 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Decomposed Hybrid Networks
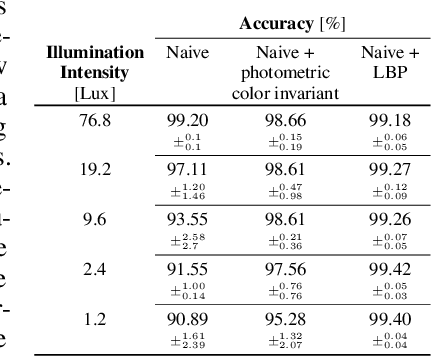
Mar 24, 2025The robustness of image recognition algorithms remains a critical challenge, as current models often depend on large quantities of labeled data. In this paper, we propose a hybrid approach that combines the adaptability of neural networks with the interpretability, transparency, and robustness of domain-specific quasi-invariant operators. Our method decomposes the recognition into multiple task-specific operators that focus on different characteristics, supported by a novel confidence measurement tailored to these operators. This measurement enables the network to prioritize reliable features and accounts for noise. We argue that our design enhances transparency and robustness, leading to improved performance, particularly in low-data regimes. Experimental results in traffic sign detection highlight the effectiveness of the proposed method, especially in semi-supervised and unsupervised scenarios, underscoring its potential for data-constrained applications.
A Procedural World Generation Framework for Systematic Evaluation of Continual Learning
Jun 04, 2021


Several families of continual learning techniques have been proposed to alleviate catastrophic interference in deep neural network training on non-stationary data. However, a comprehensive comparison and analysis of limitations remains largely open due to the inaccessibility to suitable datasets. Empirical examination not only varies immensely between individual works, it further currently relies on contrived composition of benchmarks through subdivision and concatenation of various prevalent static vision datasets. In this work, our goal is to bridge this gap by introducing a computer graphics simulation framework that repeatedly renders only upcoming urban scene fragments in an endless real-time procedural world generation process. At its core lies a modular parametric generative model with adaptable generative factors. The latter can be used to flexibly compose data streams, which significantly facilitates a detailed analysis and allows for effortless investigation of various continual learning schemes.
When Deep Classifiers Agree: Analyzing Correlations between Learning Order and Image Statistics
May 19, 2021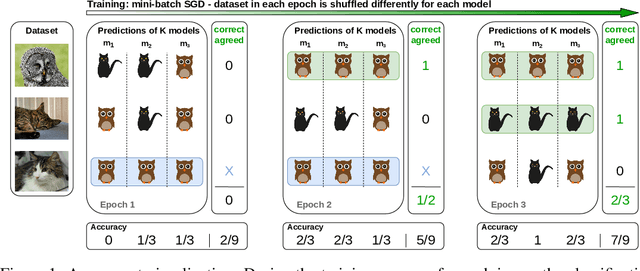
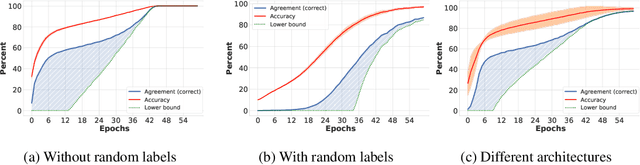

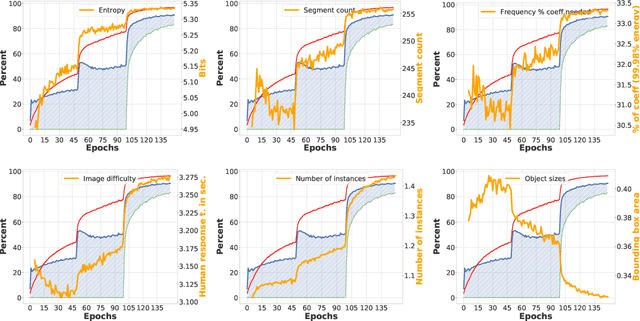
Although a plethora of architectural variants for deep classification has been introduced over time, recent works have found empirical evidence towards similarities in their training process. It has been hypothesized that neural networks converge not only to similar representations, but also exhibit a notion of empirical agreement on which data instances are learned first. Following in the latter works$'$ footsteps, we define a metric to quantify the relationship between such classification agreement over time, and posit that the agreement phenomenon can be mapped to core statistics of the investigated dataset. We empirically corroborate this hypothesis across the CIFAR10, Pascal, ImageNet and KTH-TIPS2 datasets. Our findings indicate that agreement seems to be independent of specific architectures, training hyper-parameters or labels, albeit follows an ordering according to image statistics.
Neural Architecture Search of Deep Priors: Towards Continual Learning without Catastrophic Interference
Apr 14, 2021
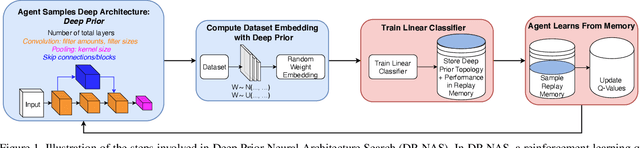


