 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoetry in Pixels: Prompt Tuning for Poem Image Generation via Diffusion Models
Jan 10, 2025



The task of text-to-image generation has encountered significant challenges when applied to literary works, especially poetry. Poems are a distinct form of literature, with meanings that frequently transcend beyond the literal words. To address this shortcoming, we propose a PoemToPixel framework designed to generate images that visually represent the inherent meanings of poems. Our approach incorporates the concept of prompt tuning in our image generation framework to ensure that the resulting images closely align with the poetic content. In addition, we propose the PoeKey algorithm, which extracts three key elements in the form of emotions, visual elements, and themes from poems to form instructions which are subsequently provided to a diffusion model for generating corresponding images. Furthermore, to expand the diversity of the poetry dataset across different genres and ages, we introduce MiniPo, a novel multimodal dataset comprising 1001 children's poems and images. Leveraging this dataset alongside PoemSum, we conducted both quantitative and qualitative evaluations of image generation using our PoemToPixel framework. This paper demonstrates the effectiveness of our approach and offers a fresh perspective on generating images from literary sources.
Grounding Descriptions in Images informs Zero-Shot Visual Recognition
Dec 05, 2024



Vision-language models (VLMs) like CLIP have been cherished for their ability to perform zero-shot visual recognition on open-vocabulary concepts. This is achieved by selecting the object category whose textual representation bears the highest similarity with the query image. While successful in some domains, this method struggles with identifying fine-grained entities as well as generalizing to unseen concepts that are not captured by the training distribution. Recent works attempt to mitigate these challenges by integrating category descriptions at test time, albeit yielding modest improvements. We attribute these limited gains to a fundamental misalignment between image and description representations, which is rooted in the pretraining structure of CLIP. In this paper, we propose GRAIN, a new pretraining strategy aimed at aligning representations at both fine and coarse levels simultaneously. Our approach learns to jointly ground