 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Autoencoders are Capable LLM Jailbreak Mitigators
Feb 12, 2026Jailbreak attacks remain a persistent threat to large language model safety. We propose Context-Conditioned Delta Steering (CC-Delta), an SAE-based defense that identifies jailbreak-relevant sparse features by comparing token-level representations of the same harmful request with and without jailbreak context. Using paired harmful/jailbreak prompts, CC-Delta selects features via statistical testing and applies inference-time mean-shift steering in SAE latent space. Across four aligned instruction-tuned models and twelve jailbreak attacks, CC-Delta achieves comparable or better safety-utility tradeoffs than baseline defenses operating in dense latent space. In particular, our method clearly outperforms dense mean-shift steering on all four models, and particularly against out-of-distribution attacks, showing that steering in sparse SAE feature space offers advantages over steering in dense activation space for jailbreak mitigation. Our results suggest off-the-shelf SAEs trained for interpretability can be repurposed as practical jailbreak defenses without task-specific training.
GenCtrl -- A Formal Controllability Toolkit for Generative Models
Jan 09, 2026As generative models become ubiquitous, there is a critical need for fine-grained control over the generation process. Yet, while controlled generation methods from prompting to fine-tuning proliferate, a fundamental question remains unanswered: are these models truly controllable in the first place? In this work, we provide a theoretical framework to formally answer this question. Framing human-model interaction as a control process, we propose a novel algorithm to estimate the controllable sets of models in a dialogue setting. Notably, we provide formal guarantees on the estimation error as a function of sample complexity: we derive probably-approximately correct bounds for controllable set estimates that are distribution-free, employ no assumptions except for output boundedness, and work for any black-box nonlinear control system (i.e., any generative model). We empirically demonstrate the theoretical framework on different tasks in controlling dialogue processes, for both language models and text-to-image generation. Our results show that model controllability is surprisingly fragile and highly dependent on the experimental setting. This highlights the need for rigorous controllability analysis, shifting the focus from simply attempting control to first understanding its fundamental limits.
ParaRNN: Unlocking Parallel Training of Nonlinear RNNs for Large Language Models
Oct 24, 2025Recurrent Neural Networks (RNNs) laid the foundation for sequence modeling, but their intrinsic sequential nature restricts parallel computation, creating a fundamental barrier to scaling. This has led to the dominance of parallelizable architectures like Transformers and, more recently, State Space Models (SSMs). While SSMs achieve efficient parallelization through structured linear recurrences, this linearity constraint limits their expressive power and precludes modeling complex, nonlinear sequence-wise dependencies. To address this, we present ParaRNN, a framework that breaks the sequence-parallelization barrier for nonlinear RNNs. Building on prior work, we cast the sequence of nonlinear recurrence relationships as a single system of equations, which we solve in parallel using Newton's iterations combined with custom parallel reductions. Our implementation achieves speedups of up to 665x over naive sequential application, allowing training nonlinear RNNs at unprecedented scales. To showcase this, we apply ParaRNN to adaptations of LSTM and GRU architectures, successfully training models of 7B parameters that attain perplexity comparable to similarly-sized Transformers and Mamba2 architectures. To accelerate research in efficient sequence modeling, we release the ParaRNN codebase as an open-source framework for automatic training-parallelization of nonlinear RNNs, enabling researchers and practitioners to explore new nonlinear RNN models at scale.
Understanding Input Selectivity in Mamba: Impact on Approximation Power, Memorization, and Associative Recall Capacity
Jun 13, 2025State-Space Models (SSMs), and particularly Mamba, have recently emerged as a promising alternative to Transformers. Mamba introduces input selectivity to its SSM layer (S6) and incorporates convolution and gating into its block definition. While these modifications do improve Mamba's performance over its SSM predecessors, it remains largely unclear how Mamba leverages the additional functionalities provided by input selectivity, and how these interact with the other operations in the Mamba architecture. In this work, we demystify the role of input selectivity in Mamba, investigating its impact on function approximation power, long-term memorization, and associative recall capabilities. In particular: (i) we prove that the S6 layer of Mamba can represent projections onto Haar wavelets, providing an edge over its Diagonal SSM (S4D) predecessor in approximating discontinuous functions commonly arising in practice; (ii) we show how the S6 layer can dynamically counteract memory decay; (iii) we provide analytical solutions to the MQAR associative recall task using the Mamba architecture with different mixers -- Mamba, Mamba-2, and S4D. We demonstrate the tightness of our theoretical constructions with empirical results on concrete tasks. Our findings offer a mechanistic understanding of Mamba and reveal opportunities for improvement.
Controlling Language and Diffusion Models by Transporting Activations
Oct 30, 2024



The increasing capabilities of large generative models and their ever more widespread deployment have raised concerns about their reliability, safety, and potential misuse. To address these issues, recent works have proposed to control model generation by steering model activations in order to effectively induce or prevent the emergence of concepts or behaviors in the generated output. In this paper we introduce Activation Transport (AcT), a general framework to steer activations guided by optimal transport theory that generalizes many previous activation-steering works. AcT is modality-agnostic and provides fine-grained control over the model behavior with negligible computational overhead, while minimally impacting model abilities. We experimentally show the effectiveness and versatility of our approach by addressing key challenges in large language models (LLMs) and text-to-image diffusion models (T2Is). For LLMs, we show that AcT can effectively mitigate toxicity, induce arbitrary concepts, and increase their truthfulness. In T2Is, we show how AcT enables fine-grained style control and concept negation.
StarVector: Generating Scalable Vector Graphics Code from Images
Dec 17, 2023


