 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowCast: Trajectory Forecasting for Scalable Zero-Cost Speculative Flow Matching
Feb 01, 2026Flow Matching (FM) has recently emerged as a powerful approach for high-quality visual generation. However, their prohibitively slow inference due to a large number of denoising steps limits their potential use in real-time or interactive applications. Existing acceleration methods, like distillation, truncation, or consistency training, either degrade quality, incur costly retraining, or lack generalization. We propose FlowCast, a training-free speculative generation framework that accelerates inference by exploiting the fact that FM models are trained to preserve constant velocity. FlowCast speculates future velocity by extrapolating current velocity without incurring additional time cost, and accepts it if it is within a mean-squared error threshold. This constant-velocity forecasting allows redundant steps in stable regions to be aggressively skipped while retaining precision in complex ones. FlowCast is a plug-and-play framework that integrates seamlessly with any FM model and requires no auxiliary networks. We also present a theoretical analysis and bound the worst-case deviation between speculative and full FM trajectories. Empirical evaluations demonstrate that FlowCast achieves $>2.5\times$ speedup in image generation, video generation, and editing tasks, outperforming existing baselines with no quality loss as compared to standard full generation.
Object-WIPER : Training-Free Object and Associated Effect Removal in Videos
Jan 10, 2026In this paper, we introduce Object-WIPER, a training-free framework for removing dynamic objects and their associated visual effects from videos, and inpainting them with semantically consistent and temporally coherent content. Our approach leverages a pre-trained text-to-video diffusion transformer (DiT). Given an input video, a user-provided object mask, and query tokens describing the target object and its effects, we localize relevant visual tokens via visual-text cross-attention and visual self-attention. This produces an intermediate effect mask that we fuse with the user mask to obtain a final foreground token mask to replace. We first invert the video through the DiT to obtain structured noise, then reinitialize the masked tokens with Gaussian noise while preserving background tokens. During denoising, we copy values for the background tokens saved during inversion to maintain scene fidelity. To address the lack of suitable evaluation, we introduce a new object removal metric that rewards temporal consistency among foreground tokens across consecutive frames, coherence between foreground and background tokens within each frame, and dissimilarity between the input and output foreground tokens. Experiments on DAVIS and a newly curated real-world associated effect benchmark (WIPER-Bench) show that Object-WIPER surpasses both training-based and training-free baselines in terms of the metric, achieving clean removal and temporally stable reconstruction without any retraining. Our new benchmark, source code, and pre-trained models will be publicly available.
FloAt: Flow Warping of Self-Attention for Clothing Animation Generation
Nov 22, 2024
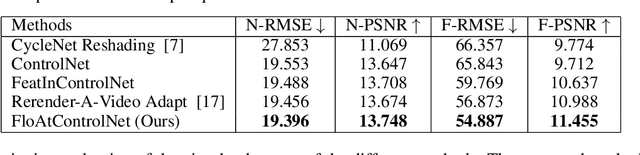
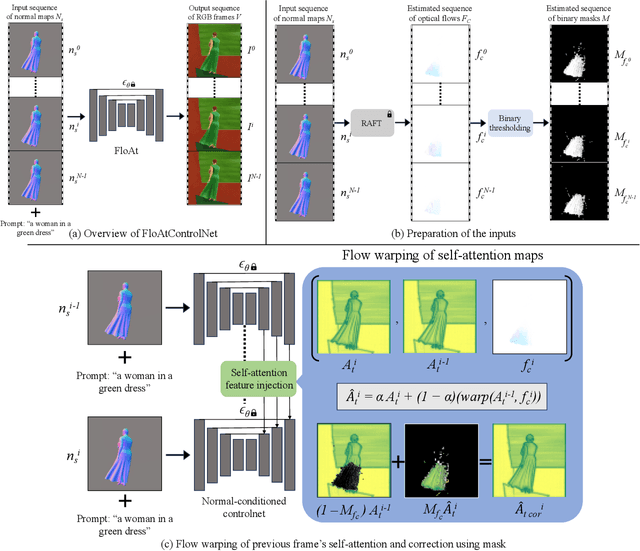
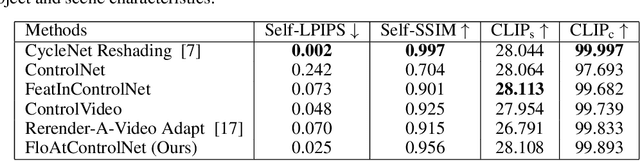
