 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccessibility in Information Retrieval
Apr 12, 2024This paper introduces the concept of accessibility from the field of transportation planning and adopts it within the context of Information Retrieval (IR). An analogy is drawn between the fields, which motivates the development of document accessibility measures for IR systems. Considering the accessibility of documents within a collection given an IR System provides a different perspective on the analysis and evaluation of such systems which could be used to inform the design, tuning and management of current and future IR systems.
Self-supervised Multi-view Disentanglement for Expansion of Visual Collections
Feb 04, 2023

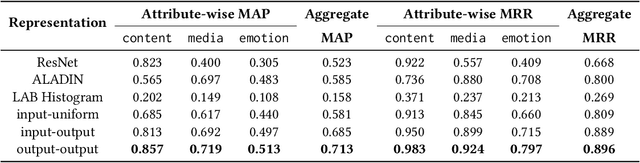
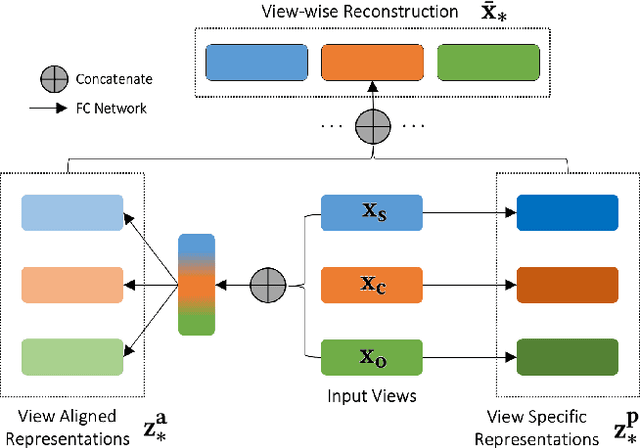
Image search engines enable the retrieval of images relevant to a query image. In this work, we consider the setting where a query for similar images is derived from a collection of images. For visual search, the similarity measurements may be made along multiple axes, or views, such as style and color. We assume access to a set of feature extractors, each of which computes representations for a specific view. Our objective is to design a retrieval algorithm that effectively combines similarities computed over representations from multiple views. To this end, we propose a self-supervised learning method for extracting disentangled view-specific representations for images such that the inter-view overlap is minimized. We show how this allows us to compute the intent of a collection as a distribution over views. We show how effective retrieval can be performed by prioritizing candidate expansion images that match the intent of a query collection. Finally, we present a new querying mechanism for image search enabled by composing multiple collections and perform retrieval under this setting using the techniques presented in this paper.
Robustness of Fusion-based Multimodal Classifiers to Cross-Modal Content Dilutions
Nov 04, 2022



As multimodal learning finds applications in a wide variety of high-stakes societal tasks, investigating their robustness becomes important. Existing work has focused on understanding the robustness of vision-and-language models to imperceptible variations on benchmark tasks. In this work, we investigate the robustness of multimodal classifiers to cross-modal dilutions - a plausible variation. We develop a model that, given a multimodal (image + text) input, generates additional dilution text that (a) maintains relevance and topical coherence with the image and existing text, and (b) when added to the original text, leads to misclassification of the multimodal input. Via experiments on Crisis Humanitarianism and Sentiment Detection tasks, we find that the performance of task-specific fusion-based multimodal classifiers drops by 23.3% and 22.5%, respectively, in the presence of dilutions generated by our model. Metric-based comparisons with several baselines and human evaluations indicate that our dilutions show higher relevance and topical coherence, while simultaneously being more effective at demonstrating the brittleness of the multimodal classifiers. Our work aims to highlight and encourage further research on the robustness of deep multimodal models to realistic variations, especially in human-facing societal applications. The code and other resources are available at https://claws-lab.github.io/multimodal-robustness/.
