 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Latent Slot Diffusion for Object-Centric Learning
Jul 25, 2024Slot attention aims to decompose an input image into a set of meaningful object files (slots). These latent object representations enable various downstream tasks. Yet, these slots often bind to object parts, not objects themselves, especially for real-world datasets. To address this, we introduce Guided Latent Slot Diffusion - GLASS, an object-centric model that uses generated captions as a guiding signal to better align slots with objects. Our key insight is to learn the slot-attention module in the space of generated images. This allows us to repurpose the pre-trained diffusion decoder model, which reconstructs the images from the slots, as a semantic mask generator based on the generated captions. GLASS learns an object-level representation suitable for multiple tasks simultaneously, e.g., segmentation, image generation, and property prediction, outperforming previous methods. For object discovery, GLASS achieves approx. a +35% and +10% relative improvement for mIoU over the previous state-of-the-art (SOTA) method on the VOC and COCO datasets, respectively, and establishes a new SOTA FID score for conditional image generation amongst slot-attention-based methods. For the segmentation task, GLASS surpasses SOTA weakly-supervised and language-based segmentation models, which were specifically designed for the task.
Is Synthetic Data all We Need? Benchmarking the Robustness of Models Trained with Synthetic Images
May 30, 2024
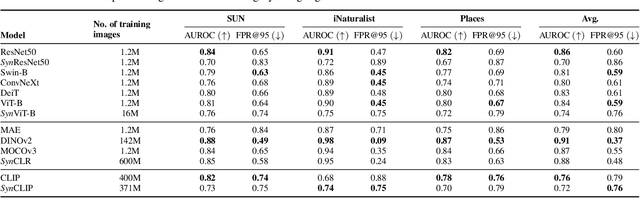
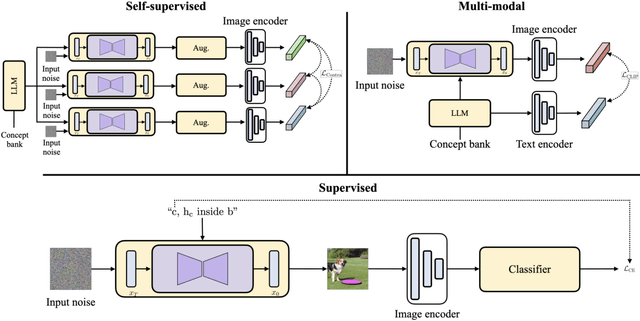
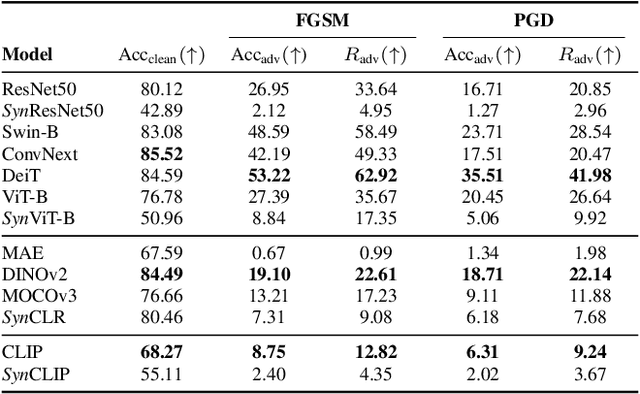
A long-standing challenge in developing machine learning approaches has been the lack of high-quality labeled data. Recently, models trained with purely synthetic data, here termed synthetic clones, generated using large-scale pre-trained diffusion models have shown promising results in overcoming this annotation bottleneck. As these synthetic clone models progress, they are likely to be deployed in challenging real-world settings, yet their suitability remains understudied. Our work addresses this gap by providing the first benchmark for three classes of synthetic clone models, namely supervised, self-supervised, and multi-modal ones, across a range of robustness measures. We show that existing synthetic self-supervised and multi-modal clones are comparable to or outperform state-of-the-art real-image baselines for a range of robustness metrics - shape bias, background bias, calibration, etc. However, we also find that synthetic clones are much more susceptible to adversarial and real-world noise than models trained with real data. To address this, we find that combining both real and synthetic data further increases the robustness, and that the choice of prompt used for generating synthetic images plays an important part in the robustness of synthetic clones.
$S^2$-Flow: Joint Semantic and Style Editing of Facial Images
Nov 22, 2022The high-quality images yielded by generative adversarial networks (GANs) have motivated investigations into their application for image editing. However, GANs are often limited in the control they provide for performing specific edits. One of the principal challenges is the entangled latent space of GANs, which is not directly suitable for performing independent and detailed edits. Recent editing methods allow for either controlled style edits or controlled semantic edits. In addition, methods that use semantic masks to edit images have difficulty preserving the identity and are unable to perform controlled style edits. We propose a method to disentangle a GAN$\text{'}$s latent space into semantic and style spaces, enabling controlled semantic and style edits for face images independently within the same framework. To achieve this, we design an encoder-decoder based network architecture ($S^2$-Flow), which incorporates two proposed inductive biases. We show the suitability of $S^2$-Flow quantitatively and qualitatively by performing various semantic and style edits.
Submodular Batch Selection for Training Deep Neural Networks
Jun 20, 2019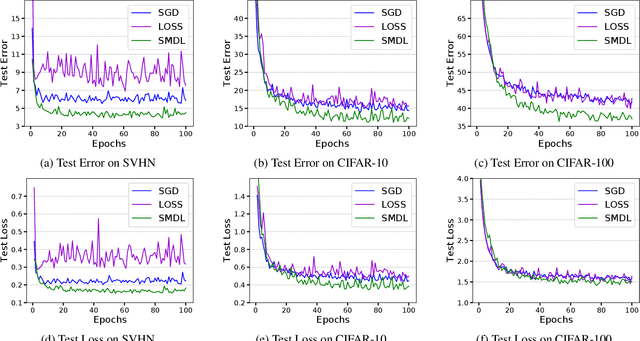


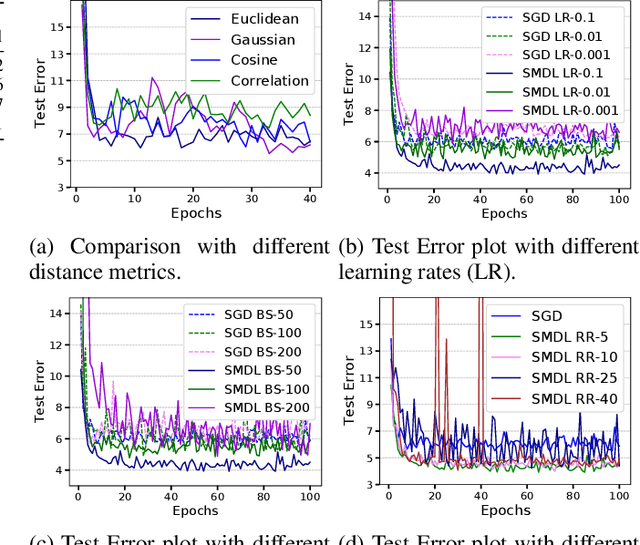
Mini-batch gradient descent based methods are the de facto algorithms for training neural network architectures today. We introduce a mini-batch selection strategy based on submodular function maximization. Our novel submodular formulation captures the informativeness of each sample and diversity of the whole subset. We design an efficient, greedy algorithm which can give high-quality solutions to this NP-hard combinatorial optimization problem. Our extensive experiments on standard datasets show that the deep models trained using the proposed batch selection strategy provide better generalization than Stochastic Gradient Descent as well as a popular baseline sampling strategy across different learning rates, batch sizes, and distance metrics.