 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO-MaMa @ EgoExo4D Correspondence Challenge: Learning Object Mask Matching between Egocentric and Exocentric Views
Jun 06, 2025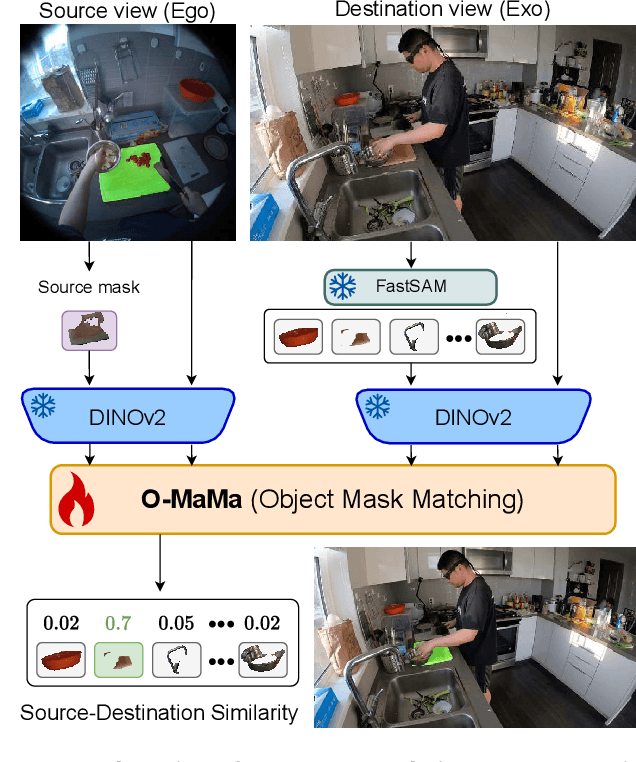
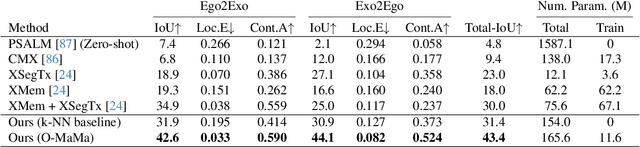

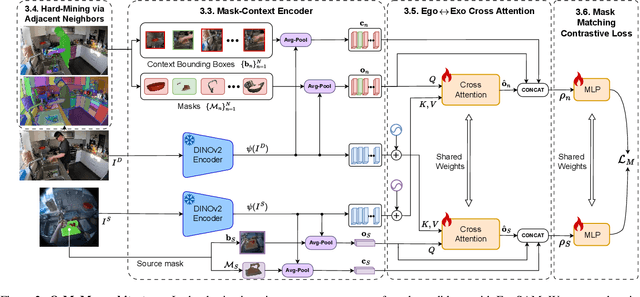
The goal of the correspondence task is to segment specific objects across different views. This technical report re-defines cross-image segmentation by treating it as a mask matching task. Our method consists of: (1) A Mask-Context Encoder that pools dense DINOv2 semantic features to obtain discriminative object-level representations from FastSAM mask candidates, (2) an Ego$\leftrightarrow$Exo Cross-Attention that fuses multi-perspective observations, (3) a Mask Matching contrastive loss that aligns cross-view features in a shared latent space, and (4) a Hard Negative Adjacent Mining strategy to encourage the model to better differentiate between nearby objects.
Knowledge Distillation for Multimodal Egocentric Action Recognition Robust to Missing Modalities
Apr 11, 2025Action recognition is an essential task in egocentric vision due to its wide range of applications across many fields. While deep learning methods have been proposed to address this task, most rely on a single modality, typically video. However, including additional modalities may improve the robustness of the approaches to common issues in egocentric videos, such as blurriness and occlusions. Recent efforts in multimodal egocentric action recognition often assume the availability of all modalities, leading to failures or performance drops when any modality is missing. To address this, we introduce an efficient multimodal knowledge distillation approach for egocentric action recognition that is robust to missing modalities (KARMMA) while still benefiting when multiple modalities are available. Our method focuses on resource-efficient development by leveraging pre-trained models as unimodal feature extractors in our teacher model, which distills knowledge into a much smaller and faster student model. Experiments on the Epic-Kitchens and Something-Something datasets demonstrate that our student model effectively handles missing modalities while reducing its accuracy drop in this scenario.