GEMS: Scene Expansion using Generative Models of Graphs
Jul 08, 2022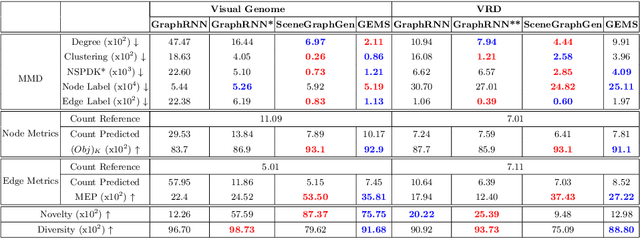
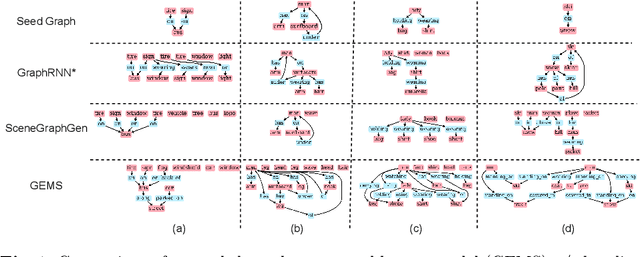
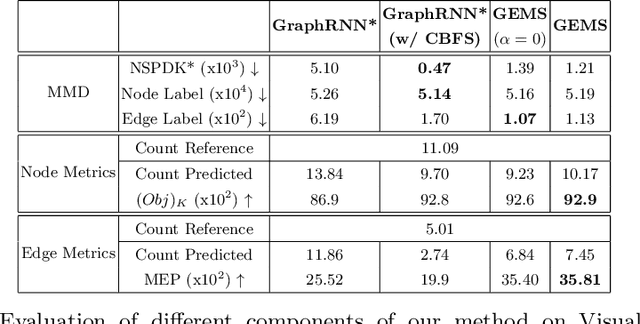
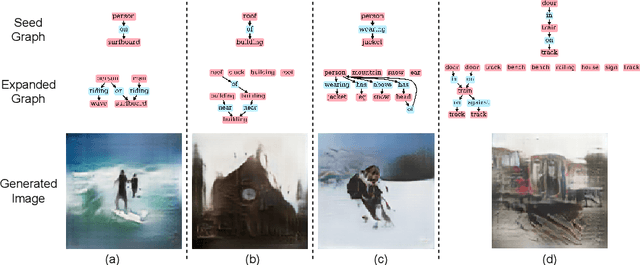
Applications based on image retrieval require editing and associating in intermediate spaces that are representative of the high-level concepts like objects and their relationships rather than dense, pixel-level representations like RGB images or semantic-label maps. We focus on one such representation, scene graphs, and propose a novel scene expansion task where we enrich an input seed graph by adding new nodes (objects) and the corresponding relationships. To this end, we formulate scene graph expansion as a sequential prediction task involving multiple steps of first predicting a new node and then predicting the set of relationships between the newly predicted node and previous nodes in the graph. We propose a sequencing strategy for observed graphs that retains the clustering patterns amongst nodes. In addition, we leverage external knowledge to train our graph generation model, enabling greater generalization of node predictions. Due to the inefficiency of existing maximum mean discrepancy (MMD) based metrics for graph generation problems in evaluating predicted relationships between nodes (objects), we design novel metrics that comprehensively evaluate different aspects of predicted relations. We conduct extensive experiments on Visual Genome and VRD datasets to evaluate the expanded scene graphs using the standard MMD-based metrics and our proposed metrics. We observe that the graphs generated by our method, GEMS, better represent the real distribution of the scene graphs than the baseline methods like GraphRNN.
Offline Evaluation of Ranked Lists using Parametric Estimation of Propensities
Jun 06, 2022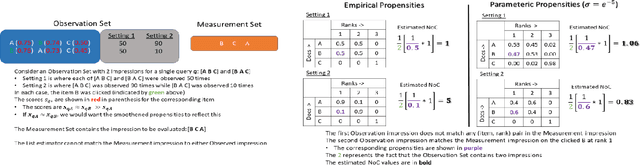
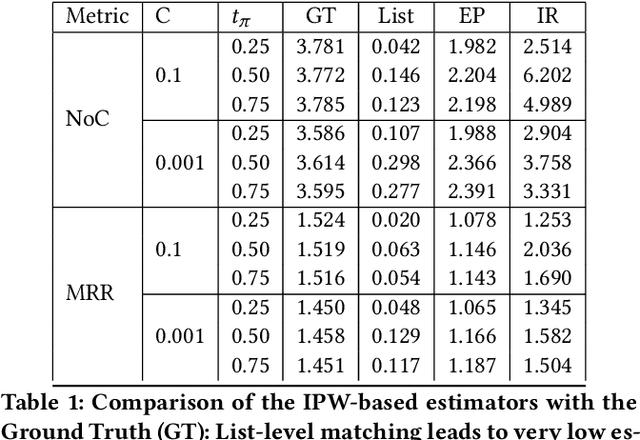

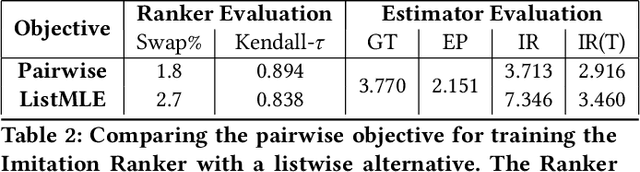
Search engines and recommendation systems attempt to continually improve the quality of the experience they afford to their users. Refining the ranker that produces the lists displayed in response to user requests is an important component of this process. A common practice is for the service providers to make changes (e.g. new ranking features, different ranking models) and A/B test them on a fraction of their users to establish the value of the change. An alternative approach estimates the effectiveness of the proposed changes offline, utilising previously collected clickthrough data on the old ranker to posit what the user behaviour on ranked lists produced by the new ranker would have been. A majority of offline evaluation approaches invoke the well studied inverse propensity weighting to adjust for biases inherent in logged data. In this paper, we propose the use of parametric estimates for these propensities. Specifically, by leveraging well known learning-to-rank methods as subroutines, we show how accurate offline evaluation can be achieved when the new rankings to be evaluated differ from the logged ones.