textual descriptions in image regions along with aligning overarching captions with global image representations. To drive this pre-training, we leverage frozen Multimodal Large Language Models (MLLMs) to derive large-scale synthetic annotations. We demonstrate the enhanced zero-shot performance of our model compared to current state-of-the art methods across 11 diverse image classification datasets. Additionally, we introduce Products-2023, a newly curated, manually labeled dataset featuring novel concepts, and showcase our model's ability to recognize these concepts by benchmarking on it. Significant improvements achieved by our model on other downstream tasks like retrieval further highlight the superior quality of representations learned by our approach. Code available at https://github.com/shaunak27/grain-clip .
Design-o-meter: Towards Evaluating and Refining Graphic Designs
Nov 22, 2024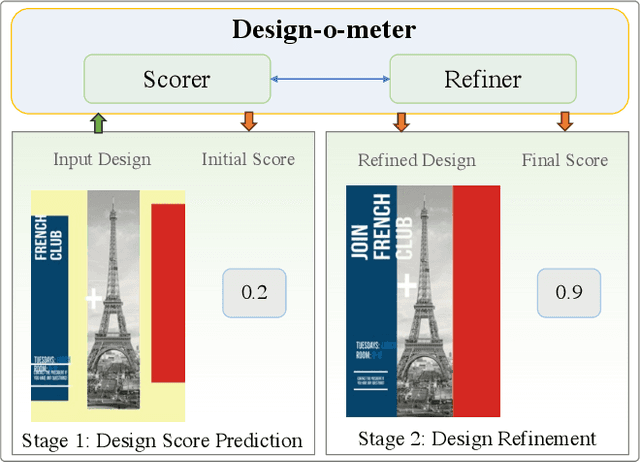
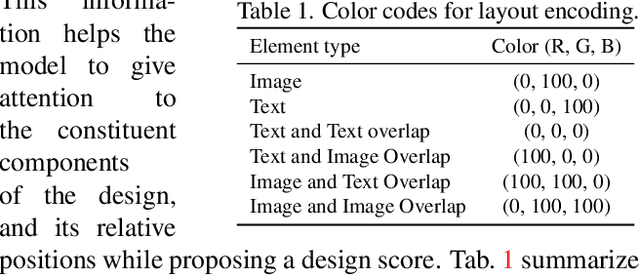
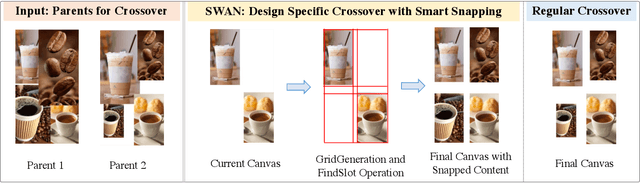
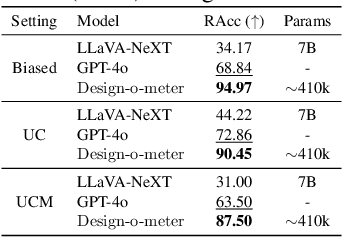
Graphic designs are an effective medium for visual communication. They range from greeting cards to corporate flyers and beyond. Off-late, machine learning techniques are able to generate such designs, which accelerates the rate of content production. An automated way of evaluating their quality becomes critical. Towards this end, we introduce Design-o-meter, a data-driven methodology to quantify the goodness of graphic designs. Further, our approach can suggest modifications to these designs to improve its visual appeal. To the best of our knowledge, Design-o-meter is the first approach that scores and refines designs in a unified framework despite the inherent subjectivity and ambiguity of the setting. Our exhaustive quantitative and qualitative analysis of our approach against baselines adapted for the task (including recent Multimodal LLM-based approaches) brings out the efficacy of our methodology. We hope our work will usher more interest in this important and pragmatic problem setting.
MeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models
Jun 07, 2024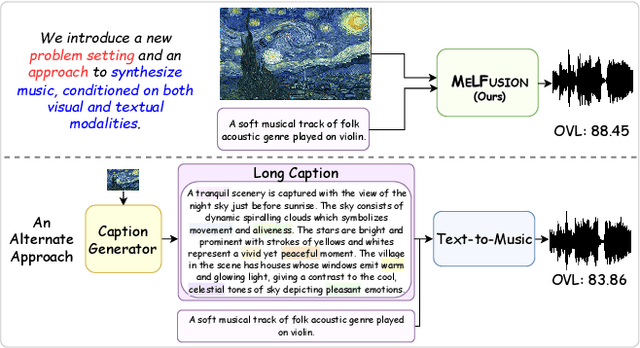
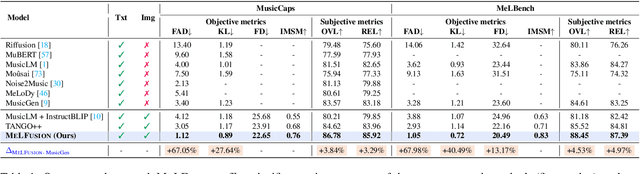
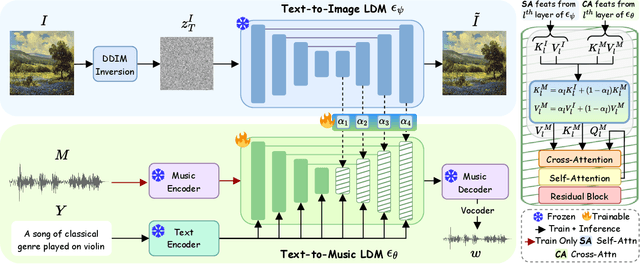
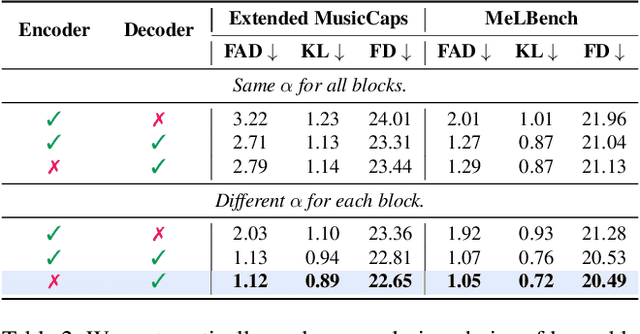
Music is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel "visual synapse", which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area.