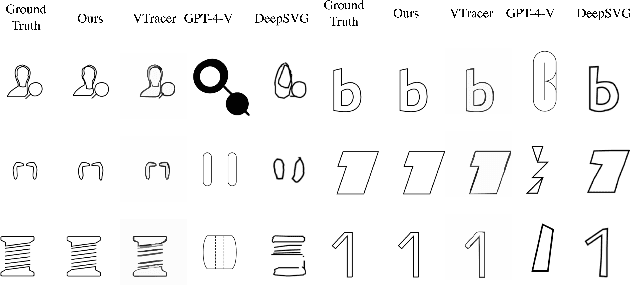
Scalable Vector Graphics (SVGs) have become integral in modern image rendering applications due to their infinite scalability in resolution, versatile usability, and editing capabilities. SVGs are particularly popular in the fields of web development and graphic design. Existing approaches for SVG modeling using deep learning often struggle with generating complex SVGs and are restricted to simpler ones that require extensive processing and simplification. This paper introduces StarVector, a multimodal SVG generation model that effectively integrates Code Generation Large Language Models (CodeLLMs) and vision models. Our approach utilizes a CLIP image encoder to extract visual representations from pixel-based images, which are then transformed into visual tokens via an adapter module. These visual tokens are pre-pended to the SVG token embeddings, and the sequence is modeled by the StarCoder model using next-token prediction, effectively learning to align the visual and code tokens. This enables StarVector to generate unrestricted SVGs that accurately represent pixel images. To evaluate StarVector's performance, we present SVG-Bench, a comprehensive benchmark for evaluating SVG methods across multiple datasets and relevant metrics. Within this benchmark, we introduce novel datasets including SVG-Stack, a large-scale dataset of real-world SVG examples, and use it to pre-train StarVector as a large foundation model for SVGs. Our results demonstrate significant enhancements in visual quality and complexity handling over current methods, marking a notable advancement in SVG generation technology. Code and models: https://github.com/joanrod/star-vector
Continual Learning of Diffusion Models with Generative Distillation
Nov 23, 2023Diffusion models are powerful generative models that achieve state-of-the-art performance in tasks such as image synthesis. However, training them demands substantial amounts of data and computational resources. Continual learning would allow for incrementally learning new tasks and accumulating knowledge, thus reusing already trained models would be possible. One potentially suitable approach is generative replay, where a copy of a generative model trained on previous tasks produces synthetic data that are interleaved with data from the current task. However, standard generative replay applied to diffusion models results in a catastrophic loss in denoising capabilities. In this paper, we propose generative distillation, an approach that distils the entire reverse process of a diffusion model. We demonstrate that our approach significantly improves the continual learning performance of generative replay with only a moderate increase in the computational costs.
Group Robust Classification Without Any Group Information
Oct 28, 2023



Empirical risk minimization (ERM) is sensitive to spurious correlations in the training data, which poses a significant risk when deploying systems trained under this paradigm in high-stake applications. While the existing literature focuses on maximizing group-balanced or worst-group accuracy, estimating these accuracies is hindered by costly bias annotations. This study contends that current bias-unsupervised approaches to group robustness continue to rely on group information to achieve optimal performance. Firstly, these methods implicitly assume that all group combinations are represented during training. To illustrate this, we introduce a systematic generalization task on the MPI3D dataset and discover that current algorithms fail to improve the ERM baseline when combinations of observed attribute values are missing. Secondly, bias labels are still crucial for effective model selection, restricting the practicality of these methods in real-world scenarios. To address these limitations, we propose a revised methodology for training and validating debiased models in an entirely bias-unsupervised manner. We achieve this by employing pretrained self-supervised models to reliably extract bias information, which enables the integration of a logit adjustment training loss with our validation criterion. Our empirical analysis on synthetic and real-world tasks provides evidence that our approach overcomes the identified challenges and consistently enhances robust accuracy, attaining performance which is competitive with or outperforms that of state-of-the-art methods, which, conversely, rely on bias labels for validation.
OC-NMN: Object-centric Compositional Neural Module Network for Generative Visual Analogical Reasoning
Oct 28, 2023A key aspect of human intelligence is the ability to imagine -- composing learned concepts in novel ways -- to make sense of new scenarios. Such capacity is not yet attained for machine learning systems. In this work, in the context of visual reasoning, we show how modularity can be leveraged to derive a compositional data augmentation framework inspired by imagination. Our method, denoted Object-centric Compositional Neural Module Network (OC-NMN), decomposes visual generative reasoning tasks into a series of primitives applied to objects without using a domain-specific language. We show that our modular architectural choices can be used to generate new training tasks that lead to better out-of-distribution generalization. We compare our model to existing and new baselines in proposed visual reasoning benchmark that consists of applying arithmetic operations to MNIST digits.
FigGen: Text to Scientific Figure Generation
Jun 21, 2023



The generative modeling landscape has experienced tremendous growth in recent years, particularly in generating natural images and art. Recent techniques have shown impressive potential in creating complex visual compositions while delivering impressive realism and quality. However, state-of-the-art methods have been focusing on the narrow domain of natural images, while other distributions remain unexplored. In this paper, we introduce the problem of text-to-figure generation, that is creating scientific figures of papers from text descriptions. We present FigGen, a diffusion-based approach for text-to-figure as well as the main challenges of the proposed task. Code and models are available at https://github.com/joanrod/figure-diffusion