 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Virtual Try-Off? Dual-UNet Diffusion Model For Garment Reconstruction
Apr 09, 2026Virtual Try-On (VTON) has seen rapid advancements, providing a strong foundation for generative fashion tasks. However, the inverse problem, Virtual Try-Off (VTOFF)-aimed at reconstructing the canonical garment from a draped-on image-remains a less understood domain, distinct from the heavily researched field of VTON. In this work, we seek to establish a robust architectural foundation for VTOFF by studying and adapting various diffusion-based strategies from VTON and general Latent Diffusion Models (LDMs). We focus our investigation on the Dual-UNet Diffusion Model architecture and analyze three axes of design: (i) Generation Backbone: comparing Stable Diffusion variants; (ii) Conditioning: ablating different mask designs, masked/unmasked inputs for image conditioning, and the utility of high-level semantic features; and (iii) Losses and Training Strategies: evaluating the impact of the auxiliary attention-based loss, perceptual objectives and multi-stage curriculum schedules. Extensive experiments reveal trade-offs across various configuration options. Evaluated on VITON-HD and DressCode datasets, our framework achieves state-of-the-art performance with a drop of 9.5\% on the primary metric DISTS and competitive performance on LPIPS, FID, KID, and SSIM, providing both stronger baselines and insights to guide future Virtual Try-Off research.
MV-Fashion: Towards Enabling Virtual Try-On and Size Estimation with Multi-View Paired Data
Mar 09, 2026Existing 4D human datasets fall short for fashion-specific research, lacking either realistic garment dynamics or task-specific annotations. Synthetic datasets suffer from a realism gap, whereas real-world captures lack the detailed annotations and paired data required for virtual try-on (VTON) and size estimation tasks. To bridge this gap, we introduce MV-Fashion, a large-scale, multi-view video dataset engineered for domain-specific fashion analysis. MV-Fashion features 3,273 sequences (72.5 million frames) from 80 diverse subjects wearing 3-10 outfits each. It is designed to capture complex, real-world garment dynamics, including multiple layers and varied styling (e.g. rolled sleeves, tucked shirt). A core contribution is a rich data representation that includes pixel-level semantic annotations, ground-truth material properties like elasticity, and 3D point clouds. Crucially for VTON applications, MV-Fashion provides paired data: multi-view synchronized captures of worn garments alongside their corresponding flat, catalogue images. We leverage this dataset to establish baselines for fashion-centric tasks, including virtual try-on, clothing size estimation, and novel view synthesis. The dataset is available at https://hunorlaczko.github.io/MV-Fashion .
Multi-modal classification of forest biodiversity potential from 2D orthophotos and 3D airborne laser scanning point clouds
Jan 03, 2025
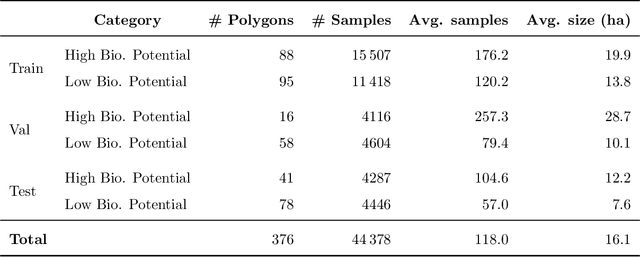
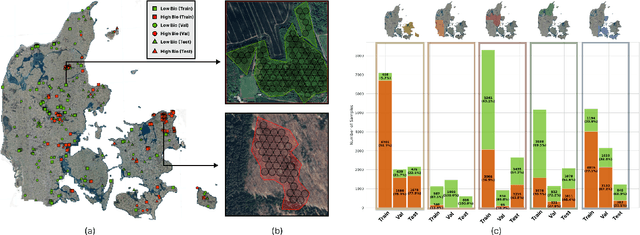
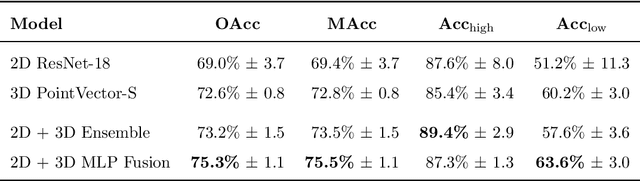
Accurate assessment of forest biodiversity is crucial for ecosystem management and conservation. While traditional field surveys provide high-quality assessments, they are labor-intensive and spatially limited. This study investigates whether deep learning-based fusion of close-range sensing data from 2D orthophotos (12.5 cm resolution) and 3D airborne laser scanning (ALS) point clouds (8 points/m^2) can enhance biodiversity assessment. We introduce the BioVista dataset, comprising 44.378 paired samples of orthophotos and ALS point clouds from temperate forests in Denmark, designed to explore multi-modal fusion approaches for biodiversity potential classification. Using deep neural networks (ResNet for orthophotos and PointVector for ALS point clouds), we investigate each data modality's ability to assess forest biodiversity potential, achieving mean accuracies of 69.4% and 72.8%, respectively. We explore two fusion approaches: a confidence-based ensemble method and a feature-level concatenation strategy, with the latter achieving a mean accuracy of 75.5%. Our results demonstrate that spectral information from orthophotos and structural information from ALS point clouds effectively complement each other in forest biodiversity assessment.
