 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Prototype Alignment and Mixing for Training-Free Few-Shot Classification
Mar 25, 2026Vision-language models (VLMs) like CLIP are trained with the objective of aligning text and image pairs. To improve CLIP-based few-shot image classification, recent works have observed that, along with text embeddings, image embeddings from the training set are an important source of information. In this work we investigate the impact of directly mixing image and text prototypes for few-shot classification and analyze this from a bias-variance perspective. We show that mixing prototypes acts like a shrinkage estimator. Although mixed prototypes improve classification performance, the image prototypes still add some noise in the form of instance-specific background or context information. In order to capture only information from the image space relevant to the given classification task, we propose projecting image prototypes onto the principal directions of the semantic text embedding space to obtain a text-aligned semantic image subspace. These text-aligned image prototypes, when mixed with text embeddings, further improve classification. However, for downstream datasets with poor cross-modal alignment in CLIP, semantic alignment might be suboptimal. We show that the image subspace can still be leveraged by modeling the anisotropy using class covariances. We demonstrate that combining a text-aligned mixed prototype classifier and an image-specific LDA classifier outperforms existing methods across few-shot classification benchmarks.
Modular Memory is the Key to Continual Learning Agents
Mar 02, 2026Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing human performance in several domains, these models remain fundamentally limited in continuous operation, experience accumulation, and personalization, capabilities that are central to adaptive intelligence. While continual learning research has long targeted these goals, its historical focus on in-weight learning (IWL), i.e., updating a single model's parameters to absorb new knowledge, has rendered catastrophic forgetting a persistent challenge. Our position is that combining the strengths of In-Weight Learning (IWL) and the newly emerged capabilities of In-Context Learning (ICL) through the design of modular memory is the missing piece for continual adaptation at scale. We outline a conceptual framework for modular memory-centric architectures that leverage ICL for rapid adaptation and knowledge accumulation, and IWL for stable updates to model capabilities, charting a practical roadmap toward continually learning agents.
Putting a Face to Forgetting: Continual Learning meets Mechanistic Interpretability
Jan 29, 2026Catastrophic forgetting in continual learning is often measured at the performance or last-layer representation level, overlooking the underlying mechanisms. We introduce a mechanistic framework that offers a geometric interpretation of catastrophic forgetting as the result of transformations to the encoding of individual features. These transformations can lead to forgetting by reducing the allocated capacity of features (worse representation) and disrupting their readout by downstream computations. Analysis of a tractable model formalizes this view, allowing us to identify best- and worst-case scenarios. Through experiments on this model, we empirically test our formal analysis and highlight the detrimental effect of depth. Finally, we demonstrate how our framework can be used in the analysis of practical models through the use of Crosscoders. We present a case study of a Vision Transformer trained on sequential CIFAR-10. Our work provides a new, feature-centric vocabulary for continual learning.
On the Computation of the Fisher Information in Continual Learning
Feb 17, 2025One of the most popular methods for continual learning with deep neural networks is Elastic Weight Consolidation (EWC), which involves computing the Fisher Information. The exact way in which the Fisher Information is computed is however rarely described, and multiple different implementations for it can be found online. This blog post discusses and empirically compares several often-used implementations, which highlights that many currently reported results for EWC could likely be improved by changing the way the Fisher Information is computed.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Continual Learning and Catastrophic Forgetting
Mar 08, 2024


This book chapter delves into the dynamics of continual learning, which is the process of incrementally learning from a non-stationary stream of data. Although continual learning is a natural skill for the human brain, it is very challenging for artificial neural networks. An important reason is that, when learning something new, these networks tend to quickly and drastically forget what they had learned before, a phenomenon known as catastrophic forgetting. Especially in the last decade, continual learning has become an extensively studied topic in deep learning. This book chapter reviews the insights that this field has generated.
