 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyCLIP: Cyclic Contrastive Language-Image Pretraining
May 28, 2022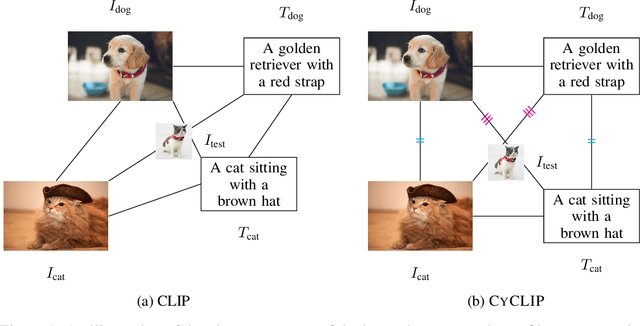
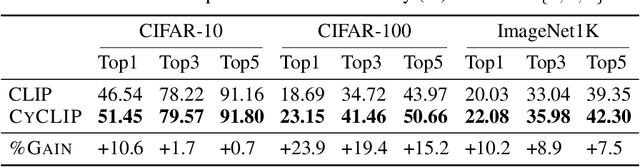
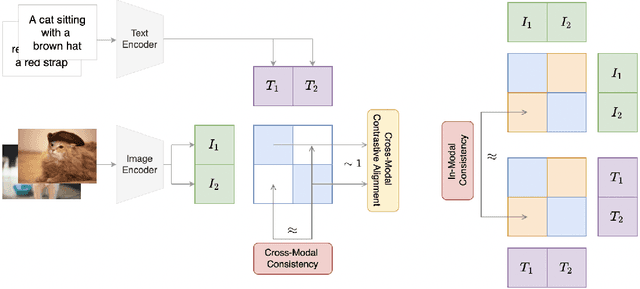
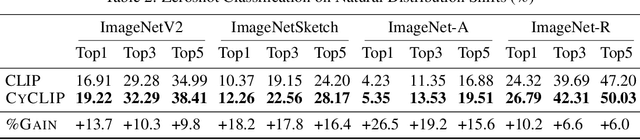
Recent advances in contrastive representation learning over paired image-text data have led to models such as CLIP that achieve state-of-the-art performance for zero-shot classification and distributional robustness. Such models typically require joint reasoning in the image and text representation spaces for downstream inference tasks. Contrary to prior beliefs, we demonstrate that the image and text representations learned via a standard contrastive objective are not interchangeable and can lead to inconsistent downstream predictions. To mitigate this issue, we formalize consistency and propose CyCLIP, a framework for contrastive representation learning that explicitly optimizes for the learned representations to be geometrically consistent in the image and text space. In particular, we show that consistent representations can be learned by explicitly symmetrizing (a) the similarity between the two mismatched image-text pairs (cross-modal consistency); and (b) the similarity between the image-image pair and the text-text pair (in-modal consistency). Empirically, we show that the improved consistency in CyCLIP translates to significant gains over CLIP, with gains ranging from 10%-24% for zero-shot classification accuracy on standard benchmarks (CIFAR-10, CIFAR-100, ImageNet1K) and 10%-27% for robustness to various natural distribution shifts. The code is available at https://github.com/goel-shashank/CyCLIP.
Joint Spatio-Textual Reasoning for Answering Tourism Questions
Oct 19, 2020

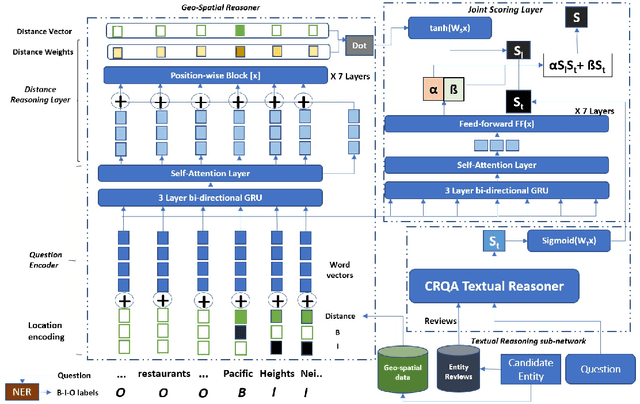
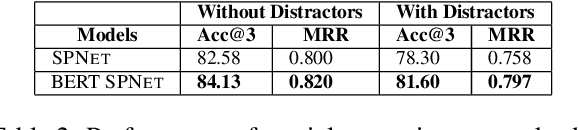
Our goal is to answer real-world tourism questions that seek Points-of-Interest (POI) recommendations. Such questions express various kinds of spatial and non-spatial constraints, necessitating a combination of textual and spatial reasoning. In response, we develop the first joint spatio-textual reasoning model, which combines geo-spatial knowledge with information in textual corpora to answer questions. We first develop a modular spatial-reasoning network that uses geo-coordinates of location names mentioned in a question, and of candidate answer POIs, to reason over only spatial constraints. We then combine our spatial-reasoner with a textual reasoner in a joint model and present experiments on a real world POI recommendation task. We report substantial improvements over existing models with-out joint spatio-textual reasoning.