A Generative Multi-Resolution Pyramid and Normal-Conditioning 3D Cloth Draping
Nov 05, 2023RGB cloth generation has been deeply studied in the related literature, however, 3D garment generation remains an open problem. In this paper, we build a conditional variational autoencoder for 3D garment generation and draping. We propose a pyramid network to add garment details progressively in a canonical space, i.e. unposing and unshaping the garments w.r.t. the body. We study conditioning the network on surface normal UV maps, as an intermediate representation, which is an easier problem to optimize than 3D coordinates. Our results on two public datasets, CLOTH3D and CAPE, show that our model is robust, controllable in terms of detail generation by the use of multi-resolution pyramids, and achieves state-of-the-art results that can highly generalize to unseen garments, poses, and shapes even when training with small amounts of data.
Machine learning-based characterization of hydrochar from biomass: Implications for sustainable energy and material production
May 24, 2023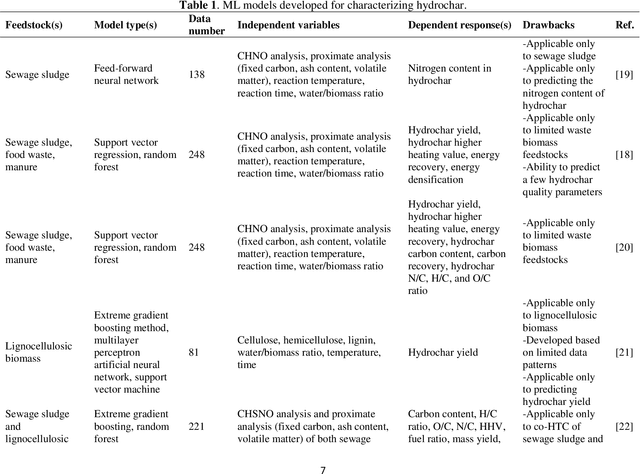


Hydrothermal carbonization (HTC) is a process that converts biomass into versatile hydrochar without the need for prior drying. The physicochemical properties of hydrochar are influenced by biomass properties and processing parameters, making it challenging to optimize for specific applications through trial-and-error experiments. To save time and money, machine learning can be used to develop a model that characterizes hydrochar produced from different biomass sources under varying reaction processing parameters. Thus, this study aims to develop an inclusive model to characterize hydrochar using a database covering a range of biomass types and reaction processing parameters. The quality and quantity of hydrochar are predicted using two models (decision tree regression and support vector regression). The decision tree regression model outperforms the support vector regression model in terms of forecast accuracy (R2 > 0.88, RMSE < 6.848, and MAE < 4.718). Using an evolutionary algorithm, optimum inputs are identified based on cost functions provided by the selected model to optimize hydrochar for energy production, soil amendment, and pollutant adsorption, resulting in hydrochar yields of 84.31%, 84.91%, and 80.40%, respectively. The feature importance analysis reveals that biomass ash/carbon content and operating temperature are the primary factors affecting hydrochar production in the HTC process.
