 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARCO: Navigating the Unseen Space of Semantic Correspondence
Apr 20, 2026Recent advances in semantic correspondence rely on dual-encoder architectures, combining DINOv2 with diffusion backbones. While accurate, these billion-parameter models generalize poorly beyond training keypoints, revealing a gap between benchmark performance and real-world usability, where queried points rarely match those seen during training. Building upon DINOv2, we introduce MARCO, a unified model for generalizable correspondence driven by a novel training framework that enhances both fine-grained localization and semantic generalization. By coupling a coarse-to-fine objective that refines spatial precision with a self-distillation framework, which expands sparse supervision beyond annotated regions, our approach transforms a handful of keypoints into dense, semantically coherent correspondences. MARCO sets a new state of the art on SPair-71k, AP-10K, and PF-PASCAL, with gains that amplify at fine-grained localization thresholds (+8.9 PCK@0.01), strongest generalization to unseen keypoints (+5.1, SPair-U) and categories (+4.7, MP-100), while remaining 3x smaller and 10x faster than diffusion-based approaches. Code is available at https://github.com/visinf/MARCO .
INSID3: Training-Free In-Context Segmentation with DINOv3
Mar 30, 2026In-context segmentation (ICS) aims to segment arbitrary concepts, e.g., objects, parts, or personalized instances, given one annotated visual examples. Existing work relies on (i) fine-tuning vision foundation models (VFMs), which improves in-domain results but harms generalization, or (ii) combines multiple frozen VFMs, which preserves generalization but yields architectural complexity and fixed segmentation granularities. We revisit ICS from a minimalist perspective and ask: Can a single self-supervised backbone support both semantic matching and segmentation, without any supervision or auxiliary models? We show that scaled-up dense self-supervised features from DINOv3 exhibit strong spatial structure and semantic correspondence. We introduce INSID3, a training-free approach that segments concepts at varying granularities only from frozen DINOv3 features, given an in-context example. INSID3 achieves state-of-the-art results across one-shot semantic, part, and personalized segmentation, outperforming previous work by +7.5 % mIoU, while using 3x fewer parameters and without any mask or category-level supervision. Code is available at https://github.com/visinf/INSID3 .
What is Missing? Explaining Neurons Activated by Absent Concepts
Mar 10, 2026Explainable artificial intelligence (XAI) aims to provide human-interpretable insights into the behavior of deep neural networks (DNNs), typically by estimating a simplified causal structure of the model. In existing work, this causal structure often includes relationships where the presence of a concept is associated with a strong activation of a neuron. For example, attribution methods primarily identify input pixels that contribute most to a prediction, and feature visualization methods reveal inputs that cause high activation of a target neuron - the former implicitly assuming that the relevant information resides in the input, and the latter that neurons encode the presence of concepts. However, a largely overlooked type of causal relationship is that of encoded absences, where the absence of a concept increases neural activation. In this work, we show that such missing but relevant concepts are common and that mainstream XAI methods struggle to reveal them when applied in their standard form. To address this, we propose two simple extensions to attribution and feature visualization techniques that uncover encoded absences. Across experiments, we show how mainstream XAI methods can be used to reveal and explain encoded absences, how ImageNet models exploit them, and that debiasing can be improved when considering them.
MUFASA: A Multi-Layer Framework for Slot Attention
Feb 07, 2026Unsupervised object-centric learning (OCL) decomposes visual scenes into distinct entities. Slot attention is a popular approach that represents individual objects as latent vectors, called slots. Current methods obtain these slot representations solely from the last layer of a pre-trained vision transformer (ViT), ignoring valuable, semantically rich information encoded across the other layers. To better utilize this latent semantic information, we introduce MUFASA, a lightweight plug-and-play framework for slot attention-based approaches to unsupervised object segmentation. Our model computes slot attention across multiple feature layers of the ViT encoder, fully leveraging their semantic richness. We propose a fusion strategy to aggregate slots obtained on multiple layers into a unified object-centric representation. Integrating MUFASA into existing OCL methods improves their segmentation results across multiple datasets, setting a new state of the art while simultaneously improving training convergence with only minor inference overhead.
