 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Sink-Aware Grounded Decoding for Multimodal Hallucination Mitigation
Mar 29, 2026Large vision-language models (VLMs) frequently suffer from hallucinations, generating content that is inconsistent with visual inputs. Existing methods typically address this problem through post-hoc filtering, additional training objectives, or external verification, but they do not intervene during the decoding process when hallucinations arise. In this work, we introduce SAGE, a Sink-Aware Grounded Decoding framework that mitigates hallucinations by dynamically modulating self-attention during generation. Hallucinations are strongly correlated with attention sink tokens - punctuation or function tokens that accumulate disproportionate attention despite carrying limited semantic content. SAGE leverages these tokens as anchors to monitor grounding reliability in real time. At each sink trigger, the method extracts semantic concepts from the generated sequence, estimates their visual grounding using both self-attention maps and gradient-based attribution, and measures their spatial agreement. Based on this signal, self-attention distributions are adaptively sharpened or broadened to reinforce grounded regions or suppress unreliable ones. Extensive experiments across diverse hallucination benchmarks demonstrate that SAGE consistently outperforms existing decoding strategies, achieving substantial reductions in hallucination while preserving descriptive coverage, without requiring model retraining or architectural modifications. Our method achieves an average relative improvement of 10.65% on MSCOCO and 7.19% on AMBER across diverse VLM architectures, demonstrating consistent gains in hallucination mitigation.
Taming LLMs with Negative Samples: A Reference-Free Framework to Evaluate Presentation Content with Actionable Feedback
May 23, 2025The generation of presentation slides automatically is an important problem in the era of generative AI. This paper focuses on evaluating multimodal content in presentation slides that can effectively summarize a document and convey concepts to a broad audience. We introduce a benchmark dataset, RefSlides, consisting of human-made high-quality presentations that span various topics. Next, we propose a set of metrics to characterize different intrinsic properties of the content of a presentation and present REFLEX, an evaluation approach that generates scores and actionable feedback for these metrics. We achieve this by generating negative presentation samples with different degrees of metric-specific perturbations and use them to fine-tune LLMs. This reference-free evaluation technique does not require ground truth presentations during inference. Our extensive automated and human experiments demonstrate that our evaluation approach outperforms classical heuristic-based and state-of-the-art large language model-based evaluations in generating scores and explanations.
Design-o-meter: Towards Evaluating and Refining Graphic Designs
Nov 22, 2024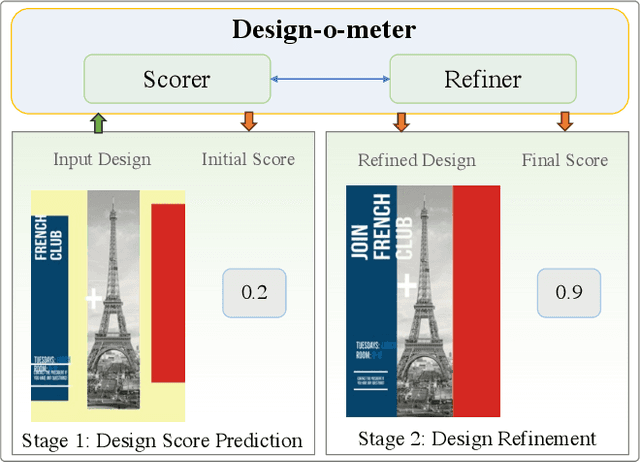
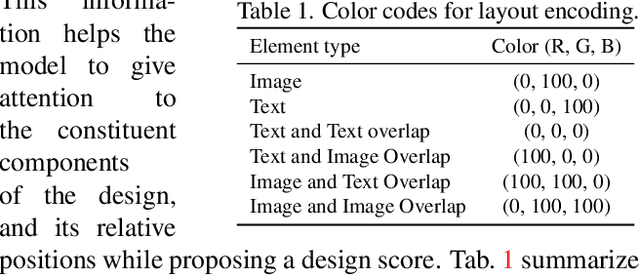
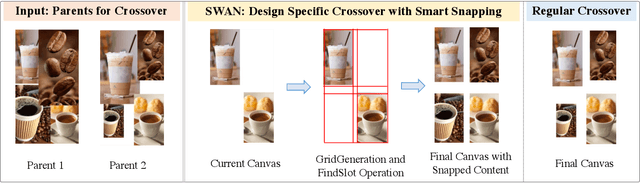
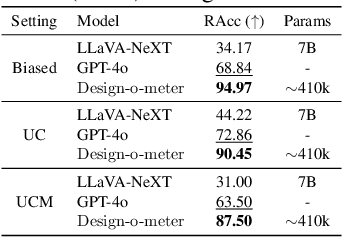
Graphic designs are an effective medium for visual communication. They range from greeting cards to corporate flyers and beyond. Off-late, machine learning techniques are able to generate such designs, which accelerates the rate of content production. An automated way of evaluating their quality becomes critical. Towards this end, we introduce Design-o-meter, a data-driven methodology to quantify the goodness of graphic designs. Further, our approach can suggest modifications to these designs to improve its visual appeal. To the best of our knowledge, Design-o-meter is the first approach that scores and refines designs in a unified framework despite the inherent subjectivity and ambiguity of the setting. Our exhaustive quantitative and qualitative analysis of our approach against baselines adapted for the task (including recent Multimodal LLM-based approaches) brings out the efficacy of our methodology. We hope our work will usher more interest in this important and pragmatic problem setting.