We propose a diffusion model-based approach, FloAtControlNet to generate cinemagraphs composed of animations of human clothing. We focus on human clothing like dresses, skirts and pants. The input to our model is a text prompt depicting the type of clothing and the texture of clothing like leopard, striped, or plain, and a sequence of normal maps that capture the underlying animation that we desire in the output. The backbone of our method is a normal-map conditioned ControlNet which is operated in a training-free regime. The key observation is that the underlying animation is embedded in the flow of the normal maps. We utilize the flow thus obtained to manipulate the self-attention maps of appropriate layers. Specifically, the self-attention maps of a particular layer and frame are recomputed as a linear combination of itself and the self-attention maps of the same layer and the previous frame, warped by the flow on the normal maps of the two frames. We show that manipulating the self-attention maps greatly enhances the quality of the clothing animation, making it look more natural as well as suppressing the background artifacts. Through extensive experiments, we show that the method proposed beats all baselines both qualitatively in terms of visual results and user study. Specifically, our method is able to alleviate the background flickering that exists in other diffusion model-based baselines that we consider. In addition, we show that our method beats all baselines in terms of RMSE and PSNR computed using the input normal map sequences and the normal map sequences obtained from the output RGB frames. Further, we show that well-established evaluation metrics like LPIPS, SSIM, and CLIP scores that are generally for visual quality are not necessarily suitable for capturing the subtle motions in human clothing animations.
Crafting Parts for Expressive Object Composition
Jun 14, 2024Text-to-image generation from large generative models like Stable Diffusion, DALLE-2, etc., have become a common base for various tasks due to their superior quality and extensive knowledge bases. As image composition and generation are creative processes the artists need control over various parts of the images being generated. We find that just adding details about parts in the base text prompt either leads to an entirely different image (e.g., missing/incorrect identity) or the extra part details simply being ignored. To mitigate these issues, we introduce PartCraft, which enables image generation based on fine-grained part-level details specified for objects in the base text prompt. This allows more control for artists and enables novel object compositions by combining distinctive object parts. PartCraft first localizes object parts by denoising the object region from a specific diffusion process. This enables each part token to be localized to the right object region. After obtaining part masks, we run a localized diffusion process in each of the part regions based on fine-grained part descriptions and combine them to produce the final image. All the stages of PartCraft are based on repurposing a pre-trained diffusion model, which enables it to generalize across various domains without training. We demonstrate the effectiveness of part-level control provided by PartCraft qualitatively through visual examples and quantitatively in comparison to the contemporary baselines.
Blowing in the Wind: CycleNet for Human Cinemagraphs from Still Images
Mar 15, 2023



Cinemagraphs are short looping videos created by adding subtle motions to a static image. This kind of media is popular and engaging. However, automatic generation of cinemagraphs is an underexplored area and current solutions require tedious low-level manual authoring by artists. In this paper, we present an automatic method that allows generating human cinemagraphs from single RGB images. We investigate the problem in the context of dressed humans under the wind. At the core of our method is a novel cyclic neural network that produces looping cinemagraphs for the target loop duration. To circumvent the problem of collecting real data, we demonstrate that it is possible, by working in the image normal space, to learn garment motion dynamics on synthetic data and generalize to real data. We evaluate our method on both synthetic and real data and demonstrate that it is possible to create compelling and plausible cinemagraphs from single RGB images.
