 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage2Garment: Simulation-ready Garment Generation from a Single Image
Jan 15, 2026Estimating physically accurate, simulation-ready garments from a single image is challenging due to the absence of image-to-physics datasets and the ill-posed nature of this problem. Prior methods either require multi-view capture and expensive differentiable simulation or predict only garment geometry without the material properties required for realistic simulation. We propose a feed-forward framework that sidesteps these limitations by first fine-tuning a vision-language model to infer material composition and fabric attributes from real images, and then training a lightweight predictor that maps these attributes to the corresponding physical fabric parameters using a small dataset of material-physics measurements. Our approach introduces two new datasets (FTAG and T2P) and delivers simulation-ready garments from a single image without iterative optimization. Experiments show that our estimator achieves superior accuracy in material composition estimation and fabric attribute prediction, and by passing them through our physics parameter estimator, we further achieve higher-fidelity simulations compared to state-of-the-art image-to-garment methods.
Blowing in the Wind: CycleNet for Human Cinemagraphs from Still Images
Mar 15, 2023



Cinemagraphs are short looping videos created by adding subtle motions to a static image. This kind of media is popular and engaging. However, automatic generation of cinemagraphs is an underexplored area and current solutions require tedious low-level manual authoring by artists. In this paper, we present an automatic method that allows generating human cinemagraphs from single RGB images. We investigate the problem in the context of dressed humans under the wind. At the core of our method is a novel cyclic neural network that produces looping cinemagraphs for the target loop duration. To circumvent the problem of collecting real data, we demonstrate that it is possible, by working in the image normal space, to learn garment motion dynamics on synthetic data and generalize to real data. We evaluate our method on both synthetic and real data and demonstrate that it is possible to create compelling and plausible cinemagraphs from single RGB images.
Neural Cloth Simulation
Dec 13, 2022We present a general framework for the garment animation problem through unsupervised deep learning inspired in physically based simulation. Existing trends in the literature already explore this possibility. Nonetheless, these approaches do not handle cloth dynamics. Here, we propose the first methodology able to learn realistic cloth dynamics unsupervisedly, and henceforth, a general formulation for neural cloth simulation. The key to achieve this is to adapt an existing optimization scheme for motion from simulation based methodologies to deep learning. Then, analyzing the nature of the problem, we devise an architecture able to automatically disentangle static and dynamic cloth subspaces by design. We will show how this improves model performance. Additionally, this opens the possibility of a novel motion augmentation technique that greatly improves generalization. Finally, we show it also allows to control the level of motion in the predictions. This is a useful, never seen before, tool for artists. We provide of detailed analysis of the problem to establish the bases of neural cloth simulation and guide future research into the specifics of this domain.
Neural Implicit Surfaces for Efficient and Accurate Collisions in Physically Based Simulations
Oct 03, 2021