Iterative Multi-granular Image Editing using Diffusion Models
Sep 01, 2023



Recent advances in text-guided image synthesis has dramatically changed how creative professionals generate artistic and aesthetically pleasing visual assets. To fully support such creative endeavors, the process should possess the ability to: 1) iteratively edit the generations and 2) control the spatial reach of desired changes (global, local or anything in between). We formalize this pragmatic problem setting as Iterative Multi-granular Editing. While there has been substantial progress with diffusion-based models for image synthesis and editing, they are all one shot (i.e., no iterative editing capabilities) and do not naturally yield multi-granular control (i.e., covering the full spectrum of local-to-global edits). To overcome these drawbacks, we propose EMILIE: Iterative Multi-granular Image Editor. EMILIE introduces a novel latent iteration strategy, which re-purposes a pre-trained diffusion model to facilitate iterative editing. This is complemented by a gradient control operation for multi-granular control. We introduce a new benchmark dataset to evaluate our newly proposed setting. We conduct exhaustive quantitatively and qualitatively evaluation against recent state-of-the-art approaches adapted to our task, to being out the mettle of EMILIE. We hope our work would attract attention to this newly identified, pragmatic problem setting.
A-STAR: Test-time Attention Segregation and Retention for Text-to-image Synthesis
Jun 26, 2023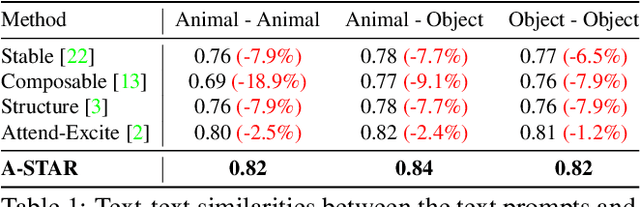
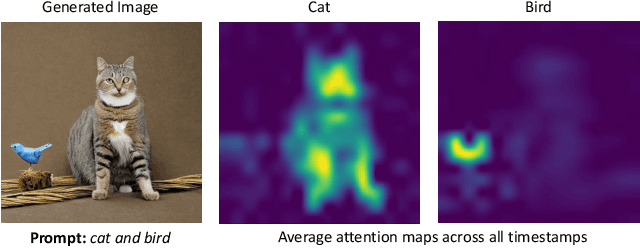
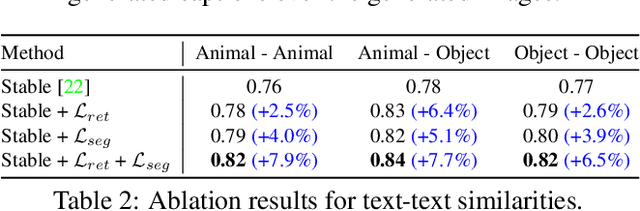

While recent developments in text-to-image generative models have led to a suite of high-performing methods capable of producing creative imagery from free-form text, there are several limitations. By analyzing the cross-attention representations of these models, we notice two key issues. First, for text prompts that contain multiple concepts, there is a significant amount of pixel-space overlap (i.e., same spatial regions) among pairs of different concepts. This eventually leads to the model being unable to distinguish between the two concepts and one of them being ignored in the final generation. Next, while these models attempt to capture all such concepts during the beginning of denoising (e.g., first few steps) as evidenced by cross-attention maps, this knowledge is not retained by the end of denoising (e.g., last few steps). Such loss of knowledge eventually leads to inaccurate generation outputs. To address these issues, our key innovations include two test-time attention-based loss functions that substantially improve the performance of pretrained baseline text-to-image diffusion models. First, our attention segregation loss reduces the cross-attention overlap between attention maps of different concepts in the text prompt, thereby reducing the confusion/conflict among various concepts and the eventual capture of all concepts in the generated output. Next, our attention retention loss explicitly forces text-to-image diffusion models to retain cross-attention information for all concepts across all denoising time steps, thereby leading to reduced information loss and the preservation of all concepts in the generated output.