Blowing in the Wind: CycleNet for Human Cinemagraphs from Still Images
Mar 15, 2023



Cinemagraphs are short looping videos created by adding subtle motions to a static image. This kind of media is popular and engaging. However, automatic generation of cinemagraphs is an underexplored area and current solutions require tedious low-level manual authoring by artists. In this paper, we present an automatic method that allows generating human cinemagraphs from single RGB images. We investigate the problem in the context of dressed humans under the wind. At the core of our method is a novel cyclic neural network that produces looping cinemagraphs for the target loop duration. To circumvent the problem of collecting real data, we demonstrate that it is possible, by working in the image normal space, to learn garment motion dynamics on synthetic data and generalize to real data. We evaluate our method on both synthetic and real data and demonstrate that it is possible to create compelling and plausible cinemagraphs from single RGB images.
Neural Cloth Simulation
Dec 13, 2022We present a general framework for the garment animation problem through unsupervised deep learning inspired in physically based simulation. Existing trends in the literature already explore this possibility. Nonetheless, these approaches do not handle cloth dynamics. Here, we propose the first methodology able to learn realistic cloth dynamics unsupervisedly, and henceforth, a general formulation for neural cloth simulation. The key to achieve this is to adapt an existing optimization scheme for motion from simulation based methodologies to deep learning. Then, analyzing the nature of the problem, we devise an architecture able to automatically disentangle static and dynamic cloth subspaces by design. We will show how this improves model performance. Additionally, this opens the possibility of a novel motion augmentation technique that greatly improves generalization. Finally, we show it also allows to control the level of motion in the predictions. This is a useful, never seen before, tool for artists. We provide of detailed analysis of the problem to establish the bases of neural cloth simulation and guide future research into the specifics of this domain.
Towards explaining the generalization gap in neural networks using topological data analysis
Mar 23, 2022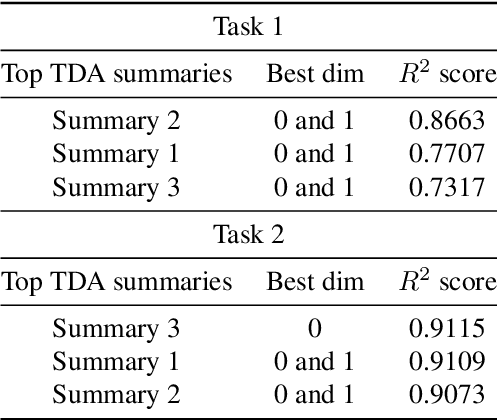
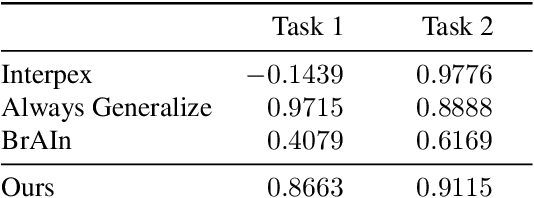
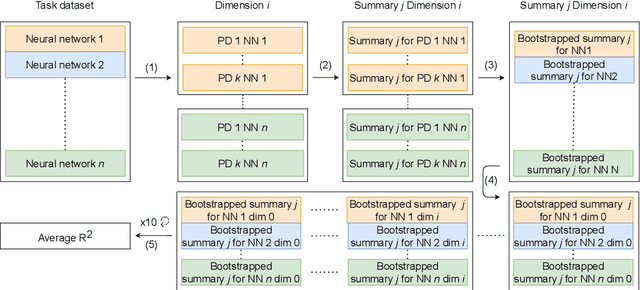
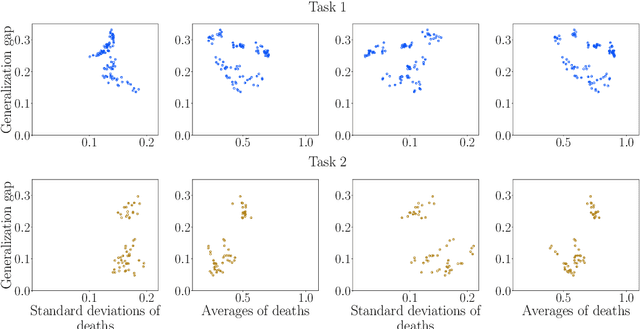
Understanding how neural networks generalize on unseen data is crucial for designing more robust and reliable models. In this paper, we study the generalization gap of neural networks using methods from topological data analysis. For this purpose, we compute homological persistence diagrams of weighted graphs constructed from neuron activation correlations after a training phase, aiming to capture patterns that are linked to the generalization capacity of the network. We compare the usefulness of different numerical summaries from persistence diagrams and show that a combination of some of them can accurately predict and partially explain the generalization gap without the need of a test set. Evaluation on two computer vision recognition tasks (CIFAR10 and SVHN) shows competitive generalization gap prediction when compared against state-of-the-art methods.
Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019
Jan 11, 2022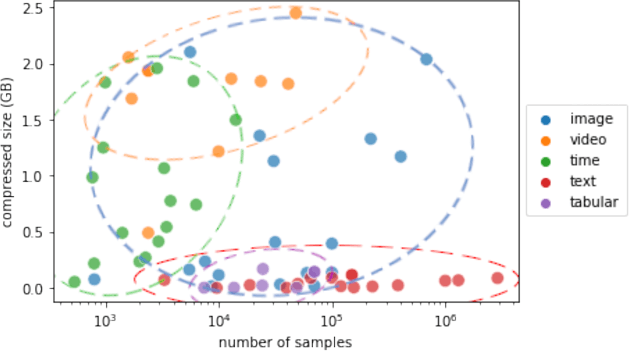
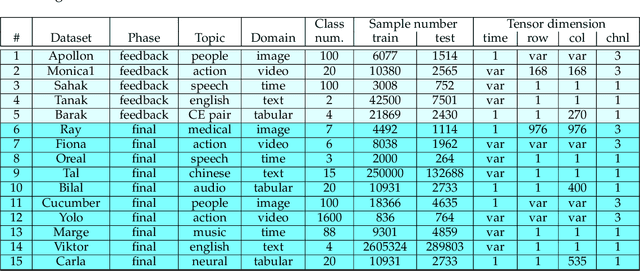
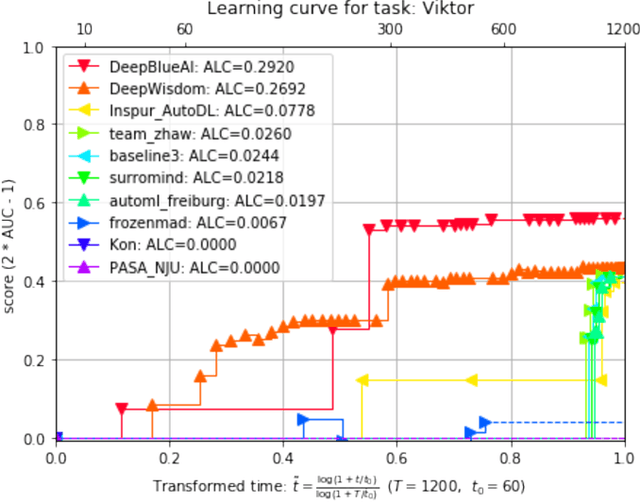
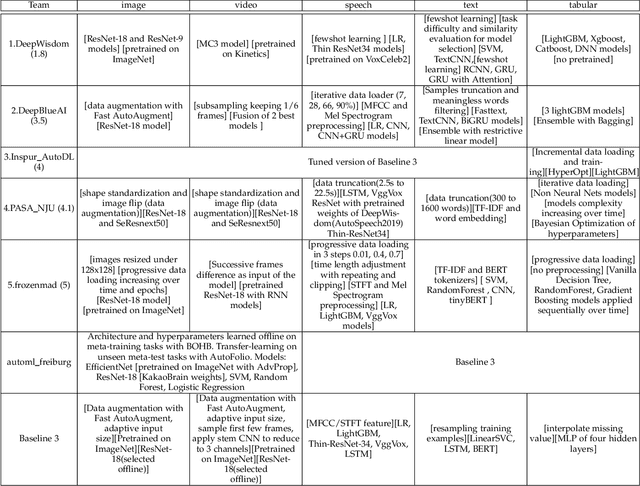
This paper reports the results and post-challenge analyses of ChaLearn's AutoDL challenge series, which helped sorting out a profusion of AutoML solutions for Deep Learning (DL) that had been introduced in a variety of settings, but lacked fair comparisons. All input data modalities (time series, images, videos, text, tabular) were formatted as tensors and all tasks were multi-label classification problems. Code submissions were executed on hidden tasks, with limited time and computational resources, pushing solutions that get results quickly. In this setting, DL methods dominated, though popular Neural Architecture Search (NAS) was impractical. Solutions relied on fine-tuned pre-trained networks, with architectures matching data modality. Post-challenge tests did not reveal improvements beyond the imposed time limit. While no component is particularly original or novel, a high level modular organization emerged featuring a "meta-learner", "data ingestor", "model selector", "model/learner", and "evaluator". This modularity enabled ablation studies, which revealed the importance of (off-platform) meta-learning, ensembling, and efficient data management. Experiments on heterogeneous module combinations further confirm the (local) optimality of the winning solutions. Our challenge legacy includes an ever-lasting benchmark (http://autodl.chalearn.org), the open-sourced code of the winners, and a free "AutoDL self-service".
* The first three authors contributed equally; This is only a draft version
