 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillAdapt: Source-Free Active Visual Domain Adaptation
May 24, 2022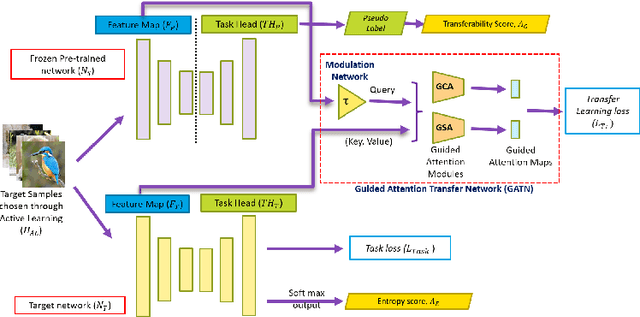

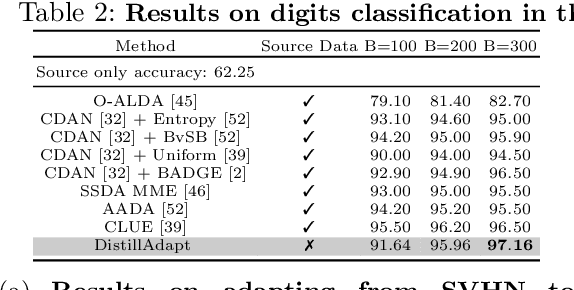
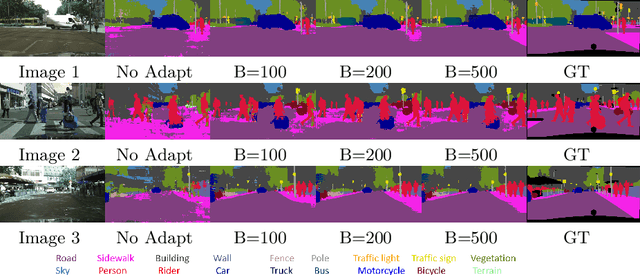
We present a novel method, DistillAdapt, for the challenging problem of Source-Free Active Domain Adaptation (SF-ADA). The problem requires adapting a pretrained source domain network to a target domain, within a provided budget for acquiring labels in the target domain, while assuming that the source data is not available for adaptation due to privacy concerns or otherwise. DistillAdapt is one of the first approaches for SF-ADA, and holistically addresses the challenges of SF-ADA via a novel Guided Attention Transfer Network (GATN) and an active learning heuristic, H_AL. The GATN enables selective distillation of features from the pre-trained network to the target network using a small subset of annotated target samples mined by H_AL. H_AL acquires samples at batch-level and balances transfer-ability from the pre-trained network and uncertainty of the target network. DistillAdapt is task-agnostic, and can be applied across visual tasks such as classification, segmentation and detection. Moreover, DistillAdapt can handle shifts in output label space. We conduct experiments and extensive ablation studies across 3 visual tasks, viz. digits classification (MNIST, SVHN), synthetic (GTA5) to real (CityScapes) image segmentation, and document layout detection (PubLayNet to DSSE). We show that our source-free approach, DistillAdapt, results in an improvement of 0.5% - 31.3% (across datasets and tasks) over prior adaptation methods that assume access to large amounts of annotated source data for adaptation.
Learning Colour Representations of Search Queries
Jun 17, 2020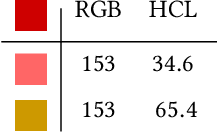
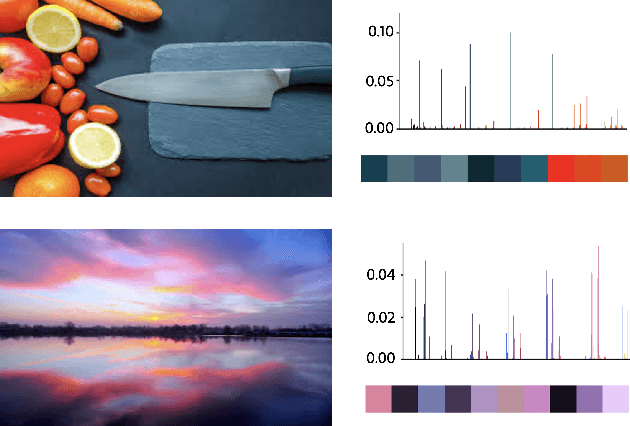

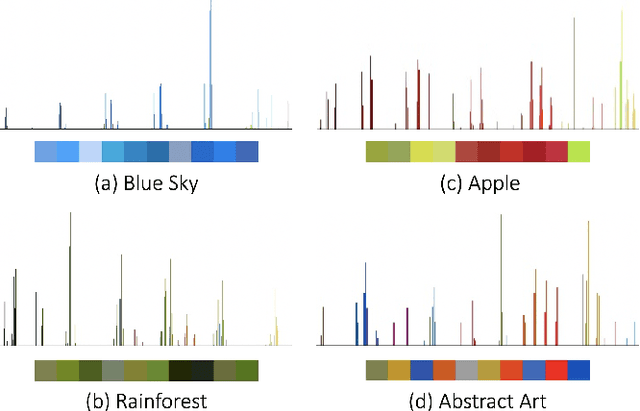
Image search engines rely on appropriately designed ranking features that capture various aspects of the content semantics as well as the historic popularity. In this work, we consider the role of colour in this relevance matching process. Our work is motivated by the observation that a significant fraction of user queries have an inherent colour associated with them. While some queries contain explicit colour mentions (such as 'black car' and 'yellow daisies'), other queries have implicit notions of colour (such as 'sky' and 'grass'). Furthermore, grounding queries in colour is not a mapping to a single colour, but a distribution in colour space. For instance, a search for 'trees' tends to have a bimodal distribution around the colours green and brown. We leverage historical clickthrough data to produce a colour representation for search queries and propose a recurrent neural network architecture to encode unseen queries into colour space. We also show how this embedding can be learnt alongside a cross-modal relevance ranker from impression logs where a subset of the result images were clicked. We demonstrate that the use of a query-image colour distance feature leads to an improvement in the ranker performance as measured by users' preferences of clicked versus skipped images.