 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-Fashion: Towards Enabling Virtual Try-On and Size Estimation with Multi-View Paired Data
Mar 09, 2026Existing 4D human datasets fall short for fashion-specific research, lacking either realistic garment dynamics or task-specific annotations. Synthetic datasets suffer from a realism gap, whereas real-world captures lack the detailed annotations and paired data required for virtual try-on (VTON) and size estimation tasks. To bridge this gap, we introduce MV-Fashion, a large-scale, multi-view video dataset engineered for domain-specific fashion analysis. MV-Fashion features 3,273 sequences (72.5 million frames) from 80 diverse subjects wearing 3-10 outfits each. It is designed to capture complex, real-world garment dynamics, including multiple layers and varied styling (e.g. rolled sleeves, tucked shirt). A core contribution is a rich data representation that includes pixel-level semantic annotations, ground-truth material properties like elasticity, and 3D point clouds. Crucially for VTON applications, MV-Fashion provides paired data: multi-view synchronized captures of worn garments alongside their corresponding flat, catalogue images. We leverage this dataset to establish baselines for fashion-centric tasks, including virtual try-on, clothing size estimation, and novel view synthesis. The dataset is available at https://hunorlaczko.github.io/MV-Fashion .
EarthView: A Large Scale Remote Sensing Dataset for Self-Supervision
Jan 14, 2025This paper presents EarthView, a comprehensive dataset specifically designed for self-supervision on remote sensing data, intended to enhance deep learning applications on Earth monitoring tasks. The dataset spans 15 tera pixels of global remote-sensing data, combining imagery from a diverse range of sources, including NEON, Sentinel, and a novel release of 1m spatial resolution data from Satellogic. Our dataset provides a wide spectrum of image data with varying resolutions, harnessed from different sensors and organized coherently into an accessible HuggingFace dataset in parquet format. This data spans five years, from 2017 to 2022. Accompanying the dataset, we introduce EarthMAE, a tailored Masked Autoencoder, developed to tackle the distinct challenges of remote sensing data. Trained in a self-supervised fashion, EarthMAE effectively processes different data modalities such as hyperspectral, multispectral, topographical data, segmentation maps, and temporal structure. This model helps us show that pre-training on Satellogic data improves performance on downstream tasks. While there is still a gap to fill in MAE for heterogeneous data, we regard this innovative combination of an expansive, diverse dataset and a versatile model adapted for self-supervised learning as a stride forward in deep learning for Earth monitoring.
A Generative Multi-Resolution Pyramid and Normal-Conditioning 3D Cloth Draping
Nov 05, 2023RGB cloth generation has been deeply studied in the related literature, however, 3D garment generation remains an open problem. In this paper, we build a conditional variational autoencoder for 3D garment generation and draping. We propose a pyramid network to add garment details progressively in a canonical space, i.e. unposing and unshaping the garments w.r.t. the body. We study conditioning the network on surface normal UV maps, as an intermediate representation, which is an easier problem to optimize than 3D coordinates. Our results on two public datasets, CLOTH3D and CAPE, show that our model is robust, controllable in terms of detail generation by the use of multi-resolution pyramids, and achieves state-of-the-art results that can highly generalize to unseen garments, poses, and shapes even when training with small amounts of data.