CyCLIP: Cyclic Contrastive Language-Image Pretraining
May 28, 2022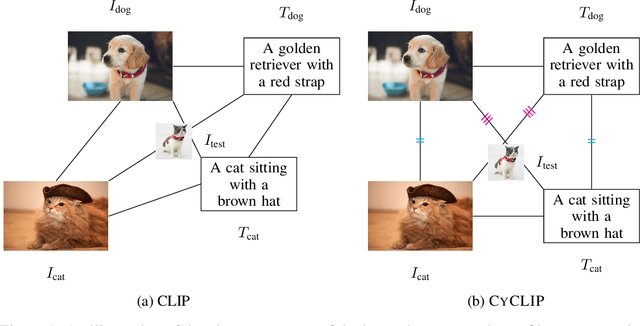
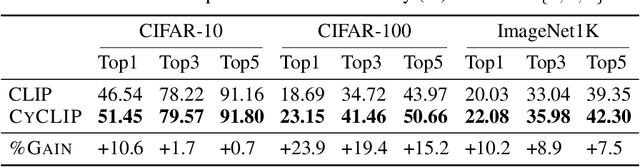
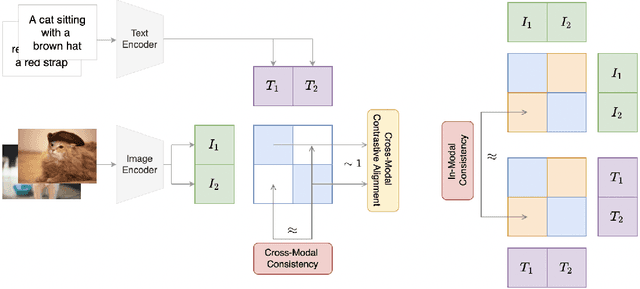
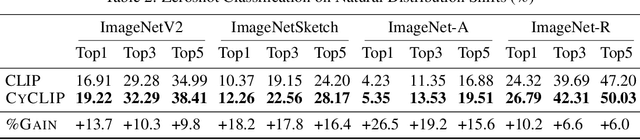
Recent advances in contrastive representation learning over paired image-text data have led to models such as CLIP that achieve state-of-the-art performance for zero-shot classification and distributional robustness. Such models typically require joint reasoning in the image and text representation spaces for downstream inference tasks. Contrary to prior beliefs, we demonstrate that the image and text representations learned via a standard contrastive objective are not interchangeable and can lead to inconsistent downstream predictions. To mitigate this issue, we formalize consistency and propose CyCLIP, a framework for contrastive representation learning that explicitly optimizes for the learned representations to be geometrically consistent in the image and text space. In particular, we show that consistent representations can be learned by explicitly symmetrizing (a) the similarity between the two mismatched image-text pairs (cross-modal consistency); and (b) the similarity between the image-image pair and the text-text pair (in-modal consistency). Empirically, we show that the improved consistency in CyCLIP translates to significant gains over CLIP, with gains ranging from 10%-24% for zero-shot classification accuracy on standard benchmarks (CIFAR-10, CIFAR-100, ImageNet1K) and 10%-27% for robustness to various natural distribution shifts. The code is available at https://github.com/goel-shashank/CyCLIP.