Influence of field of view in visual prostheses design: Analysis with a VR system
Jan 28, 2025Visual prostheses are designed to restore partial functional vision in patients with total vision loss. Retinal visual prostheses provide limited capabilities as a result of low resolution, limited field of view and poor dynamic range. Understanding the influence of these parameters in the perception results can guide prostheses research and design. In this work, we evaluate the influence of field of view with respect to spatial resolution in visual prostheses, measuring the accuracy and response time in a search and recognition task. Twenty-four normally sighted participants were asked to find and recognize usual objects, such as furniture and home appliance in indoor room scenes. For the experiment, we use a new simulated prosthetic vision system that allows simple and effective experimentation. Our system uses a virtual-reality environment based on panoramic scenes. The simulator employs a head-mounted display which allows users to feel immersed in the scene by perceiving the entire scene all around. Our experiments use public image datasets and a commercial head-mounted display. We have also released the virtual-reality software for replicating and extending the experimentation. Results show that the accuracy and response time decrease when the field of view is increased. Furthermore, performance appears to be correlated with the angular resolution, but showing a diminishing return even with a resolution of less than 2.3 phosphenes per degree. Our results seem to indicate that, for the design of retinal prostheses, it is better to concentrate the phosphenes in a small area, to maximize the angular resolution, even if that implies sacrificing field of view.
Visual Gyroscope: Combination of Deep Learning Features and Direct Alignment for Panoramic Stabilization
Feb 02, 2024


In this article we present a visual gyroscope based on equirectangular panoramas. We propose a new pipeline where we take advantage of combining three different methods to obtain a robust and accurate estimation of the attitude of the camera. We quantitatively and qualitatively validate our method on two image sequences taken with a $360^\circ$ dual-fisheye camera mounted on different aerial vehicles.
Scaled 360 layouts: Revisiting non-central panoramas
Feb 02, 2024From a non-central panorama, 3D lines can be recovered by geometric reasoning. However, their sensitivity to noise and the complex geometric modeling required has led these panoramas being very little investigated. In this work we present a novel approach for 3D layout recovery of indoor environments using single non-central panoramas. We obtain the boundaries of the structural lines of the room from a non-central panorama using deep learning and exploit the properties of non-central projection systems in a new geometrical processing to recover the scaled layout. We solve the problem for Manhattan environments, handling occlusions, and also for Atlanta environments in an unified method. The experiments performed improve the state-of-the-art methods for 3D layout recovery from a single panorama. Our approach is the first work using deep learning with non-central panoramas and recovering the scale of single panorama layouts.
* arXiv admin note: substantial text overlap with arXiv:2401.17058
Convolution kernel adaptation to calibrated fisheye
Feb 02, 2024Convolution kernels are the basic structural component of convolutional neural networks (CNNs). In the last years there has been a growing interest in fisheye cameras for many applications. However, the radially symmetric projection model of these cameras produces high distortions that affect the performance of CNNs, especially when the field of view is very large. In this work, we tackle this problem by proposing a method that leverages the calibration of cameras to deform the convolution kernel accordingly and adapt to the distortion. That way, the receptive field of the convolution is similar to standard convolutions in perspective images, allowing us to take advantage of pre-trained networks in large perspective datasets. We show how, with just a brief fine-tuning stage in a small dataset, we improve the performance of the network for the calibrated fisheye with respect to standard convolutions in depth estimation and semantic segmentation.