Current trends in the computer graphics community propose leveraging the massive parallel computational power of GPUs to accelerate physically based simulations. Collision detection and solving is a fundamental part of this process. It is also the most significant bottleneck on physically based simulations and it easily becomes intractable as the number of vertices in the scene increases. Brute force approaches carry a quadratic growth in both computational time and memory footprint. While their parallelization is trivial in GPUs, their complexity discourages from using such approaches. Acceleration structures -- such as BVH -- are often applied to increase performance, achieving logarithmic computational times for individual point queries. Nonetheless, their memory footprint also grows rapidly and their parallelization in a GPU is problematic due to their branching nature. We propose using implicit surface representations learnt through deep learning for collision handling in physically based simulations. Our proposed architecture has a complexity of O(n) -- or O(1) for a single point query -- and has no parallelization issues. We will show how this permits accurate and efficient collision handling in physically based simulations, more specifically, for cloth. In our experiments, we query up to 1M points in 300 milliseconds.
Deep unsupervised 3D human body reconstruction from a sparse set of landmarks
Jun 23, 2021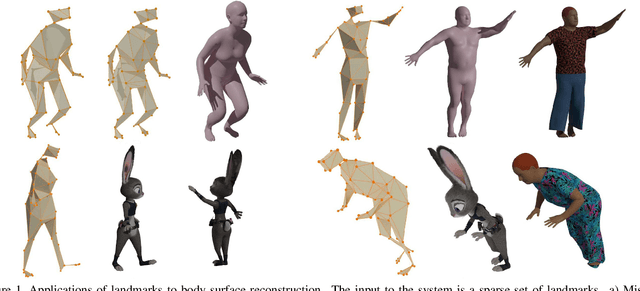
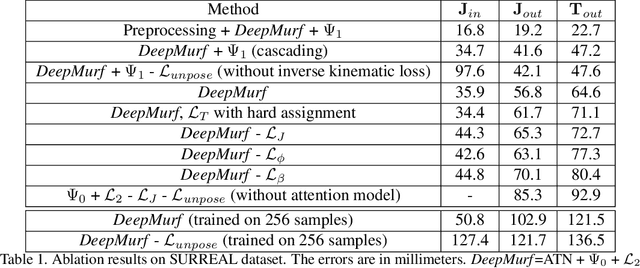
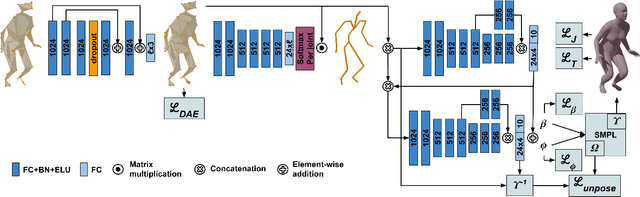

In this paper we propose the first deep unsupervised approach in human body reconstruction to estimate body surface from a sparse set of landmarks, so called DeepMurf. We apply a denoising autoencoder to estimate missing landmarks. Then we apply an attention model to estimate body joints from landmarks. Finally, a cascading network is applied to regress parameters of a statistical generative model that reconstructs body. Our set of proposed loss functions allows us to train the network in an unsupervised way. Results on four public datasets show that our approach accurately reconstructs the human body from real world mocap data.
PBNS: Physically Based Neural Simulator for Unsupervised Garment Pose Space Deformation
Jan 29, 2021
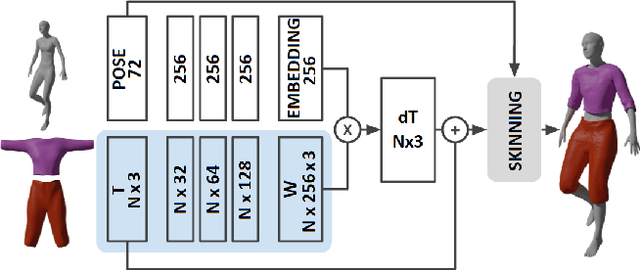