Curriculum Learning for Dense Retrieval Distillation
Apr 28, 2022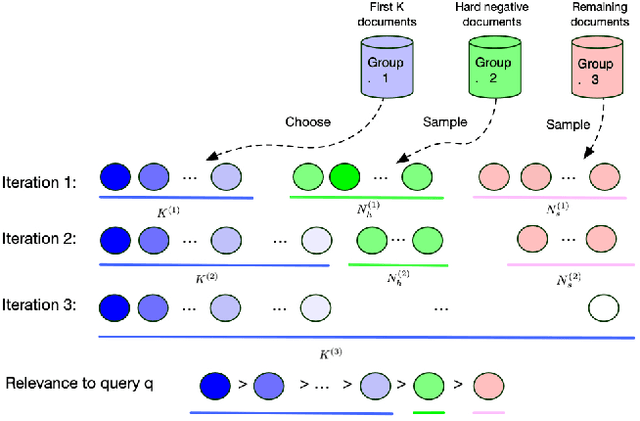
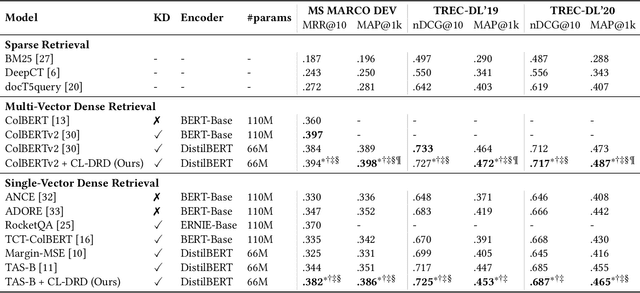
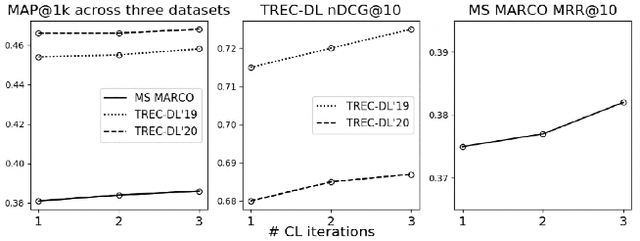
Recent work has shown that more effective dense retrieval models can be obtained by distilling ranking knowledge from an existing base re-ranking model. In this paper, we propose a generic curriculum learning based optimization framework called CL-DRD that controls the difficulty level of training data produced by the re-ranking (teacher) model. CL-DRD iteratively optimizes the dense retrieval (student) model by increasing the difficulty of the knowledge distillation data made available to it. In more detail, we initially provide the student model coarse-grained preference pairs between documents in the teacher's ranking and progressively move towards finer-grained pairwise document ordering requirements. In our experiments, we apply a simple implementation of the CL-DRD framework to enhance two state-of-the-art dense retrieval models. Experiments on three public passage retrieval datasets demonstrate the effectiveness of our proposed framework.
Gaudí: Conversational Interactions with Deep Representations to Generate Image Collections
Dec 05, 2021

Based on recent advances in realistic language modeling (GPT-3) and cross-modal representations (CLIP), Gaud\'i was developed to help designers search for inspirational images using natural language. In the early stages of the design process, with the goal of eliciting a client's preferred creative direction, designers will typically create thematic collections of inspirational images called "mood-boards". Creating a mood-board involves sequential image searches which are currently performed using keywords or images. Gaud\'i transforms this process into a conversation where the user is gradually detailing the mood-board's theme. This representation allows our AI to generate new search queries from scratch, straight from a project briefing, following a theme hypothesized by GPT-3. Compared to previous computational approaches to mood-board creation, to the best of our knowledge, ours is the first attempt to represent mood-boards as the stories that designers tell when presenting a creative direction to a client.