Disentangled Continual Learning: Separating Memory Edits from Model Updates
Dec 27, 2023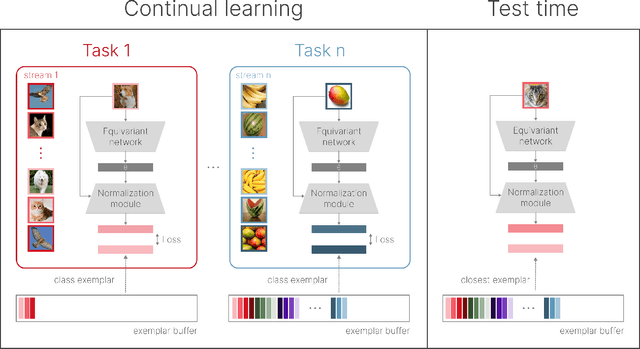
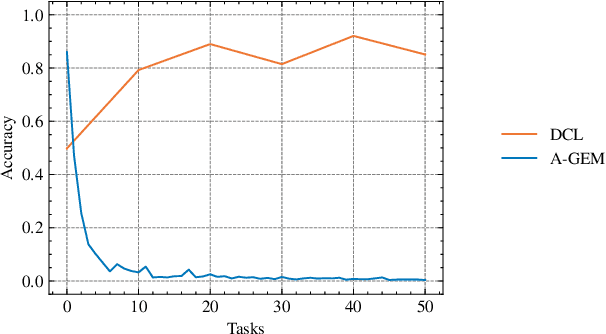

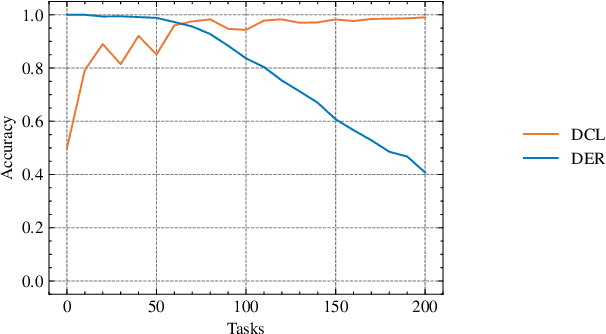
The ability of machine learning systems to learn continually is hindered by catastrophic forgetting, the tendency of neural networks to overwrite existing knowledge when learning a new task. Existing continual learning methods alleviate this problem through regularisation, parameter isolation, or rehearsal, and are typically evaluated on benchmarks consisting of a handful of tasks. We propose a novel conceptual approach to continual classification that aims to disentangle class-specific information that needs to be memorised from the class-agnostic knowledge that encapsulates generalization. We store the former in a buffer that can be easily pruned or updated when new categories arrive, while the latter is represented with a neural network that generalizes across tasks. We show that the class-agnostic network does not suffer from catastrophic forgetting and by leveraging it to perform classification, we improve accuracy on past tasks over time. In addition, our approach supports open-set classification and one-shot generalization. To test our conceptual framework, we introduce Infinite dSprites, a tool for creating continual classification and disentanglement benchmarks of arbitrary length with full control over generative factors. We show that over a sufficiently long time horizon all major types of continual learning methods break down, while our approach enables continual learning over hundreds of tasks with explicit control over memorization and forgetting.
Continual Learning of Diffusion Models with Generative Distillation
Nov 23, 2023Diffusion models are powerful generative models that achieve state-of-the-art performance in tasks such as image synthesis. However, training them demands substantial amounts of data and computational resources. Continual learning would allow for incrementally learning new tasks and accumulating knowledge, thus reusing already trained models would be possible. One potentially suitable approach is generative replay, where a copy of a generative model trained on previous tasks produces synthetic data that are interleaved with data from the current task. However, standard generative replay applied to diffusion models results in a catastrophic loss in denoising capabilities. In this paper, we propose generative distillation, an approach that distils the entire reverse process of a diffusion model. We demonstrate that our approach significantly improves the continual learning performance of generative replay with only a moderate increase in the computational costs.
