 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning hazardous volatile matter compounds into fuel by catalytic steam reforming: An evolutionary machine learning approach
Jul 25, 2023Chemical and biomass processing systems release volatile matter compounds into the environment daily. Catalytic reforming can convert these compounds into valuable fuels, but developing stable and efficient catalysts is challenging. Machine learning can handle complex relationships in big data and optimize reaction conditions, making it an effective solution for addressing the mentioned issues. This study is the first to develop a machine-learning-based research framework for modeling, understanding, and optimizing the catalytic steam reforming of volatile matter compounds. Toluene catalytic steam reforming is used as a case study to show how chemical/textural analyses (e.g., X-ray diffraction analysis) can be used to obtain input features for machine learning models. Literature is used to compile a database covering a variety of catalyst characteristics and reaction conditions. The process is thoroughly analyzed, mechanistically discussed, modeled by six machine learning models, and optimized using the particle swarm optimization algorithm. Ensemble machine learning provides the best prediction performance (R2 > 0.976) for toluene conversion and product distribution. The optimal tar conversion (higher than 77.2%) is obtained at temperatures between 637.44 and 725.62 {\deg}C, with a steam-to-carbon molar ratio of 5.81-7.15 and a catalyst BET surface area 476.03-638.55 m2/g. The feature importance analysis satisfactorily reveals the effects of input descriptors on model prediction. Operating conditions (50.9%) and catalyst properties (49.1%) are equally important in modeling. The developed framework can expedite the search for optimal catalyst characteristics and reaction conditions, not only for catalytic chemical processing but also for related research areas.
Using evolutionary machine learning to characterize and optimize co-pyrolysis of biomass feedstocks and polymeric wastes
May 24, 2023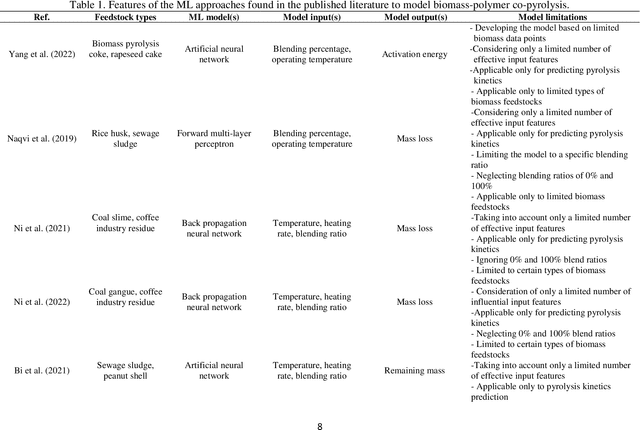
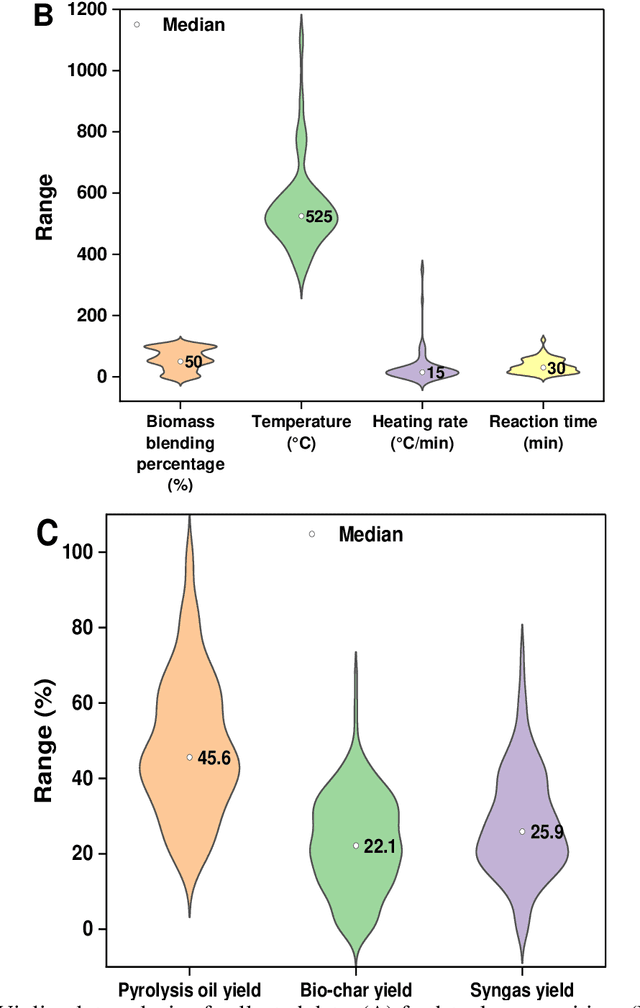

Co-pyrolysis of biomass feedstocks with polymeric wastes is a promising strategy for improving the quantity and quality parameters of the resulting liquid fuel. Numerous experimental measurements are typically conducted to find the optimal operating conditions. However, performing co-pyrolysis experiments is highly challenging due to the need for costly and lengthy procedures. Machine learning (ML) provides capabilities