Generating Compositional Color Representations from Text
Sep 22, 2021
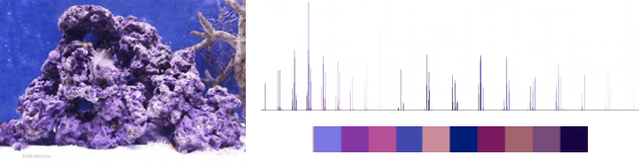
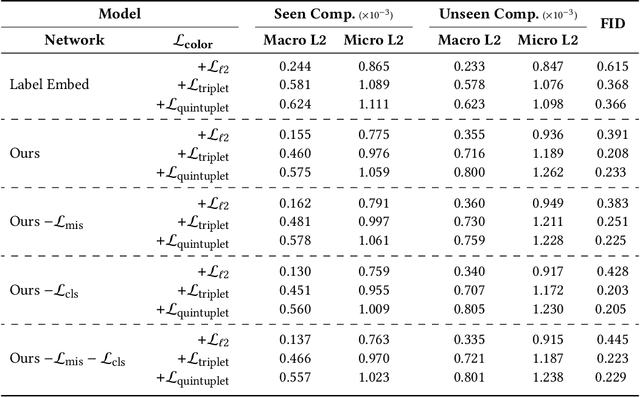

We consider the cross-modal task of producing color representations for text phrases. Motivated by the fact that a significant fraction of user queries on an image search engine follow an (attribute, object) structure, we propose a generative adversarial network that generates color profiles for such bigrams. We design our pipeline to learn composition - the ability to combine seen attributes and objects to unseen pairs. We propose a novel dataset curation pipeline from existing public sources. We describe how a set of phrases of interest can be compiled using a graph propagation technique, and then mapped to images. While this dataset is specialized for our investigations on color, the method can be extended to other visual dimensions where composition is of interest. We provide detailed ablation studies that test the behavior of our GAN architecture with loss functions from the contrastive learning literature. We show that the generative model achieves lower Frechet Inception Distance than discriminative ones, and therefore predicts color profiles that better match those from real images. Finally, we demonstrate improved performance in image retrieval and classification, indicating the crucial role that color plays in these downstream tasks.
Scene Graph Embeddings Using Relative Similarity Supervision
Apr 06, 2021
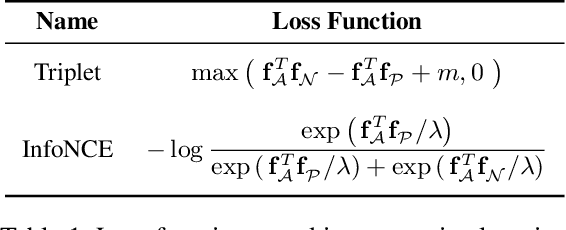
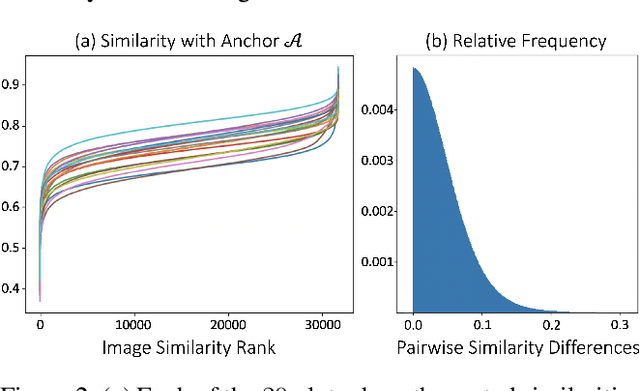
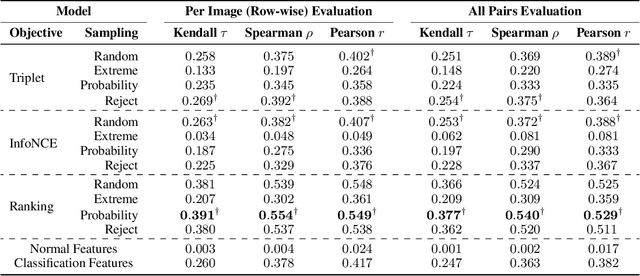
Scene graphs are a powerful structured representation of the underlying content of images, and embeddings derived from them have been shown to be useful in multiple downstream tasks. In this work, we employ a graph convolutional network to exploit structure in scene graphs and produce image embeddings useful for semantic image retrieval. Different from classification-centric supervision traditionally available for learning image representations, we address the task of learning from relative similarity labels in a ranking context. Rooted within the contrastive learning paradigm, we propose a novel loss function that operates on pairs of similar and dissimilar images and imposes relative ordering between them in embedding space. We demonstrate that this Ranking loss, coupled with an intuitive triple sampling strategy, leads to robust representations that outperform well-known contrastive losses on the retrieval task. In addition, we provide qualitative evidence of how retrieved results that utilize structured scene information capture the global context of the scene, different from visual similarity search.