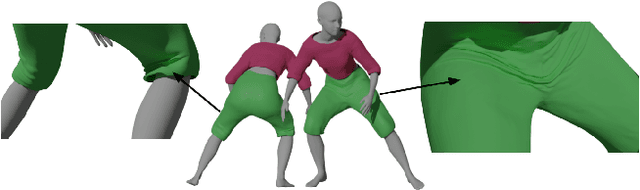
We present a methodology to automatically obtain Pose Space Deformation (PSD) basis for rigged garments through deep learning. Classical approaches rely on Physically Based Simulations (PBS) to animate clothes. These are general solutions that, given a sufficiently fine-grained discretization of space and time, can achieve highly realistic results. However, they are computationally expensive and any scene modification prompts the need of re-simulation. Linear Blend Skinning (LBS) with PSD offers a lightweight alternative to PBS, though, it needs huge volumes of data to learn proper PSD. We propose using deep learning, formulated as an implicit PBS, to unsupervisedly learn realistic cloth Pose Space Deformations in a constrained scenario: dressed humans. Furthermore, we show it is possible to train these models in an amount of time comparable to a PBS of a few sequences. To the best of our knowledge, we are the first to propose a neural simulator for cloth. While deep-based approaches in the domain are becoming a trend, these are data-hungry models. Moreover, authors often propose complex formulations to better learn wrinkles from PBS data. Dependency from data makes these solutions scalability lower, while their formulation hinders its applicability and compatibility. By proposing an unsupervised methodology to learn PSD for LBS models (3D animation standard), we overcome both of these drawbacks. Results obtained show cloth-consistency in the animated garments and meaningful pose-dependant folds and wrinkles.
DeePSD: Automatic Deep Skinning And Pose Space Deformation For 3D Garment Animation
Sep 06, 2020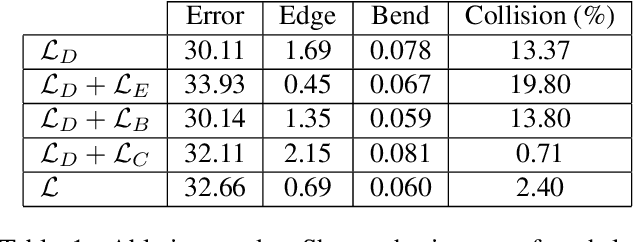
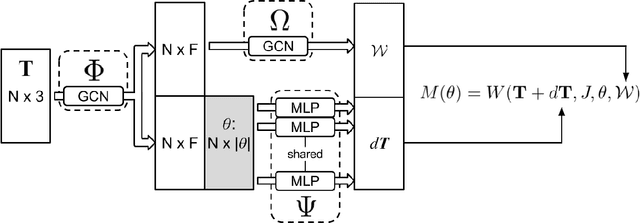

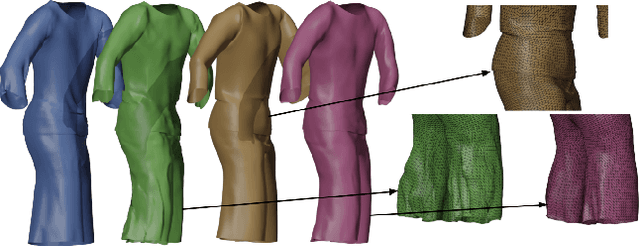
We present a novel approach to the garment animation problem through deep learning. Previous approaches propose learning a single model for one or few garment types, or alternatively, extend a human body model to represent multiple garment types. These works are not able to generalize to arbitrarily complex outfits we commonly find in real life. Our proposed methodology is able to work with any topology, complexity and multiple layers of cloth. Because of this, it is also able to generalize to completely unseen outfits with complex details. We design our model such that it can be efficiently deployed on portable devices and achieve real-time performance. Finally, we present an approach for unsupervised learning.
CLOTH3D: Clothed 3D Humans
Dec 05, 2019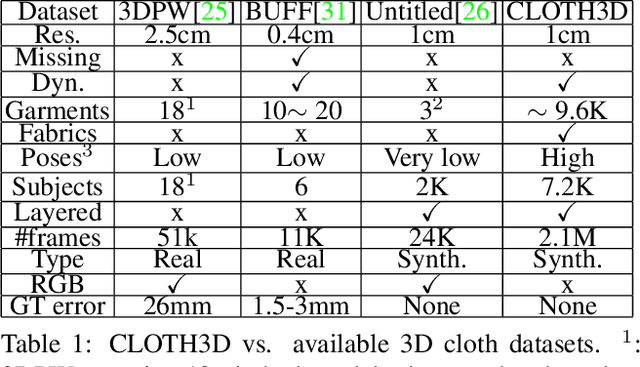