Hierarchical Residual Attention Network for Single Image Super-Resolution
Dec 08, 2020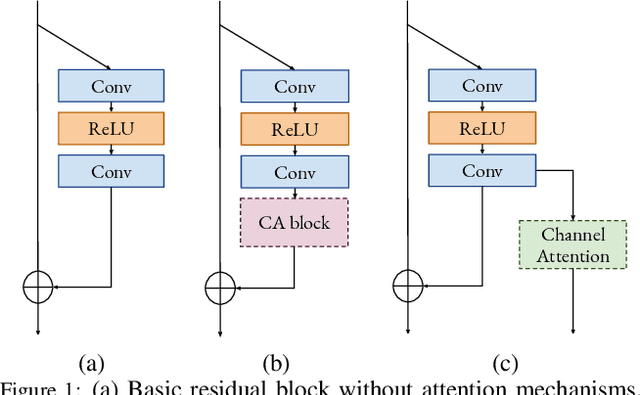
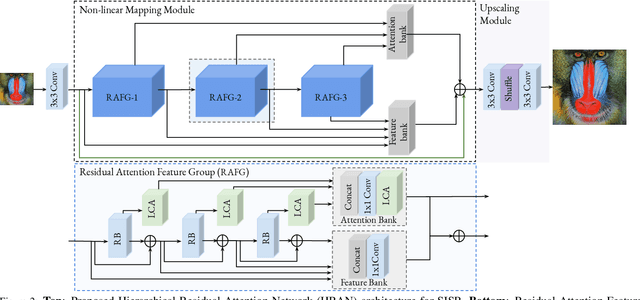
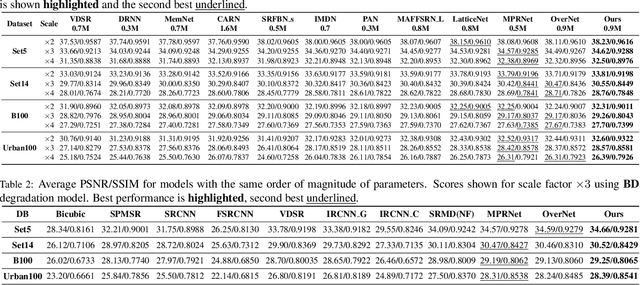
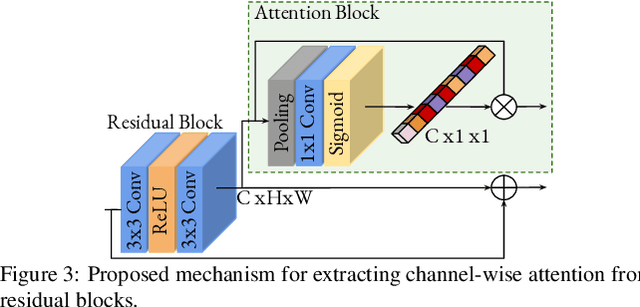
Convolutional neural networks are the most successful models in single image super-resolution. Deeper networks, residual connections, and attention mechanisms have further improved their performance. However, these strategies often improve the reconstruction performance at the expense of considerably increasing the computational cost. This paper introduces a new lightweight super-resolution model based on an efficient method for residual feature and attention aggregation. In order to make an efficient use of the residual features, these are hierarchically aggregated into feature banks for posterior usage at the network output. In parallel, a lightweight hierarchical attention mechanism extracts the most relevant features from the network into attention banks for improving the final output and preventing the information loss through the successive operations inside the network. Therefore, the processing is split into two independent paths of computation that can be simultaneously carried out, resulting in a highly efficient and effective model for reconstructing fine details on high-resolution images from their low-resolution counterparts. Our proposed architecture surpasses state-of-the-art performance in several datasets, while maintaining relatively low computation and memory footprint.