$Δ$-Networks for Efficient Model Patching
Mar 26, 2023Models pre-trained on large-scale datasets are often finetuned to support newer tasks and datasets that arrive over time. This process necessitates storing copies of the model over time for each task that the pre-trained model is finetuned to. Building on top of recent model patching work, we propose $\Delta$-Patching for finetuning neural network models in an efficient manner, without the need to store model copies. We propose a simple and lightweight method called $\Delta$-Networks to achieve this objective. Our comprehensive experiments across setting and architecture variants show that $\Delta$-Networks outperform earlier model patching work while only requiring a fraction of parameters to be trained. We also show that this approach can be used for other problem settings such as transfer learning and zero-shot domain adaptation, as well as other tasks such as detection and segmentation.
Class-Incremental Learning with Cross-Space Clustering and Controlled Transfer
Aug 16, 2022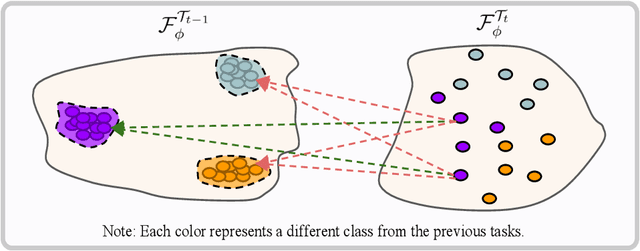
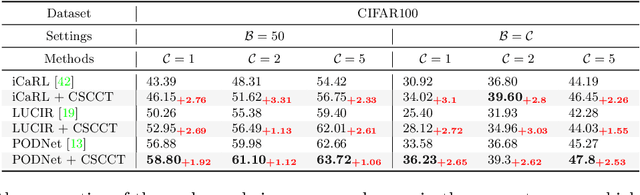
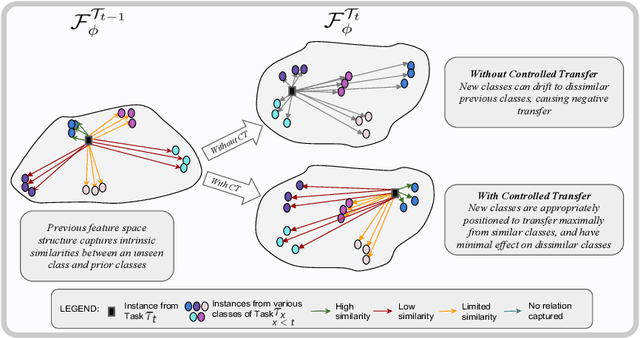
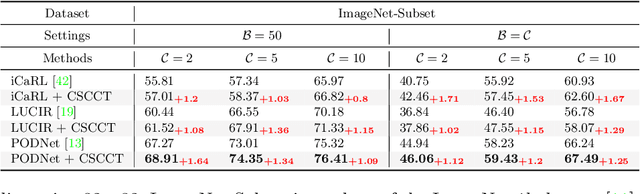
In class-incremental learning, the model is expected to learn new classes continually while maintaining knowledge on previous classes. The challenge here lies in preserving the model's ability to effectively represent prior classes in the feature space, while adapting it to represent incoming new classes. We propose two distillation-based objectives for class incremental learning that leverage the structure of the feature space to maintain accuracy on previous classes, as well as enable learning the new classes. In our first objective, termed cross-space clustering (CSC), we propose to use the feature space structure of the previous model to characterize directions of optimization that maximally preserve the class: directions that all instances of a specific class should collectively optimize towards, and those that they should collectively optimize away from. Apart from minimizing forgetting, this indirectly encourages the model to cluster all instances of a class in the current feature space, and gives rise to a sense of herd-immunity, allowing all samples of a class to jointly combat the model from forgetting the class. Our second objective termed controlled transfer (CT) tackles incremental learning from an understudied perspective of inter-class transfer. CT explicitly approximates and conditions the current model on the semantic similarities between incrementally arriving classes and prior classes. This allows the model to learn classes in such a way that it maximizes positive forward transfer from similar prior classes, thus increasing plasticity, and minimizes negative backward transfer on dissimilar prior classes, whereby strengthening stability. We perform extensive experiments on two benchmark datasets, adding our method (CSCCT) on top of three prominent class-incremental learning methods. We observe consistent performance improvement on a variety of experimental settings.