Continual Learning: Applications and the Road Forward
Nov 21, 2023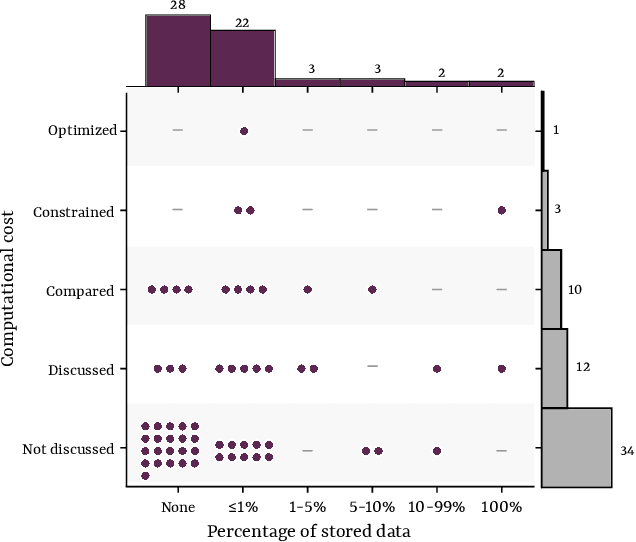
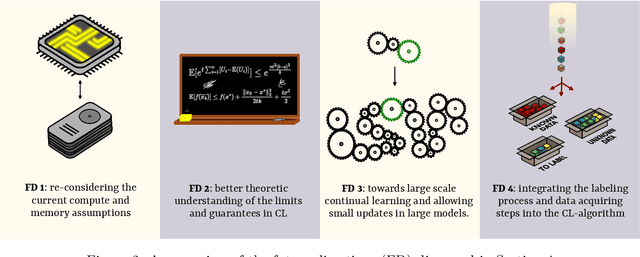
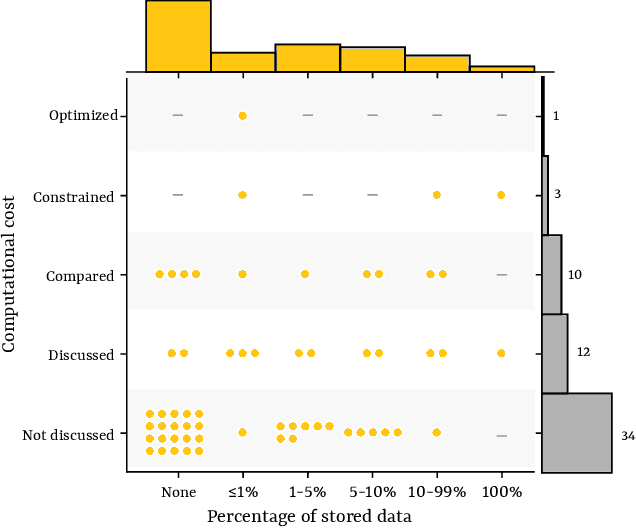
Continual learning is a sub-field of machine learning, which aims to allow machine learning models to continuously learn on new data, by accumulating knowledge without forgetting what was learned in the past. In this work, we take a step back, and ask: "Why should one care about continual learning in the first place?". We set the stage by surveying recent continual learning papers published at three major machine learning conferences, and show that memory-constrained settings dominate the field. Then, we discuss five open problems in machine learning, and even though they seem unrelated to continual learning at first sight, we show that continual learning will inevitably be part of their solution. These problems are model-editing, personalization, on-device learning, faster (re-)training and reinforcement learning. Finally, by comparing the desiderata from these unsolved problems and the current assumptions in continual learning, we highlight and discuss four future directions for continual learning research. We hope that this work offers an interesting perspective on the future of continual learning, while displaying its potential value and the paths we have to pursue in order to make it successful. This work is the result of the many discussions the authors had at the Dagstuhl seminar on Deep Continual Learning, in March 2023.
Two Complementary Perspectives to Continual Learning: Ask Not Only What to Optimize, But Also How
Nov 08, 2023Recent years have seen considerable progress in the continual training of deep neural networks, predominantly thanks to approaches that add replay or regularization terms to the loss function to approximate the joint loss over all tasks so far. However, we show that even with a perfect approximation to the joint loss, these approaches still suffer from temporary but substantial forgetting when starting to train on a new task. Motivated by this 'stability gap', we propose that continual learning strategies should focus not only on the optimization objective, but also on the way this objective is optimized. While there is some continual learning work that alters the optimization trajectory (e.g., using gradient projection techniques), this line of research is positioned as alternative to improving the optimization objective, while we argue it should be complementary. To evaluate the merits of our proposition, we plan to combine replay-approximated joint objectives with gradient projection-based optimization routines to test whether the addition of the latter provides benefits in terms of (1) alleviating the stability gap, (2) increasing the learning efficiency and (3) improving the final learning outcome.