OmniSCV: An Omnidirectional Synthetic Image Generator for Computer Vision
Jan 30, 2024Omnidirectional and 360{\deg} images are becoming widespread in industry and in consumer society, causing omnidirectional computer vision to gain attention. Their wide field of view allows the gathering of a great amount of information about the environment from only an image. However, the distortion of these images requires the development of specific algorithms for their treatment and interpretation. Moreover, a high number of images is essential for the correct training of computer vision algorithms based on learning. In this paper, we present a tool for generating datasets of omnidirectional images with semantic and depth information. These images are synthesized from a set of captures that are acquired in a realistic virtual environment for Unreal Engine 4 through an interface plugin. We gather a variety of well-known projection models such as equirectangular and cylindrical panoramas, different fish-eye lenses, catadioptric systems, and empiric models. Furthermore, we include in our tool photorealistic non-central-projection systems as non-central panoramas and non-central catadioptric systems. As far as we know, this is the first reported tool for generating photorealistic non-central images in the literature. Moreover, since the omnidirectional images are made virtually, we provide pixel-wise information about semantics and depth as well as perfect knowledge of the calibration parameters of the cameras. This allows the creation of ground-truth information with pixel precision for training learning algorithms and testing 3D vision approaches. To validate the proposed tool, different computer vision algorithms are tested as line extractions from dioptric and catadioptric central images, 3D Layout recovery and SLAM using equirectangular panoramas, and 3D reconstruction from non-central panoramas.
Floor extraction and door detection for visually impaired guidance
Jan 30, 2024Finding obstacle-free paths in unknown environments is a big navigation issue for visually impaired people and autonomous robots. Previous works focus on obstacle avoidance, however they do not have a general view of the environment they are moving in. New devices based on computer vision systems can help impaired people to overcome the difficulties of navigating in unknown environments in safe conditions. In this work it is proposed a combination of sensors and algorithms that can lead to the building of a navigation system for visually impaired people. Based on traditional systems that use RGB-D cameras for obstacle avoidance, it is included and combined the information of a fish-eye camera, which will give a better understanding of the user's surroundings. The combination gives robustness and reliability to the system as well as a wide field of view that allows to obtain many information from the environment. This combination of sensors is inspired by human vision where the center of the retina (fovea) provides more accurate information than the periphery, where humans have a wider field of view. The proposed system is mounted on a wearable device that provides the obstacle-free zones of the scene, allowing the planning of trajectories for people guidance.
Atlanta Scaled layouts from non-central panoramas
Jan 30, 2024In this work we present a novel approach for 3D layout recovery of indoor environments using a non-central acquisition system. From a non-central panorama, full and scaled 3D lines can be independently recovered by geometry reasoning without geometric nor scale assumptions. However, their sensitivity to noise and complex geometric modeling has led these panoramas being little investigated. Our new pipeline aims to extract the boundaries of the structural lines of an indoor environment with a neural network and exploit the properties of non-central projection systems in a new geometrical processing to recover an scaled 3D layout. The results of our experiments show that we improve state-of-the-art methods for layout reconstruction and line extraction in non-central projection systems. We completely solve the problem in Manhattan and Atlanta environments, handling occlusions and retrieving the metric scale of the room without extra measurements. As far as the authors knowledge goes, our approach is the first work using deep learning on non-central panoramas and recovering scaled layouts from single panoramas.
Non-central panorama indoor dataset
Jan 30, 2024Omnidirectional images are one of the main sources of information for learning based scene understanding algorithms. However, annotated datasets of omnidirectional images cannot keep the pace of these learning based algorithms development. Among the different panoramas and in contrast to standard central ones, non-central panoramas provide geometrical information in the distortion of the image from which we can retrieve 3D information of the environment [2]. However, due to the lack of commercial non-central devices, up until now there was no dataset of these kinds of panoramas. In this data paper, we present the first dataset of non-central panoramas for indoor scene understanding. The dataset is composed by {\bf 2574} RGB non-central panoramas taken in around 650 different rooms. Each panorama has associated a depth map and annotations to obtain the layout of the room from the image as a structural edge map, list of corners in the image, the 3D corners of the room and the camera pose. The images are taken from photorealistic virtual environments and pixel-wise automatically annotated.