OverNet: Lightweight Multi-Scale Super-Resolution with Overscaling Network
Aug 05, 2020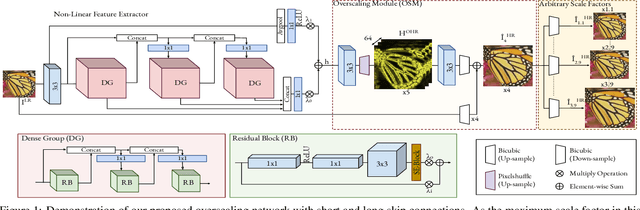



Super-resolution (SR) has achieved great success due to the development of deep convolutional neural networks (CNNs). However, as the depth and width of the networks increase, CNN-based SR methods have been faced with the challenge of computational complexity in practice. Moreover, most of them train a dedicated model for each target resolution, losing generality and increasing memory requirements. To address these limitations we introduce OverNet, a deep but lightweight convolutional network to solve SISR at arbitrary scale factors with a single model. We make the following contributions: first, we introduce a lightweight recursive feature extractor that enforces efficient reuse of information through a novel recursive structure of skip and dense connections. Second, to maximize the performance of the feature extractor we propose a reconstruction module that generates accurate high-resolution images from overscaled feature maps and can be independently used to improve existing architectures. Third, we introduce a multi-scale loss function to achieve generalization across scales. Through extensive experiments, we demonstrate that our network outperforms previous state-of-the-art results in standard benchmarks while using fewer parameters than previous approaches.
From 2D to 3D Geodesic-based Garment Matching
Sep 21, 2018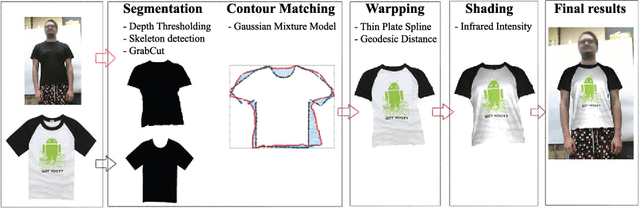

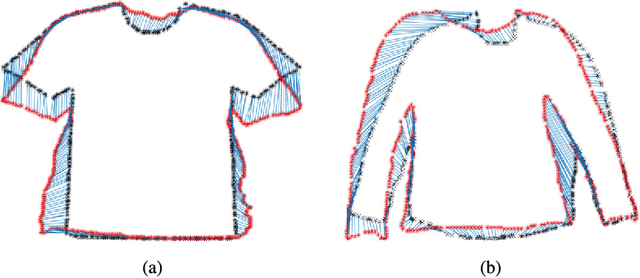
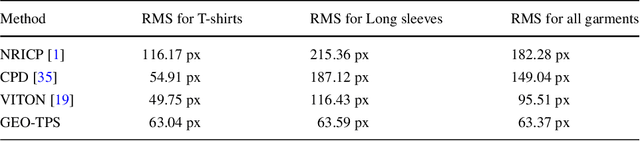
A new approach for 2D to 3D garment retexturing is proposed based on Gaussian mixture models and thin plate splines (TPS). An automatically segmented garment of an individual is matched to a new source garment and rendered, resulting in augmented images in which the target garment has been retextured by using the texture of the source garment. We divide the problem into garment boundary matching based on Gaussian mixture models and then interpolate inner points using surface topology extracted through geodesic paths, which leads to a more realistic result than standard approaches. We evaluated and compared our system quantitatively by mean square error (MSE) and qualitatively using the mean opinion score (MOS), showing the benefits of the proposed methodology on our gathered dataset.
