our framework outperforms the baseline by an average of 10.6% in the efficiency metric, Success weighted by Path Length (SPL). The real-world demonstration shows that the proposed approach can efficiently conduct this task by traversing several rooms. For more details and real-world demonstrations, please check our project webpage (https://sunleyuan.github.io/ObjectNav).
Visual Gyroscope: Combination of Deep Learning Features and Direct Alignment for Panoramic Stabilization
Feb 02, 2024


In this article we present a visual gyroscope based on equirectangular panoramas. We propose a new pipeline where we take advantage of combining three different methods to obtain a robust and accurate estimation of the attitude of the camera. We quantitatively and qualitatively validate our method on two image sequences taken with a $360^\circ$ dual-fisheye camera mounted on different aerial vehicles.
Enhanced Visual Feedback with Decoupled Viewpoint Control in Immersive Humanoid Robot Teleoperation using SLAM
Nov 03, 2022



In immersive humanoid robot teleoperation, there are three main shortcomings that can alter the transparency of the visual feedback: the lag between the motion of the operator's and robot's head due to network communication delays or slow robot joint motion. This latency could cause a noticeable delay in the visual feedback, which jeopardizes the embodiment quality, can cause dizziness, and affects the interactivity resulting in operator frequent motion pauses for the visual feedback to settle; (ii) the mismatch between the camera's and the headset's field-of-views (FOV), the former having generally a lower FOV; and (iii) a mismatch between human's and robot's range of motions of the neck, the latter being also generally lower. In order to leverage these drawbacks, we developed a decoupled viewpoint control solution for a humanoid platform which allows visual feedback with low-latency and artificially increases the camera's FOV range to match that of the operator's headset. Our novel solution uses SLAM technology to enhance the visual feedback from a reconstructed mesh, complementing the areas that are not covered by the visual feedback from the robot. The visual feedback is presented as a point cloud in real-time to the operator. As a result, the operator is fed with real-time vision from the robot's head orientation by observing the pose of the point cloud. Balancing this kind of awareness and immersion is important in virtual reality based teleoperation, considering the safety and robustness of the control system. An experiment shows the effectiveness of our solution.
3D model silhouette-based tracking in depth images for puppet suit dynamic video-mapping
Oct 09, 2018
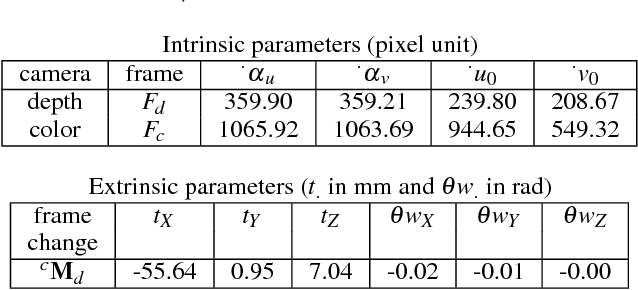


Video-mapping is the process of coherent video-projection of images, animations or movies on static objects or buildings for shows. This paper focuses on the dynamic video-mapping of the suit of a puppet being moved by its puppeteer on the theater stage. This may allow changing the costume dynamically and simulate light interaction and more. Contrary to common video-mapping, the image warping cannot be done once, offline, before the show. It must be done in real-time, and considering a non-flat projection surface, so that the video-projected suit always maps perfectly the puppet, automatically. Hence, we propose a new visual tracking method of articulated object, for the puppet tracking, exploiting the silhouette of a 3D model of it, in the depth images of a Kinect v2. Then, considering the precise calibration between the latter and the video-projector, that we propose, coherent dynamic video-mapping is made possible as the presented results show.