Self-supervised Multi-view Disentanglement for Expansion of Visual Collections
Feb 04, 2023

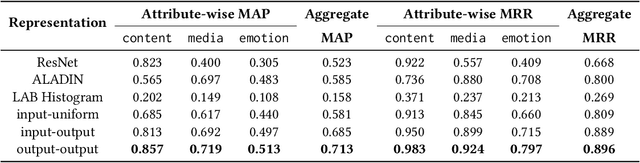
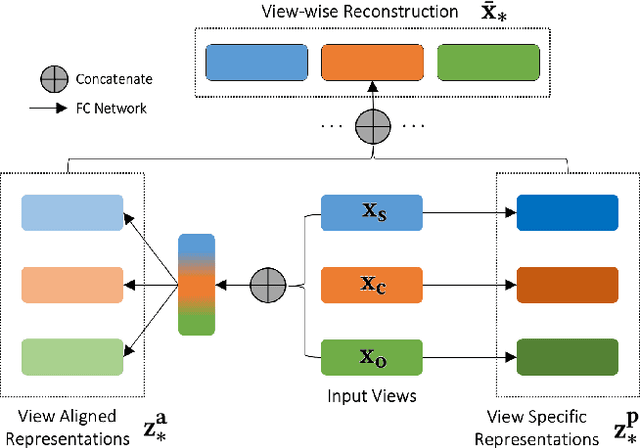
Image search engines enable the retrieval of images relevant to a query image. In this work, we consider the setting where a query for similar images is derived from a collection of images. For visual search, the similarity measurements may be made along multiple axes, or views, such as style and color. We assume access to a set of feature extractors, each of which computes representations for a specific view. Our objective is to design a retrieval algorithm that effectively combines similarities computed over representations from multiple views. To this end, we propose a self-supervised learning method for extracting disentangled view-specific representations for images such that the inter-view overlap is minimized. We show how this allows us to compute the intent of a collection as a distribution over views. We show how effective retrieval can be performed by prioritizing candidate expansion images that match the intent of a query collection. Finally, we present a new querying mechanism for image search enabled by composing multiple collections and perform retrieval under this setting using the techniques presented in this paper.
GEMS: Scene Expansion using Generative Models of Graphs
Jul 08, 2022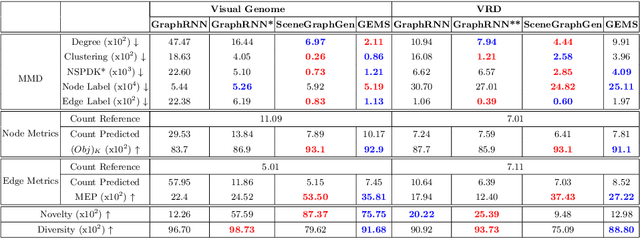
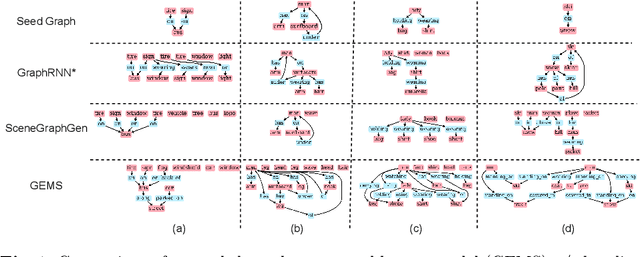
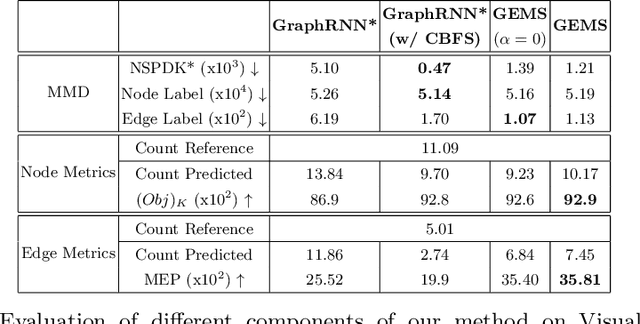
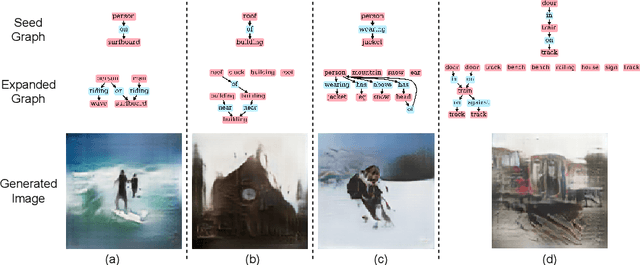
Applications based on image retrieval require editing and associating in intermediate spaces that are representative of the high-level concepts like objects and their relationships rather than dense, pixel-level representations like RGB images or semantic-label maps. We focus on one such representation, scene graphs, and propose a novel scene expansion task where we enrich an input seed graph by adding new nodes (objects) and the corresponding relationships. To this end, we formulate scene graph expansion as a sequential prediction task involving multiple steps of first predicting a new node and then predicting the set of relationships between the newly predicted node and previous nodes in the graph. We propose a sequencing strategy for observed graphs that retains the clustering patterns amongst nodes. In addition, we leverage external knowledge to train our graph generation