to cope with such issues by leveraging on existing data. This work aims to introduce an evolutionary ML approach to quantify the (by)products of the biomass-polymer co-pyrolysis process. A comprehensive dataset covering various biomass-polymer mixtures under a broad range of process conditions is compiled from the qualified literature. The database was subjected to statistical analysis and mechanistic discussion. The input features are constructed using an innovative approach to reflect the physics of the process. The constructed features are subjected to principal component analysis to reduce their dimensionality. The obtained scores are introduced into six ML models. Gaussian process regression model tuned by particle swarm optimization algorithm presents better prediction performance (R2 > 0.9, MAE < 0.03, and RMSE < 0.06) than other developed models. The multi-objective particle swarm optimization algorithm successfully finds optimal independent parameters.
Machine learning-based characterization of hydrochar from biomass: Implications for sustainable energy and material production
May 24, 2023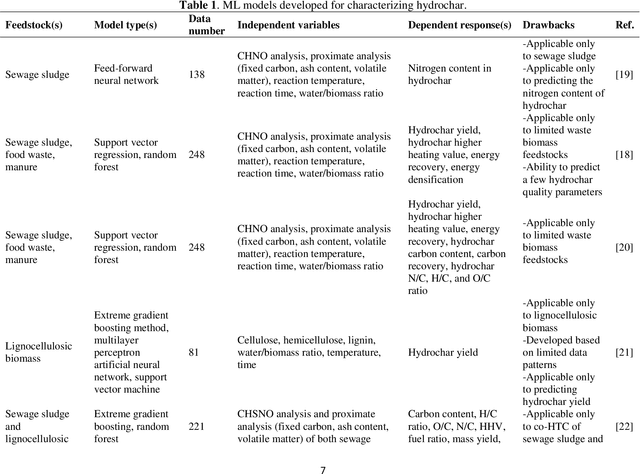
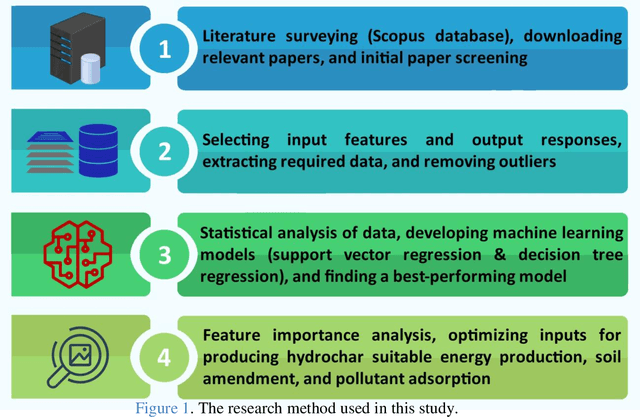


Hydrothermal carbonization (HTC) is a process that converts biomass into versatile hydrochar without the need for prior drying. The physicochemical properties of hydrochar are influenced by biomass properties and processing parameters, making it challenging to optimize for specific applications through trial-and-error experiments. To save time and money, machine learning can be used to develop a model that characterizes hydrochar produced from different biomass sources under varying reaction processing parameters. Thus, this study aims to develop an inclusive model to characterize hydrochar using a database covering a range of biomass types and reaction processing parameters. The quality and quantity of hydrochar are predicted using two models (decision tree regression and support vector regression). The decision tree regression model outperforms the support vector regression model in terms of forecast accuracy (R2 > 0.88, RMSE < 6.848, and MAE < 4.718). Using an evolutionary algorithm, optimum inputs are identified based on cost functions provided by the selected model to optimize hydrochar for energy production, soil amendment, and pollutant adsorption, resulting in hydrochar yields of 84.31%, 84.91%, and 80.40%, respectively. The feature importance analysis reveals that biomass ash/carbon content and operating temperature are the primary factors affecting hydrochar production in the HTC process.