Novel Class Discovery without Forgetting
Jul 21, 2022

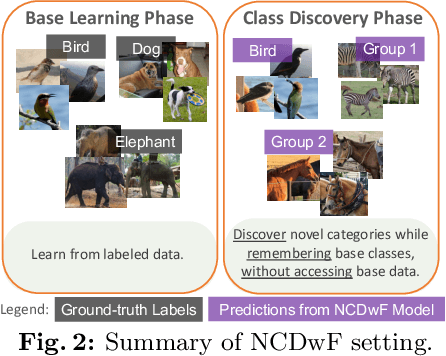
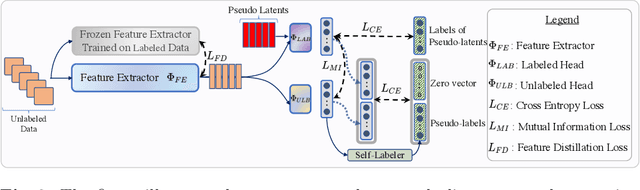
Humans possess an innate ability to identify and differentiate instances that they are not familiar with, by leveraging and adapting the knowledge that they have acquired so far. Importantly, they achieve this without deteriorating the performance on their earlier learning. Inspired by this, we identify and formulate a new, pragmatic problem setting of NCDwF: Novel Class Discovery without Forgetting, which tasks a machine learning model to incrementally discover novel categories of instances from unlabeled data, while maintaining its performance on the previously seen categories. We propose 1) a method to generate pseudo-latent representations which act as a proxy for (no longer available) labeled data, thereby alleviating forgetting, 2) a mutual-information based regularizer which enhances unsupervised discovery of novel classes, and 3) a simple Known Class Identifier which aids generalized inference when the testing data contains instances form both seen and unseen categories. We introduce experimental protocols based on CIFAR-10, CIFAR-100 and ImageNet-1000 to measure the trade-off between knowledge retention and novel class discovery. Our extensive evaluations reveal that existing models catastrophically forget previously seen categories while identifying novel categories, while our method is able to effectively balance between the competing objectives. We hope our work will attract further research into this newly identified pragmatic problem setting.
Spacing Loss for Discovering Novel Categories
Apr 22, 2022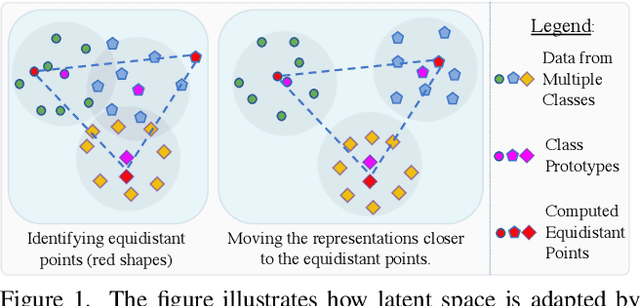
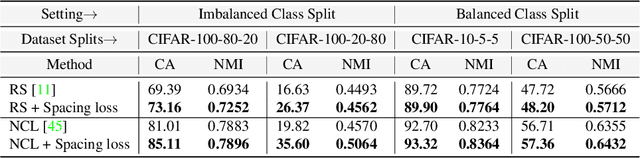
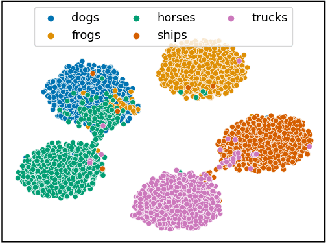
Novel Class Discovery (NCD) is a learning paradigm, where a machine learning model is tasked to semantically group instances from unlabeled data, by utilizing labeled instances from a disjoint set of classes. In this work, we first characterize existing NCD approaches into single-stage and two-stage methods based on whether they require access to labeled and unlabeled data together while discovering new classes. Next, we devise a simple yet powerful loss function that enforces separability in the latent space using cues from multi-dimensional scaling, which we refer to as Spacing Loss. Our proposed formulation can either operate as a standalone method or can be plugged into existing methods to enhance them. We validate the efficacy of Spacing Loss with thorough experimental evaluation across multiple settings on CIFAR-10 and CIFAR-100 datasets.