model, enabling greater generalization of node predictions. Due to the inefficiency of existing maximum mean discrepancy (MMD) based metrics for graph generation problems in evaluating predicted relationships between nodes (objects), we design novel metrics that comprehensively evaluate different aspects of predicted relations. We conduct extensive experiments on Visual Genome and VRD datasets to evaluate the expanded scene graphs using the standard MMD-based metrics and our proposed metrics. We observe that the graphs generated by our method, GEMS, better represent the real distribution of the scene graphs than the baseline methods like GraphRNN.
Controllable Animation of Fluid Elements in Still Images
Dec 06, 2021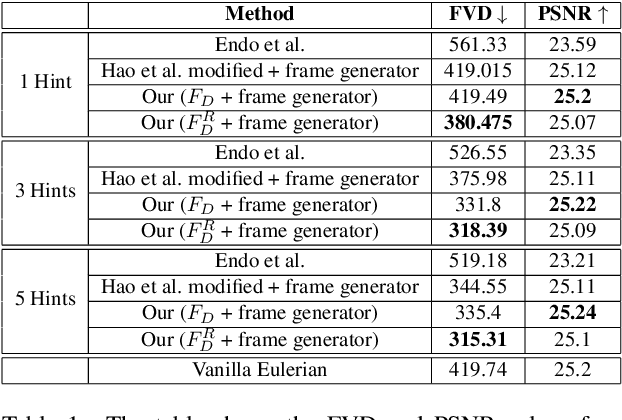
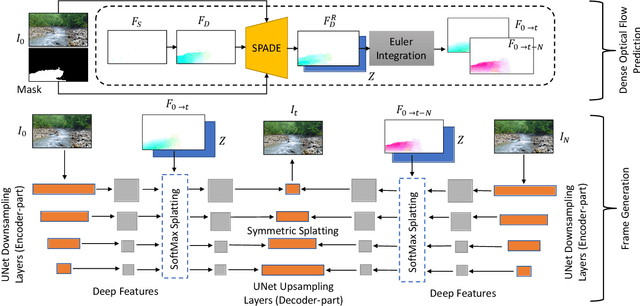
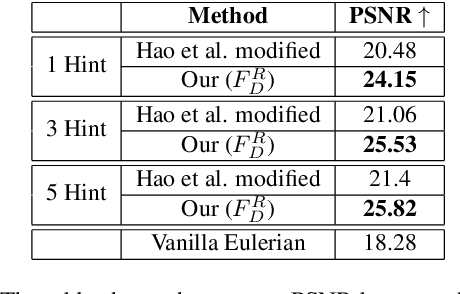

We propose a method to interactively control the animation of fluid elements in still images to generate cinemagraphs. Specifically, we focus on the animation of fluid elements like water, smoke, fire, which have the properties of repeating textures and continuous fluid motion. Taking inspiration from prior works, we represent the motion of such fluid elements in the image in the form of a constant 2D optical flow map. To this end, we allow the user to provide any number of arrow directions and their associated speeds along with a mask of the regions the user wants to animate. The user-provided input arrow directions, their corresponding speed values, and the mask are then converted into a dense flow map representing a constant optical flow map (FD). We observe that FD, obtained using simple exponential operations can closely approximate the plausible motion of elements in the image. We further refine computed dense optical flow map FD using a generative-adversarial network (GAN) to obtain a more realistic flow map. We devise a novel UNet based architecture to autoregressively generate future frames using the refined optical flow map by forward-warping the input image features at different resolutions. We conduct extensive experiments on a publicly available dataset and show that our method is superior to the baselines in terms of qualitative and quantitative metrics. In addition, we show the qualitative animations of the objects in directions that did not exist in the training set and provide a way to synthesize videos that otherwise would not exist in the real world.