End-to-end Global to Local CNN Learning for Hand Pose Recovery in Depth Data
Apr 11, 2018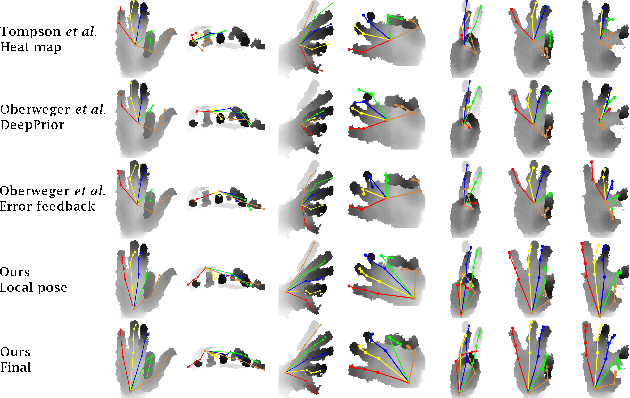

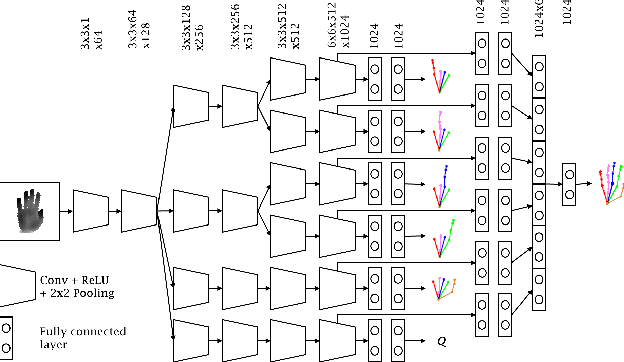

Despite recent advances in 3D pose estimation of human hands, especially thanks to the advent of CNNs and depth cameras, this task is still far from being solved. This is mainly due to the highly non-linear dynamics of fingers, which make hand model training a challenging task. In this paper, we exploit a novel hierarchical tree-like structured CNN, in which branches are trained to become specialized in predefined subsets of hand joints, called local poses. We further fuse local pose features, extracted from hierarchical CNN branches, to learn higher order dependencies among joints in the final pose by end-to-end training. Lastly, the loss function used is also defined to incorporate appearance and physical constraints about doable hand motion and deformation. Finally, we introduce a non-rigid data augmentation approach to increase the amount of training depth data. Experimental results suggest that feeding a tree-shaped CNN, specialized in local poses, into a fusion network for modeling joints correlations and dependencies, helps to increase the precision of final estimations, outperforming state-of-the-art results on NYU and SyntheticHand datasets.
Enhanced Mixtures of Part Model for Human Pose Estimation
Jan 28, 2015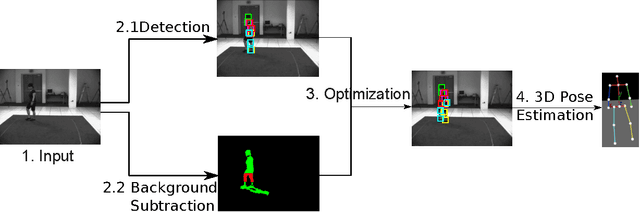
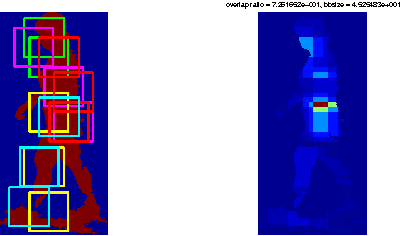
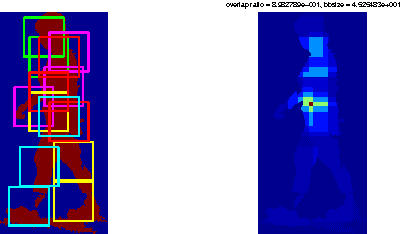

Mixture of parts model has been successfully applied to 2D human pose estimation problem either as explicitly trained body part model or as latent variables for the whole human body model. Mixture of parts model usually utilize tree structure for representing relations between body parts. Tree structures facilitate training and referencing of the model but could not deal with double counting problems, which hinder its applications in 3D pose estimation. While most of work targeted to solve these problems tend to modify the tree models or the optimization target. We incorporate other cues from input features. For example, in surveillance environments, human silhouettes can be extracted relative easily although not flawlessly. In this condition, we can combine extracted human blobs with histogram of gradient feature, which is commonly used in mixture of parts model for training body part templates. The method can be easily extend to other candidate features under our generalized framework. We show 2D body part detection results on a public available dataset: HumanEva dataset. Furthermore, a 2D to 3D pose estimator is trained with Gaussian process regression model and 2D body part detections from the proposed method is fed to the estimator, thus 3D poses are predictable given new 2D body part detections. We also show results of 3D pose estimation on HumanEva dataset.