 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAGen: Diverse Image Augmentation with Generative Models
Aug 26, 2024
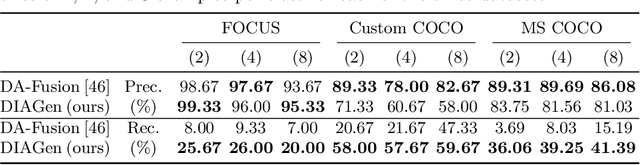
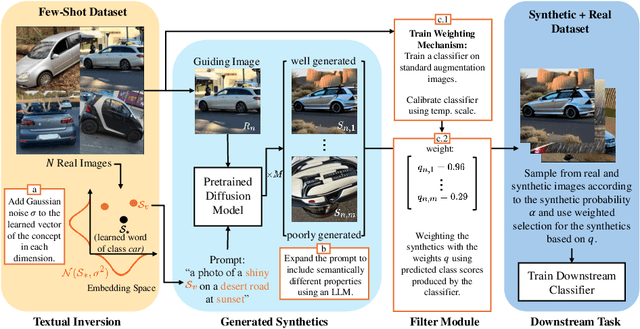
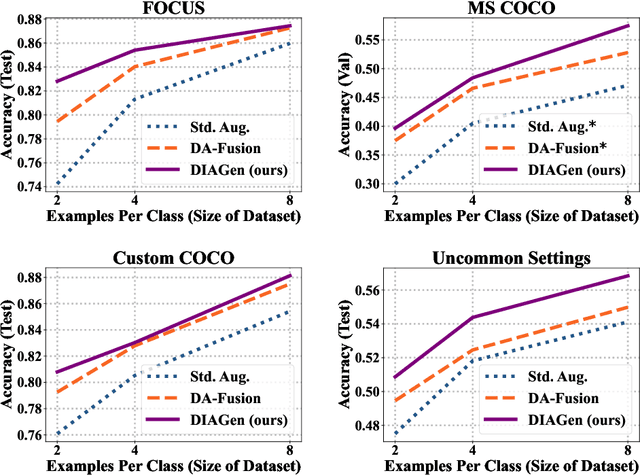
Simple data augmentation techniques, such as rotations and flips, are widely used to enhance the generalization power of computer vision models. However, these techniques often fail to modify high-level semantic attributes of a class. To address this limitation, researchers have explored generative augmentation methods like the recently proposed DA-Fusion. Despite some progress, the variations are still largely limited to textural changes, thus falling short on aspects like varied viewpoints, environment, weather conditions, or even class-level semantic attributes (eg, variations in a dog's breed). To overcome this challenge, we propose DIAGen, building upon DA-Fusion. First, we apply Gaussian noise to the embeddings of an object learned with Textual Inversion to diversify generations using a pre-trained diffusion model's knowledge. Second, we exploit the general knowledge of a text-to-text generative model to guide the image generation of the diffusion model with varied class-specific prompts. Finally, we introduce a weighting mechanism to mitigate the impact of poorly generated samples. Experimental results across various datasets show that DIAGen not only enhances semantic diversity but also improves the performance of subsequent classifiers. The advantages of DIAGen over standard augmentations and the DA-Fusion baseline are particularly pronounced with out-of-distribution samples.
DeiSAM: Segment Anything with Deictic Prompting
Feb 21, 2024
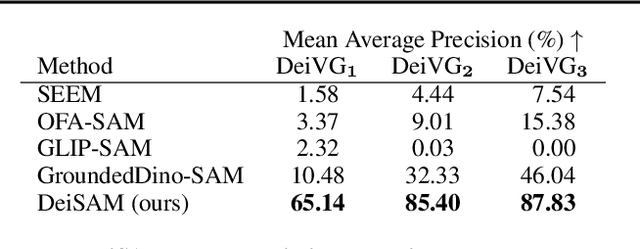


Large-scale, pre-trained neural networks have demonstrated strong capabilities in various tasks, including zero-shot image segmentation. To identify concrete objects in complex scenes, humans instinctively rely on deictic descriptions in natural language, i.e., referring to something depending on the context such as "The object that is on the desk and behind the cup.". However, deep learning approaches cannot reliably interpret such deictic representations due to their lack of reasoning capabilities in complex scenarios. To remedy this issue, we propose DeiSAM -- a combination of large pre-trained neural networks with differentiable logic reasoners -- for deictic promptable segmentation. Given a complex, textual segmentation description, DeiSAM leverages Large Language Models (LLMs) to generate first-order logic rules and performs differentiable forward reasoning on generated scene graphs. Subsequently, DeiSAM segments objects by matching them to the logically inferred image regions. As part of our evaluation, we propose the Deictic Visual Genome (DeiVG) dataset, containing paired visual input and complex, deictic textual prompts. Our empirical results demonstrate that DeiSAM is a substantial improvement over purely data-driven baselines for deictic promptable segmentation.
From Images to Connections: Can DQN with GNNs learn the Strategic Game of Hex?
Nov 22, 2023



The gameplay of strategic board games such as chess, Go and Hex is often characterized by combinatorial, relational structures -- capturing distinct interactions and non-local patterns -- and not just images. Nonetheless, most common self-play reinforcement learning (RL) approaches simply approximate policy and value functions using convolutional neural networks (CNN). A key feature of CNNs is their relational inductive bias towards locality and translational invariance. In contrast, graph neural networks (GNN) can encode more complicated and distinct relational structures. Hence, we investigate the crucial question: Can GNNs, with their ability to encode complex connections, replace CNNs in self-play reinforcement learning? To this end, we do a comparison with Hex -- an abstract yet strategically rich board game -- serving as our experimental platform. Our findings reveal that GNNs excel at dealing with long range dependency situations in game states and are less prone to overfitting, but also showing a reduced proficiency in discerning local patterns. This suggests a potential paradigm shift, signaling the use of game-specific structures to reshape self-play reinforcement learning.
Vision Relation Transformer for Unbiased Scene Graph Generation
Aug 18, 2023



Recent years have seen a growing interest in Scene Graph Generation (SGG), a comprehensive visual scene understanding task that aims to predict entity relationships using a relation encoder-decoder pipeline stacked on top of an object encoder-decoder backbone. Unfortunately, current SGG methods suffer from an information loss regarding the entities local-level cues during the relation encoding process. To mitigate this, we introduce the Vision rElation TransfOrmer (VETO), consisting of a novel local-level entity relation encoder. We further observe that many existing SGG methods claim to be unbiased, but are still biased towards either head or tail classes. To overcome this bias, we introduce a Mutually Exclusive ExperT (MEET) learning strategy that captures important relation features without bias towards head or tail classes. Experimental results on the VG and GQA datasets demonstrate that VETO + MEET boosts the predictive performance by up to 47 percentage over the state of the art while being 10 times smaller.