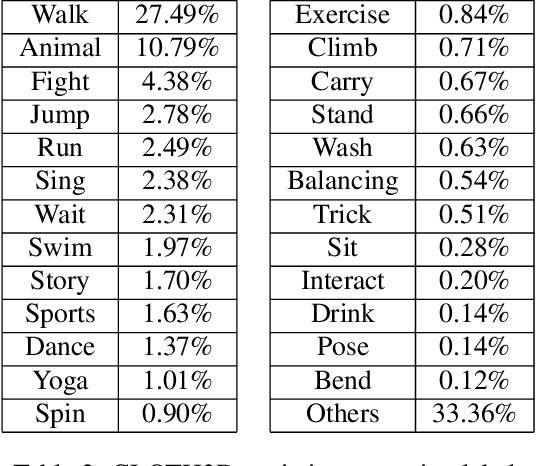

This work presents CLOTH3D, the first big scale synthetic dataset of 3D clothed human sequences. CLOTH3D contains a large variability on garment type, topology, shape, size, tightness and fabric. Clothes are simulated on top of thousands of different pose sequences and body shapes, generating realistic cloth dynamics. We provide the dataset with a generative model for cloth generation. We propose a Conditional Variational Auto-Encoder (CVAE) based on graph convolutions (GCVAE) to learn garment latent spaces. This allows for realistic generation of 3D garments on top of SMPL model for any pose and shape.
SMPLR: Deep SMPL reverse for 3D human pose and shape recovery
Dec 27, 2018
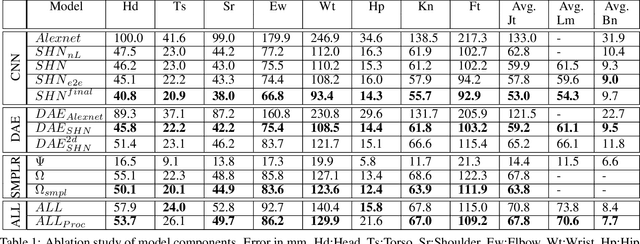
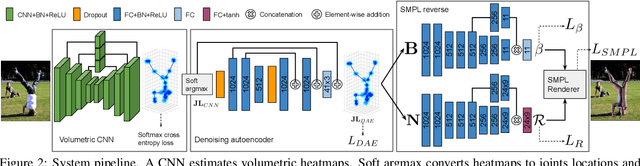
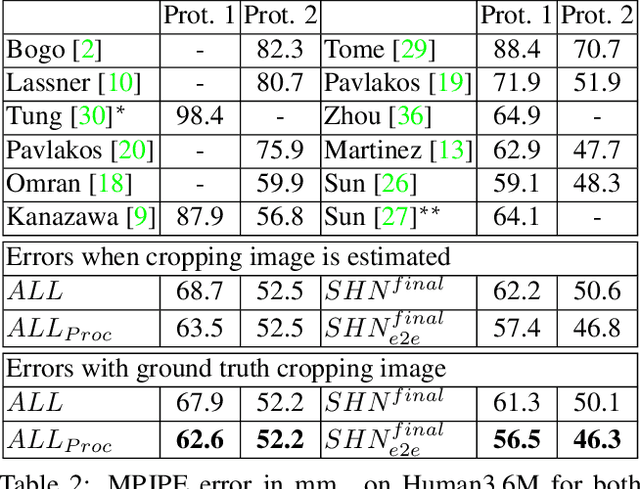
A recent trend in 3D human pose and shape estimation is to use deep learning and statistical morphable body models, such as the parametric Skinned Multi-Person Linear Model (SMPL). However, regardless of the advances in having both body pose and shape, SMPL-based solutions have shown difficulties on achieving accurate predictions. This is due to the unconstrained nature of SMPL, which allows unrealistic poses and shapes, hindering its direct regression or application on the training of deep models. In this paper we propose to embed SMPL within a deep model to efficiently estimate 3D pose and shape from a still RGB image. We use 3D joints as an intermediate representation to regress SMPL parameters which are again recovered as SMPL output. This module can be seen as an autoencoder where encoder is modeled by deep neural networks and decoder is modeled by SMPL. We refer to this procedure as SMPL reverse (SMPLR). Then, input 3D joints can be estimated by any convolutional neural network (CNN). To handle input noise to SMPLR, we propose a denoising autoencoder between CNN and SMPLR which is able to recover structured error. We evaluate our method on SURREAL and Human3.6M datasets showing significant improvement over SMPL-based state-of-the-art alternatives.