 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAGen: Diverse Image Augmentation with Generative Models
Paper and Code

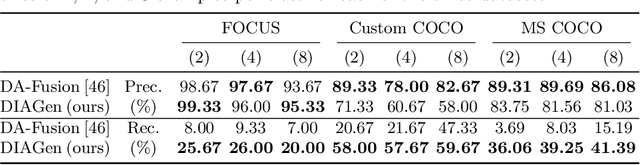
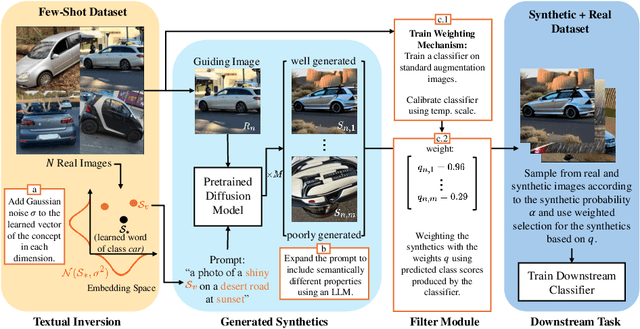
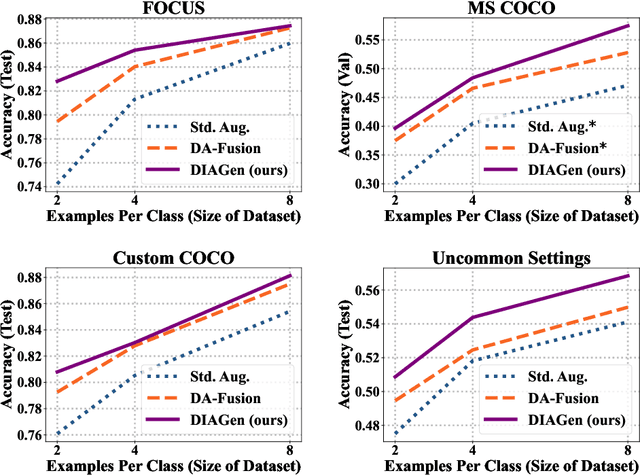
Simple data augmentation techniques, such as rotations and flips, are widely used to enhance the generalization power of computer vision models. However, these techniques often fail to modify high-level semantic attributes of a class. To address this limitation, researchers have explored generative augmentation methods like the recently proposed DA-Fusion. Despite some progress, the variations are still largely limited to textural changes, thus falling short on aspects like varied viewpoints, environment, weather conditions, or even class-level semantic attributes (eg, variations in a dog's breed). To overcome this challenge, we propose DIAGen, building upon DA-Fusion. First, we apply Gaussian noise to the embeddings of an object learned with Textual Inversion to diversify generations using a pre-trained diffusion model's knowledge. Second, we exploit the general knowledge of a text-to-text generative model to guide the image generation of the diffusion model with varied class-specific prompts. Finally, we introduce a weighting mechanism to mitigate the impact of poorly generated samples. Experimental results across various datasets show that DIAGen not only enhances semantic diversity but also improves the performance of subsequent classifiers. The advantages of DIAGen over standard augmentations and the DA-Fusion baseline are particularly pronounced with out-of-distribution samples.