 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarVector: Generating Scalable Vector Graphics Code from Images
Paper and Code



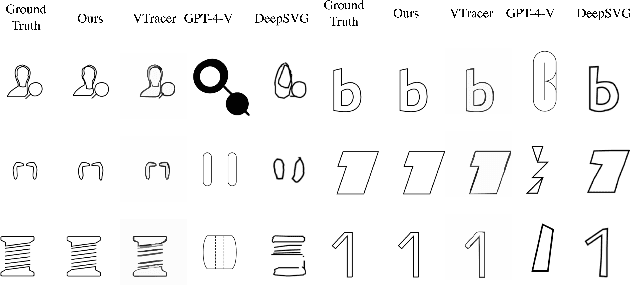
Scalable Vector Graphics (SVGs) have become integral in modern image rendering applications due to their infinite scalability in resolution, versatile usability, and editing capabilities. SVGs are particularly popular in the fields of web development and graphic design. Existing approaches for SVG modeling using deep learning often struggle with generating complex SVGs and are restricted to simpler ones that require extensive processing and simplification. This paper introduces StarVector, a multimodal SVG generation model that effectively integrates Code Generation Large Language Models (CodeLLMs) and vision models. Our approach utilizes a CLIP image encoder to extract visual representations from pixel-based images, which are then transformed into visual tokens via an adapter module. These visual tokens are pre-pended to the SVG token embeddings, and the sequence is modeled by the StarCoder model using next-token prediction, effectively learning to align the visual and code tokens. This enables StarVector to generate unrestricted SVGs that accurately represent pixel images. To evaluate StarVector's performance, we present SVG-Bench, a comprehensive benchmark for evaluating SVG methods across multiple datasets and relevant metrics. Within this benchmark, we introduce novel datasets including SVG-Stack, a large-scale dataset of real-world SVG examples, and use it to pre-train StarVector as a large foundation model for SVGs. Our results demonstrate significant enhancements in visual quality and complexity handling over current methods, marking a notable advancement in SVG generation technology. Code and models: https://github.com/joanrod/star-vector