Multi-Task Classification of Sewer Pipe Defects and Properties using a Cross-Task Graph Neural Network Decoder
Nov 15, 2021
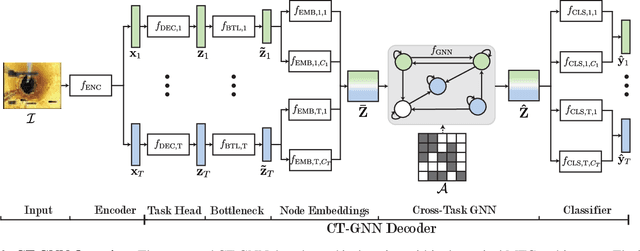

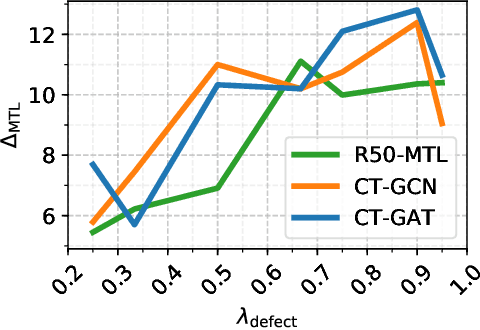
The sewerage infrastructure is one of the most important and expensive infrastructures in modern society. In order to efficiently manage the sewerage infrastructure, automated sewer inspection has to be utilized. However, while sewer defect classification has been investigated for decades, little attention has been given to classifying sewer pipe properties such as water level, pipe material, and pipe shape, which are needed to evaluate the level of sewer pipe deterioration. In this work we classify sewer pipe defects and properties concurrently and present a novel decoder-focused multi-task classification architecture Cross-Task Graph Neural Network (CT-GNN), which refines the disjointed per-task predictions using cross-task information. The CT-GNN architecture extends the traditional disjointed task-heads decoder, by utilizing a cross-task graph and unique class node embeddings. The cross-task graph can either be determined a priori based on the conditional probability between the task classes or determined dynamically using self-attention. CT-GNN can be added to any backbone and trained end-to-end at a small increase in the parameter count. We achieve state-of-the-art performance on all four classification tasks in the Sewer-ML dataset, improving defect classification and water level classification by 5.3 and 8.0 percentage points, respectively. We also outperform the single task methods as well as other multi-task classification approaches while introducing 50 times fewer parameters than previous model-focused approaches. The code and models are available at the project page http://vap.aau.dk/ctgnn