Test-time Conditional Text-to-Image Synthesis Using Diffusion Models
Nov 16, 2024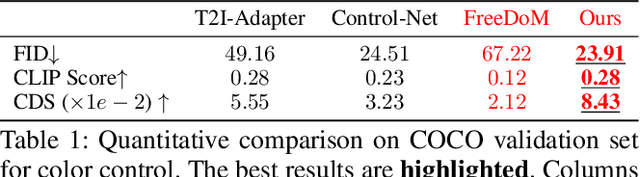
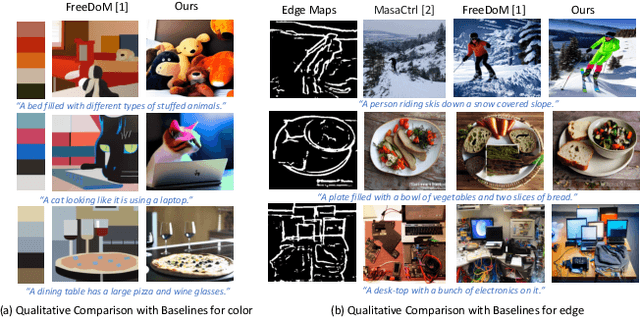
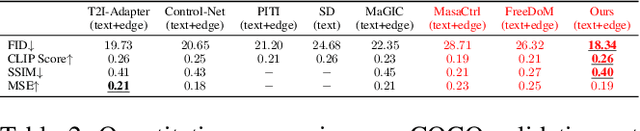
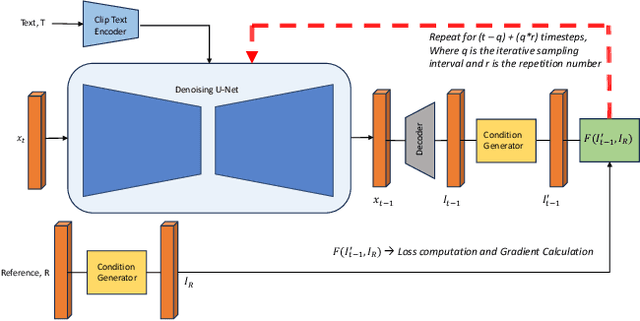
We consider the problem of conditional text-to-image synthesis with diffusion models. Most recent works need to either finetune specific parts of the base diffusion model or introduce new trainable parameters, leading to deployment inflexibility due to the need for training. To address this gap in the current literature, we propose our method called TINTIN: Test-time Conditional Text-to-Image Synthesis using Diffusion Models which is a new training-free test-time only algorithm to condition text-to-image diffusion model outputs on conditioning factors such as color palettes and edge maps. In particular, we propose to interpret noise predictions during denoising as gradients of an energy-based model, leading to a flexible approach to manipulate the noise by matching predictions inferred from them to the ground truth conditioning input. This results in, to the best of our knowledge, the first approach to control model outputs with input color palettes, which we realize using a novel color distribution matching loss. We also show this test-time noise manipulation can be easily extensible to other types of conditioning, e.g., edge maps. We conduct extensive experiments using a variety of text prompts, color palettes, and edge maps and demonstrate significant improvement over the current state-of-the-art, both qualitatively and quantitatively.
An Image is Worth Multiple Words: Multi-attribute Inversion for Constrained Text-to-Image Synthesis
Nov 20, 2023We consider the problem of constraining diffusion model outputs with a user-supplied reference image. Our key objective is to extract multiple attributes (e.g., color, object, layout, style) from this single reference image, and then generate new samples with them. One line of existing work proposes to invert the reference images into a single textual conditioning vector, enabling generation of new samples with this learned token. These methods, however, do not learn multiple tokens that are necessary to condition model outputs on the multiple attributes noted above. Another line of techniques expand the inversion space to learn multiple embeddings but they do this only along the layer dimension (e.g., one per layer of the DDPM model) or the timestep dimension (one for a set of timesteps in the denoising process), leading to suboptimal attribute disentanglement. To address the aforementioned gaps, the first contribution of this paper is an extensive analysis to determine which attributes are captured in which dimension of the denoising process. As noted above, we consider both the time-step dimension (in reverse denoising) as well as the DDPM model layer dimension. We observe that often a subset of these attributes are captured in the same set of model layers and/or across same denoising timesteps. For instance, color and style are captured across same U-Net layers, whereas layout and color are captured across same timestep stages. Consequently, an inversion process that is designed only for the time-step dimension or the layer dimension is insufficient to disentangle all attributes. This leads to our second contribution where we design a new multi-attribute inversion algorithm, MATTE, with associated disentanglement-enhancing regularization losses, that operates across both dimensions and explicitly leads to four disentangled tokens (color, style, layout, and object).
