 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Accumulation in Continually Learned Representations and the Issue of Feature Forgetting
Paper and Code
Apr 03, 2023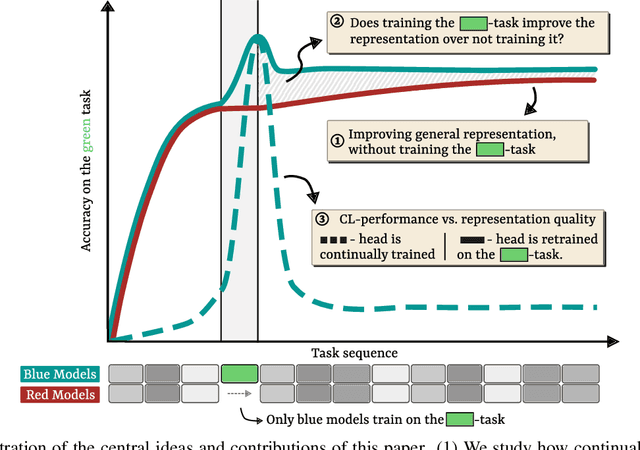

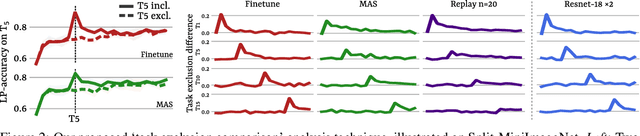
By default, neural networks learn on all training data at once. When such a model is trained on sequential chunks of new data, it tends to catastrophically forget how to handle old data. In this work we investigate how continual learners learn and forget representations. We observe two phenomena: knowledge accumulation, i.e. the improvement of a representation over time, and feature forgetting, i.e. the loss of task-specific representations. To better understand both phenomena, we introduce a new analysis technique called task exclusion comparison. If a model has seen a task and it has not forgotten all the task-specific features, then its representation for that task should be better than that of a model that was trained on similar tasks, but not that exact one. Our image classification experiments show that most task-specific features are quickly forgotten, in contrast to what has been suggested in the past. Further, we demonstrate how some continual learning methods, like replay, and ideas from representation learning affect a continually learned representation. We conclude by observing that representation quality is tightly correlated with continual learning performance.