 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability Without Tradeoffs: Disentangling Polysemanticity At Equal Predictive Performance
May 29, 2026Deep neural networks (DNNs) are widely used, but interpreting what they actually learn remains difficult. A major obstacle is that individual neurons often encode multiple unrelated concepts, obscuring the decision process of the network. While prior work, such as sparse autoencoders, can separate these mixed signals into more meaningful, "monosemantic" features, this typically requires altering the model in ways that can degrade downstream performance. To overcome this, we introduce ELUDe (explicit, lossless, unsupervised disentanglement), a method for improving the interpretability of DNNs while preserving their functional equivalence. ELUDe breaks latent representations into clear, inspectable sub-units that behave like interpretable features, while guaranteeing that the model's outputs remain exactly the same. It requires no explicit training, no labels, and can be applied to pretrained models. ELUDe works by reorganizing how information flows between layers, re-routing concept-specific contributions while preserving the original computation by construction. Across several vision models, including DINOv2 and supervised ViT-B/16, ELUDe improves interpretability, keeps downstream accuracy unchanged, runs efficiently, and supports practical uses such as steering model representations. In short, ELUDe offers interpretability (almost) without a tradeoff: clearer, scalable, and actionable model insights with no loss in performance.
What is Missing? Explaining Neurons Activated by Absent Concepts
Mar 10, 2026Explainable artificial intelligence (XAI) aims to provide human-interpretable insights into the behavior of deep neural networks (DNNs), typically by estimating a simplified causal structure of the model. In existing work, this causal structure often includes relationships where the presence of a concept is associated with a strong activation of a neuron. For example, attribution methods primarily identify input pixels that contribute most to a prediction, and feature visualization methods reveal inputs that cause high activation of a target neuron - the former implicitly assuming that the relevant information resides in the input, and the latter that neurons encode the presence of concepts. However, a largely overlooked type of causal relationship is that of encoded absences, where the absence of a concept increases neural activation. In this work, we show that such missing but relevant concepts are common and that mainstream XAI methods struggle to reveal them when applied in their standard form. To address this, we propose two simple extensions to attribution and feature visualization techniques that uncover encoded absences. Across experiments, we show how mainstream XAI methods can be used to reveal and explain encoded absences, how ImageNet models exploit them, and that debiasing can be improved when considering them.
Evaluating Object-Centric Models beyond Object Discovery
Feb 07, 2026Object-centric learning (OCL) aims to learn structured scene representations that support compositional generalization and robustness to out-of-distribution (OOD) data. However, OCL models are often not evaluated regarding these goals. Instead, most prior work focuses on evaluating OCL models solely through object discovery and simple reasoning tasks, such as probing the representation via image classification. We identify two limitations in existing benchmarks: (1) They provide limited insights on the representation usefulness of OCL models, and (2) localization and representation usefulness are assessed using disjoint metrics. To address (1), we use instruction-tuned VLMs as evaluators, enabling scalable benchmarking across diverse VQA datasets to measure how well VLMs leverage OCL representations for complex reasoning tasks. To address (2), we introduce a unified evaluation task and metric that jointly assess localization (where) and representation usefulness (what), thereby eliminating inconsistencies introduced by disjoint evaluation. Finally, we include a simple multi-feature reconstruction baseline as a reference point.
MUFASA: A Multi-Layer Framework for Slot Attention
Feb 07, 2026Unsupervised object-centric learning (OCL) decomposes visual scenes into distinct entities. Slot attention is a popular approach that represents individual objects as latent vectors, called slots. Current methods obtain these slot representations solely from the last layer of a pre-trained vision transformer (ViT), ignoring valuable, semantically rich information encoded across the other layers. To better utilize this latent semantic information, we introduce MUFASA, a lightweight plug-and-play framework for slot attention-based approaches to unsupervised object segmentation. Our model computes slot attention across multiple feature layers of the ViT encoder, fully leveraging their semantic richness. We propose a fusion strategy to aggregate slots obtained on multiple layers into a unified object-centric representation. Integrating MUFASA into existing OCL methods improves their segmentation results across multiple datasets, setting a new state of the art while simultaneously improving training convergence with only minor inference overhead.
Efficient Masked Attention Transformer for Few-Shot Classification and Segmentation
Jul 31, 2025Few-shot classification and segmentation (FS-CS) focuses on jointly performing multi-label classification and multi-class segmentation using few annotated examples. Although the current state of the art (SOTA) achieves high accuracy in both tasks, it struggles with small objects. To overcome this, we propose the Efficient Masked Attention Transformer (EMAT), which improves classification and segmentation accuracy, especially for small objects. EMAT introduces three modifications: a novel memory-efficient masked attention mechanism, a learnable downscaling strategy, and parameter-efficiency enhancements. EMAT outperforms all FS-CS methods on the PASCAL-5$^i$ and COCO-20$^i$ datasets, using at least four times fewer trainable parameters. Moreover, as the current FS-CS evaluation setting discards available annotations, despite their costly collection, we introduce two novel evaluation settings that consider these annotations to better reflect practical scenarios.