Iterative Multi-granular Image Editing using Diffusion Models
Sep 01, 2023



Recent advances in text-guided image synthesis has dramatically changed how creative professionals generate artistic and aesthetically pleasing visual assets. To fully support such creative endeavors, the process should possess the ability to: 1) iteratively edit the generations and 2) control the spatial reach of desired changes (global, local or anything in between). We formalize this pragmatic problem setting as Iterative Multi-granular Editing. While there has been substantial progress with diffusion-based models for image synthesis and editing, they are all one shot (i.e., no iterative editing capabilities) and do not naturally yield multi-granular control (i.e., covering the full spectrum of local-to-global edits). To overcome these drawbacks, we propose EMILIE: Iterative Multi-granular Image Editor. EMILIE introduces a novel latent iteration strategy, which re-purposes a pre-trained diffusion model to facilitate iterative editing. This is complemented by a gradient control operation for multi-granular control. We introduce a new benchmark dataset to evaluate our newly proposed setting. We conduct exhaustive quantitatively and qualitatively evaluation against recent state-of-the-art approaches adapted to our task, to being out the mettle of EMILIE. We hope our work would attract attention to this newly identified, pragmatic problem setting.
DistillAdapt: Source-Free Active Visual Domain Adaptation
May 24, 2022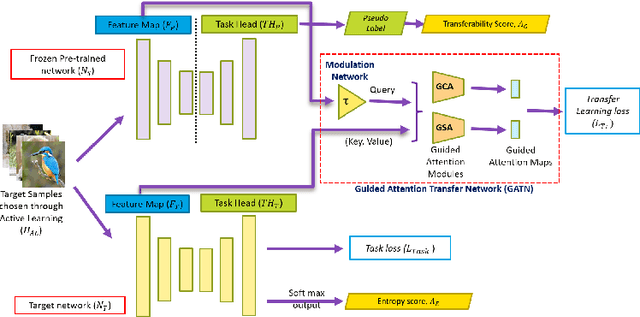

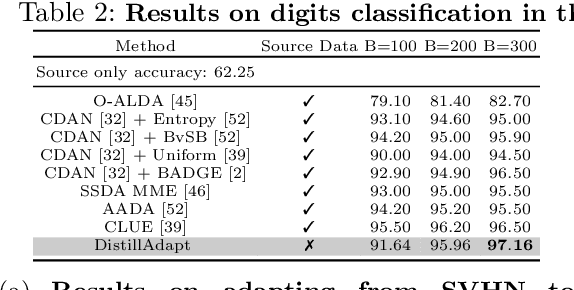
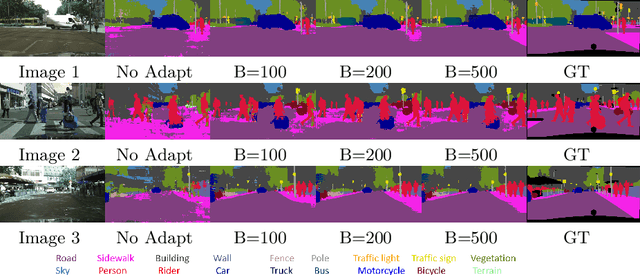
We present a novel method, DistillAdapt, for the challenging problem of Source-Free Active Domain Adaptation (SF-ADA). The problem requires adapting a pretrained source domain network to a target domain, within a provided budget for acquiring labels in the target domain, while assuming that the source data is not available for adaptation due to privacy concerns or otherwise. DistillAdapt is one of the first approaches for SF-ADA, and holistically addresses the challenges of SF-ADA via a novel Guided Attention Transfer Network (GATN) and an active learning heuristic, H_AL. The GATN enables selective distillation of features from the pre-trained network to the target network using a small subset of annotated target samples mined by H_AL. H_AL acquires samples at batch-level and balances transfer-ability from the pre-trained network and uncertainty of the target network. DistillAdapt is task-agnostic, and can be applied across visual tasks such as classification, segmentation and detection. Moreover, DistillAdapt can handle shifts in output label space. We conduct experiments and extensive ablation studies across 3 visual tasks, viz. digits classification (MNIST, SVHN), synthetic (GTA5) to real (CityScapes) image segmentation, and document layout detection (PubLayNet to DSSE). We show that our source-free approach, DistillAdapt, results in an improvement of 0.5% - 31.3% (across datasets and tasks) over prior adaptation methods that assume access to large amounts of annotated source data for adaptation.