Evaluating Object-Centric Models beyond Object Discovery
Feb 07, 2026Object-centric learning (OCL) aims to learn structured scene representations that support compositional generalization and robustness to out-of-distribution (OOD) data. However, OCL models are often not evaluated regarding these goals. Instead, most prior work focuses on evaluating OCL models solely through object discovery and simple reasoning tasks, such as probing the representation via image classification. We identify two limitations in existing benchmarks: (1) They provide limited insights on the representation usefulness of OCL models, and (2) localization and representation usefulness are assessed using disjoint metrics. To address (1), we use instruction-tuned VLMs as evaluators, enabling scalable benchmarking across diverse VQA datasets to measure how well VLMs leverage OCL representations for complex reasoning tasks. To address (2), we introduce a unified evaluation task and metric that jointly assess localization (where) and representation usefulness (what), thereby eliminating inconsistencies introduced by disjoint evaluation. Finally, we include a simple multi-feature reconstruction baseline as a reference point.
Hardware-Efficient Cognitive Radar: Multi-Target Detection with RL-Driven Transmissive RIS
Sep 17, 2025Cognitive radar has emerged as a key paradigm for next-generation sensing, enabling adaptive, intelligent operation in dynamic and complex environments. Yet, conventional cognitive multiple-input multiple-output (MIMO) radars offer strong detection performance but suffer from high hardware complexity and power demands. To overcome these limitations, we develop a reinforcement learning (RL)-based framework that leverages a transmissive reconfigurable intelligent surface (TRIS) for adaptive beamforming. A state-action-reward-state-action (SARSA) agent tunes TRIS phase shifts to improve multi-target detection in low signal-to-noise ratio (SNR) conditions while operating with far fewer radio frequency (RF) chains. Simulations confirm that the proposed TRIS-RL radar matches or, for large number of elements, even surpasses MIMO performance with reduced cost and energy requirements.
Activation Subspaces for Out-of-Distribution Detection
Aug 29, 2025To ensure the reliability of deep models in real-world applications, out-of-distribution (OOD) detection methods aim to distinguish samples close to the training distribution (in-distribution, ID) from those farther away (OOD). In this work, we propose a novel OOD detection method that utilizes singular value decomposition of the weight matrix of the classification head to decompose the model's activations into decisive and insignificant components, which contribute maximally, respectively minimally, to the final classifier output. We find that the subspace of insignificant components more effectively distinguishes ID from OOD data than raw activations in regimes of large distribution shifts (Far-OOD). This occurs because the classification objective leaves the insignificant subspace largely unaffected, yielding features that are ''untainted'' by the target classification task. Conversely, in regimes of smaller distribution shifts (Near-OOD), we find that activation shaping methods profit from only considering the decisive subspace, as the insignificant component can cause interference in the activation space. By combining two findings into a single approach, termed ActSub, we achieve state-of-the-art results in various standard OOD benchmarks.
Efficient Masked Attention Transformer for Few-Shot Classification and Segmentation
Jul 31, 2025Few-shot classification and segmentation (FS-CS) focuses on jointly performing multi-label classification and multi-class segmentation using few annotated examples. Although the current state of the art (SOTA) achieves high accuracy in both tasks, it struggles with small objects. To overcome this, we propose the Efficient Masked Attention Transformer (EMAT), which improves classification and segmentation accuracy, especially for small objects. EMAT introduces three modifications: a novel memory-efficient masked attention mechanism, a learnable downscaling strategy, and parameter-efficiency enhancements. EMAT outperforms all FS-CS methods on the PASCAL-5$^i$ and COCO-20$^i$ datasets, using at least four times fewer trainable parameters. Moreover, as the current FS-CS evaluation setting discards available annotations, despite their costly collection, we introduce two novel evaluation settings that consider these annotations to better reflect practical scenarios.
Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion
Jul 08, 2025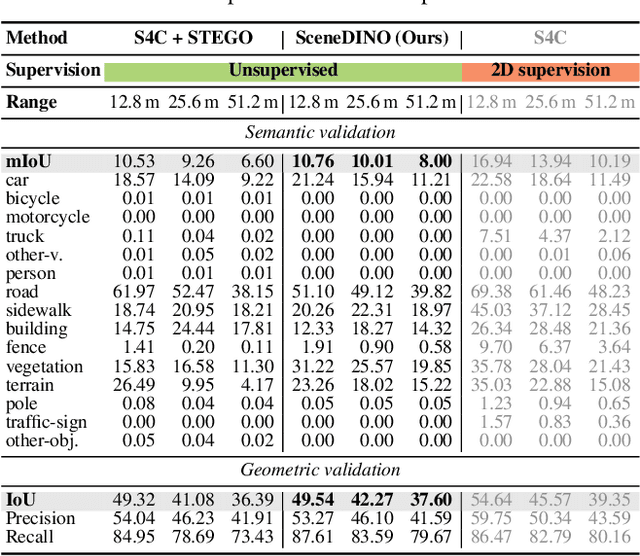
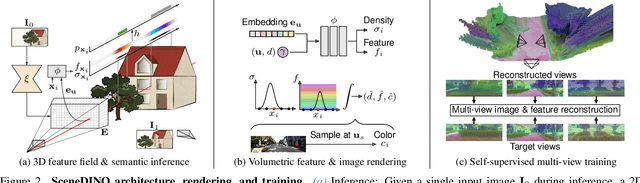

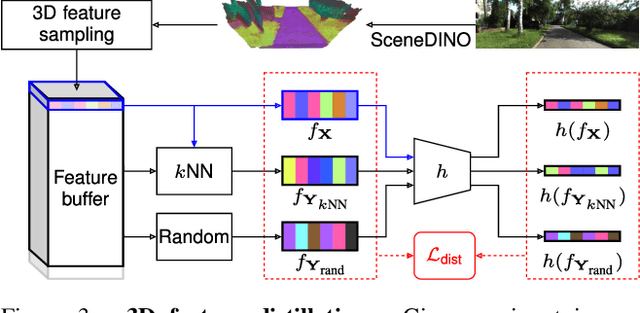
Semantic scene completion (SSC) aims to infer both the 3D geometry and semantics of a scene from single images. In contrast to prior work on SSC that heavily relies on expensive ground-truth annotations, we approach SSC in an unsupervised setting. Our novel method, SceneDINO, adapts techniques from self-supervised representation learning and 2D unsupervised scene understanding to SSC. Our training exclusively utilizes multi-view consistency self-supervision without any form of semantic or geometric ground truth. Given a single input image, SceneDINO infers the 3D geometry and expressive 3D DINO features in a feed-forward manner. Through a novel 3D feature distillation approach, we obtain unsupervised 3D semantics. In both 3D and 2D unsupervised scene understanding, SceneDINO reaches state-of-the-art segmentation accuracy. Linear probing our 3D features matches the segmentation accuracy of a current supervised SSC approach. Additionally, we showcase the domain generalization and multi-view consistency of SceneDINO, taking the first steps towards a strong foundation for single image 3D scene understanding.
Anomaly Detection for Sensing Security
Jun 12, 2025Various approaches in the field of physical layer security involve anomaly detection, such as physical layer authentication, sensing attacks, and anti-tampering solutions. Depending on the context in which these approaches are applied, anomaly detection needs to be computationally lightweight, resilient to changes in temperature and environment, and robust against phase noise. We adapt moving average filters, autoregression filters and Kalman filters to provide predictions of feature vectors that fulfill the above criteria. Different hypothesis test designs are employed that allow omnidirectional and unidirectional outlier detection. In a case study, a sensing attack is investigated that employs the described algorithms with various channel features based on commodity WiFi devices. Thereby, various combinations of algorithms and channel features show effectiveness for motion detection by an attacker. Countermeasures only utilizing transmit power randomization are shown insufficient to mitigate such attacks if the attacker has access to channel state information (CSI) measurements, suggesting that mitigation solutions might require frequency-variant randomization.