Disentangling Polysemantic Channels in Convolutional Neural Networks
Apr 17, 2025Mechanistic interpretability is concerned with analyzing individual components in a (convolutional) neural network (CNN) and how they form larger circuits representing decision mechanisms. These investigations are challenging since CNNs frequently learn polysemantic channels that encode distinct concepts, making them hard to interpret. To address this, we propose an algorithm to disentangle a specific kind of polysemantic channel into multiple channels, each responding to a single concept. Our approach restructures weights in a CNN, utilizing that different concepts within the same channel exhibit distinct activation patterns in the previous layer. By disentangling these polysemantic features, we enhance the interpretability of CNNs, ultimately improving explanatory techniques such as feature visualizations.
Knowledge Distillation for Multimodal Egocentric Action Recognition Robust to Missing Modalities
Apr 11, 2025Action recognition is an essential task in egocentric vision due to its wide range of applications across many fields. While deep learning methods have been proposed to address this task, most rely on a single modality, typically video. However, including additional modalities may improve the robustness of the approaches to common issues in egocentric videos, such as blurriness and occlusions. Recent efforts in multimodal egocentric action recognition often assume the availability of all modalities, leading to failures or performance drops when any modality is missing. To address this, we introduce an efficient multimodal knowledge distillation approach for egocentric action recognition that is robust to missing modalities (KARMMA) while still benefiting when multiple modalities are available. Our method focuses on resource-efficient development by leveraging pre-trained models as unimodal feature extractors in our teacher model, which distills knowledge into a much smaller and faster student model. Experiments on the Epic-Kitchens and Something-Something datasets demonstrate that our student model effectively handles missing modalities while reducing its accuracy drop in this scenario.
Boosting Omnidirectional Stereo Matching with a Pre-trained Depth Foundation Model
Mar 30, 2025Omnidirectional depth perception is essential for mobile robotics applications that require scene understanding across a full 360{\deg} field of view. Camera-based setups offer a cost-effective option by using stereo depth estimation to generate dense, high-resolution depth maps without relying on expensive active sensing. However, existing omnidirectional stereo matching approaches achieve only limited depth accuracy across diverse environments, depth ranges, and lighting conditions, due to the scarcity of real-world data. We present DFI-OmniStereo, a novel omnidirectional stereo matching method that leverages a large-scale pre-trained foundation model for relative monocular depth estimation within an iterative optimization-based stereo matching architecture. We introduce a dedicated two-stage training strategy to utilize the relative monocular depth features for our omnidirectional stereo matching before scale-invariant fine-tuning. DFI-OmniStereo achieves state-of-the-art results on the real-world Helvipad dataset, reducing disparity MAE by approximately 16% compared to the previous best omnidirectional stereo method.
Beyond Accuracy: What Matters in Designing Well-Behaved Models?
Mar 21, 2025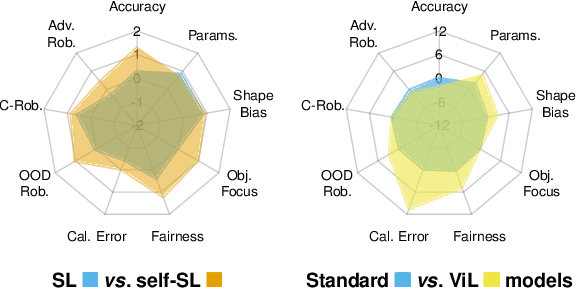

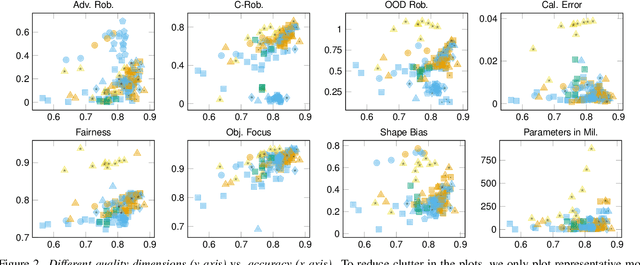
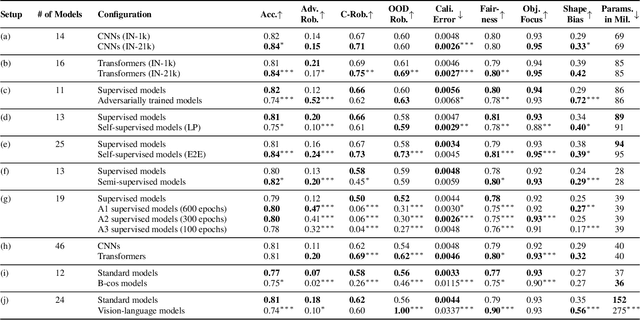
Deep learning has become an essential part of computer vision, with deep neural networks (DNNs) excelling in predictive performance. However, they often fall short in other critical quality dimensions, such as robustness, calibration, or fairness. While existing studies have focused on a subset of these quality dimensions, none have explored a more general form of "well-behavedness" of DNNs. With this work, we address this gap by simultaneously studying nine different quality dimensions for image classification. Through a large-scale study, we provide a bird's-eye view by analyzing 326 backbone models and how different training paradigms and model architectures affect the quality dimensions. We reveal various new insights such that (i) vision-language models exhibit high fairness on ImageNet-1k classification and strong robustness against domain changes; (ii) self-supervised learning is an effective training paradigm to improve almost all considered quality dimensions; and (iii) the training dataset size is a major driver for most of the quality dimensions. We conclude our study by introducing the QUBA score (Quality Understanding Beyond Accuracy), a novel metric that ranks models across multiple dimensions of quality, enabling tailored recommendations based on specific user needs.
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.