SemIE: Semantically-aware Image Extrapolation
Aug 31, 2021
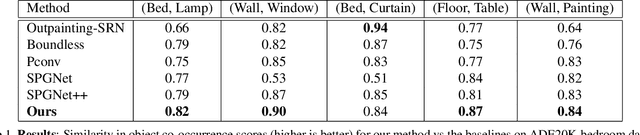
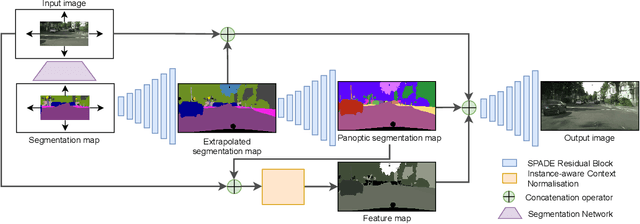
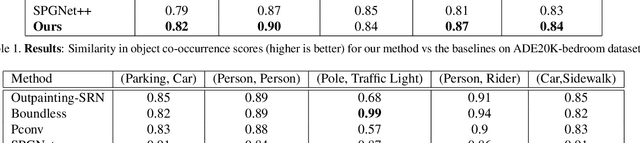
We propose a semantically-aware novel paradigm to perform image extrapolation that enables the addition of new object instances. All previous methods are limited in their capability of extrapolation to merely extending the already existing objects in the image. However, our proposed approach focuses not only on (i) extending the already present objects but also on (ii) adding new objects in the extended region based on the context. To this end, for a given image, we first obtain an object segmentation map using a state-of-the-art semantic segmentation method. The, thus, obtained segmentation map is fed into a network to compute the extrapolated semantic segmentation and the corresponding panoptic segmentation maps. The input image and the obtained segmentation maps are further utilized to generate the final extrapolated image. We conduct experiments on Cityscapes and ADE20K-bedroom datasets and show that our method outperforms all baselines in terms of FID, and similarity in object co-occurrence statistics.
Halluci-Net: Scene Completion by Exploiting Object Co-occurrence Relationships
Apr 18, 2020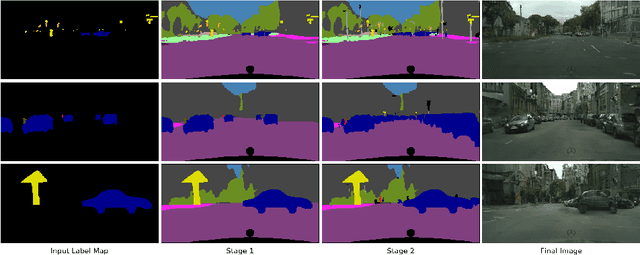

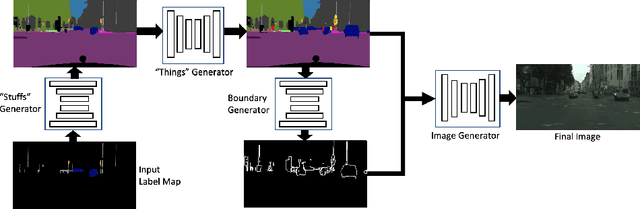

We address the new problem of complex scene completion from sparse label maps. We use a two-stage deep network based method, called `Halluci-Net', that uses object co-occurrence relationships to produce a dense and complete label map. The generated dense label map is fed into a state-of-the-art image synthesis method to obtain the final image. The proposed method is evaluated on the Cityscapes dataset and it outperforms a single-stage baseline method on various performance metrics like Fr\'echet Inception Distance (FID), semantic segmentation accuracy, and similarity in object co-occurrences. In addition to this, we show qualitative results on a subset of ADE20K dataset containing bedroom images.