 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Memory is the Key to Continual Learning Agents
Mar 02, 2026Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing human performance in several domains, these models remain fundamentally limited in continuous operation, experience accumulation, and personalization, capabilities that are central to adaptive intelligence. While continual learning research has long targeted these goals, its historical focus on in-weight learning (IWL), i.e., updating a single model's parameters to absorb new knowledge, has rendered catastrophic forgetting a persistent challenge. Our position is that combining the strengths of In-Weight Learning (IWL) and the newly emerged capabilities of In-Context Learning (ICL) through the design of modular memory is the missing piece for continual adaptation at scale. We outline a conceptual framework for modular memory-centric architectures that leverage ICL for rapid adaptation and knowledge accumulation, and IWL for stable updates to model capabilities, charting a practical roadmap toward continually learning agents.
Two Complementary Perspectives to Continual Learning: Ask Not Only What to Optimize, But Also How
Nov 08, 2023Recent years have seen considerable progress in the continual training of deep neural networks, predominantly thanks to approaches that add replay or regularization terms to the loss function to approximate the joint loss over all tasks so far. However, we show that even with a perfect approximation to the joint loss, these approaches still suffer from temporary but substantial forgetting when starting to train on a new task. Motivated by this 'stability gap', we propose that continual learning strategies should focus not only on the optimization objective, but also on the way this objective is optimized. While there is some continual learning work that alters the optimization trajectory (e.g., using gradient projection techniques), this line of research is positioned as alternative to improving the optimization objective, while we argue it should be complementary. To evaluate the merits of our proposition, we plan to combine replay-approximated joint objectives with gradient projection-based optimization routines to test whether the addition of the latter provides benefits in terms of (1) alleviating the stability gap, (2) increasing the learning efficiency and (3) improving the final learning outcome.
Knowledge Accumulation in Continually Learned Representations and the Issue of Feature Forgetting
Apr 03, 2023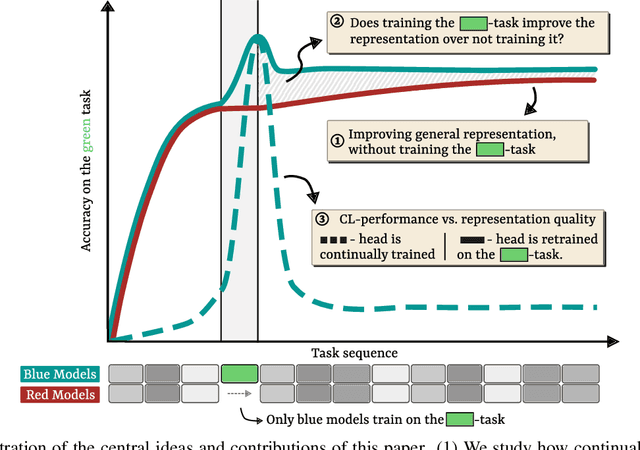

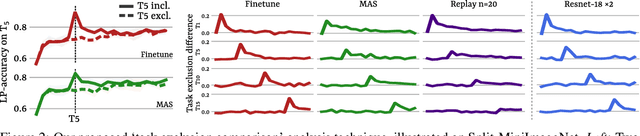
By default, neural networks learn on all training data at once. When such a model is trained on sequential chunks of new data, it tends to catastrophically forget how to handle old data. In this work we investigate how continual learners learn and forget representations. We observe two phenomena: knowledge accumulation, i.e. the improvement of a representation over time, and feature forgetting, i.e. the loss of task-specific representations. To better understand both phenomena, we introduce a new analysis technique called task exclusion comparison. If a model has seen a task and it has not forgotten all the task-specific features, then its representation for that task should be better than that of a model that was trained on similar tasks, but not that exact one. Our image classification experiments show that most task-specific features are quickly forgotten, in contrast to what has been suggested in the past. Further, we demonstrate how some continual learning methods, like replay, and ideas from representation learning affect a continually learned representation. We conclude by observing that representation quality is tightly correlated with continual learning performance.
A Procedural World Generation Framework for Systematic Evaluation of Continual Learning
Jun 04, 2021


Several families of continual learning techniques have been proposed to alleviate catastrophic interference in deep neural network training on non-stationary data. However, a comprehensive comparison and analysis of limitations remains largely open due to the inaccessibility to suitable datasets. Empirical examination not only varies immensely between individual works, it further currently relies on contrived composition of benchmarks through subdivision and concatenation of various prevalent static vision datasets. In this work, our goal is to bridge this gap by introducing a computer graphics simulation framework that repeatedly renders only upcoming urban scene fragments in an endless real-time procedural world generation process. At its core lies a modular parametric generative model with adaptable generative factors. The latter can be used to flexibly compose data streams, which significantly facilitates a detailed analysis and allows for effortless investigation of various continual learning schemes.