 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Synthetic Data all We Need? Benchmarking the Robustness of Models Trained with Synthetic Images
May 30, 2024
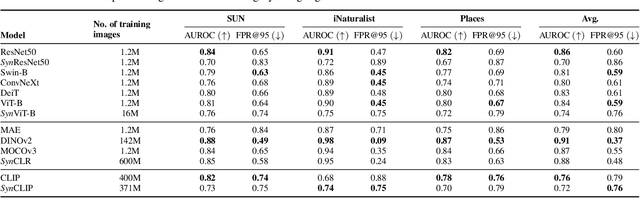
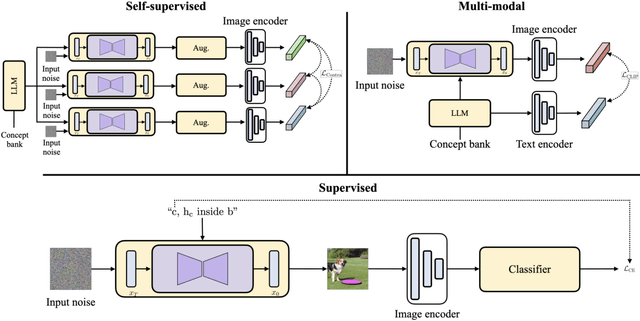
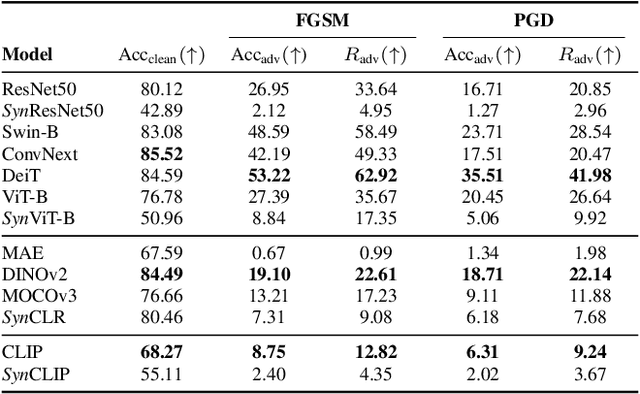
A long-standing challenge in developing machine learning approaches has been the lack of high-quality labeled data. Recently, models trained with purely synthetic data, here termed synthetic clones, generated using large-scale pre-trained diffusion models have shown promising results in overcoming this annotation bottleneck. As these synthetic clone models progress, they are likely to be deployed in challenging real-world settings, yet their suitability remains understudied. Our work addresses this gap by providing the first benchmark for three classes of synthetic clone models, namely supervised, self-supervised, and multi-modal ones, across a range of robustness measures. We show that existing synthetic self-supervised and multi-modal clones are comparable to or outperform state-of-the-art real-image baselines for a range of robustness metrics - shape bias, background bias, calibration, etc. However, we also find that synthetic clones are much more susceptible to adversarial and real-world noise than models trained with real data. To address this, we find that combining both real and synthetic data further increases the robustness, and that the choice of prompt used for generating synthetic images plays an important part in the robustness of synthetic clones.
DP-NMT: Scalable Differentially-Private Machine Translation
Nov 24, 2023Neural machine translation (NMT) is a widely popular text generation task, yet there is a considerable research gap in the development of privacy-preserving NMT models, despite significant data privacy concerns for NMT systems. Differentially private stochastic gradient descent (DP-SGD) is a popular method for training machine learning models with concrete privacy guarantees; however, the implementation specifics of training a model with DP-SGD are not always clarified in existing models, with differing software libraries used and code bases not always being public, leading to reproducibility issues. To tackle this, we introduce DP-NMT, an open-source framework for carrying out research on privacy-preserving NMT with DP-SGD, bringing together numerous models, datasets, and evaluation metrics in one systematic software package. Our goal is to provide a platform for researchers to advance the development of privacy-preserving NMT systems, keeping the specific details of the DP-SGD algorithm transparent and intuitive to implement. We run a set of experiments on datasets from both general and privacy-related domains to demonstrate our framework in use. We make our framework publicly available and welcome feedback from the community.