In this paper we analyze the classification performance of neural network structures without parametric inference. Making use of neural architecture search, we empirically demonstrate that it is possible to find random weight architectures, a deep prior, that enables a linear classification to perform on par with fully trained deep counterparts. Through ablation experiments, we exclude the possibility of winning a weight initialization lottery and confirm that suitable deep priors do not require additional inference. In an extension to continual learning, we investigate the possibility of catastrophic interference free incremental learning. Under the assumption of classes originating from the same data distribution, a deep prior found on only a subset of classes is shown to allow discrimination of further classes through training of a simple linear classifier.
A Wholistic View of Continual Learning with Deep Neural Networks: Forgotten Lessons and the Bridge to Active and Open World Learning
Sep 11, 2020
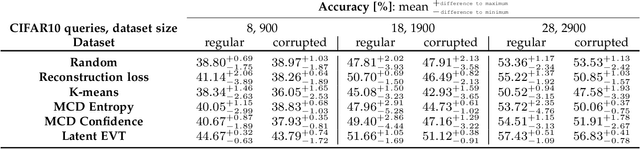
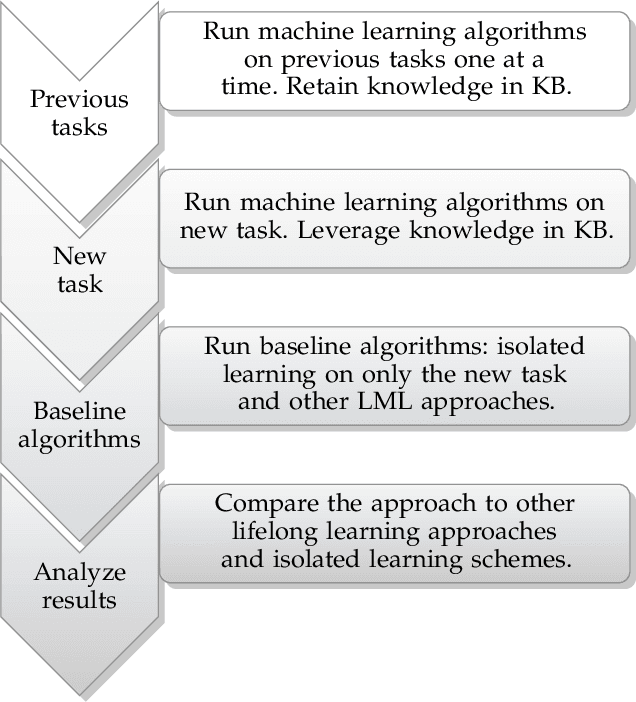

Current deep learning research is dominated by benchmark evaluation. A method is regarded as favorable if it empirically performs well on the dedicated test set. This mentality is seamlessly reflected in the resurfacing area of continual learning, where consecutively arriving sets of benchmark data are investigated. The core challenge is framed as protecting previously acquired representations from being catastrophically forgotten due to the iterative parameter updates. However, comparison of individual methods is nevertheless treated in isolation from real world application and typically judged by monitoring accumulated test set performance. The closed world assumption remains predominant. It is assumed that during deployment a model is guaranteed to encounter data that stems from the same distribution as used for training. This poses a massive challenge as neural networks are well known to provide overconfident false predictions on unknown instances and break down in the face of corrupted data. In this work we argue that notable lessons from open set recognition, the identification of statistically deviating data outside of the observed dataset, and the adjacent field of active learning, where data is incrementally queried such that the expected performance gain is maximized, are frequently overlooked in the deep learning era. Based on these forgotten lessons, we propose a consolidated view to bridge continual learning, active learning and open set recognition in deep neural networks. Our results show that this not only benefits each individual paradigm, but highlights the natural synergies in a common framework. We empirically demonstrate improvements when alleviating catastrophic forgetting, querying data in active learning, selecting task orders, while exhibiting robust open world application where previously proposed methods fail.
Open Set Recognition Through Deep Neural Network Uncertainty: Does Out-of-Distribution Detection Require Generative Classifiers?
Aug 26, 2019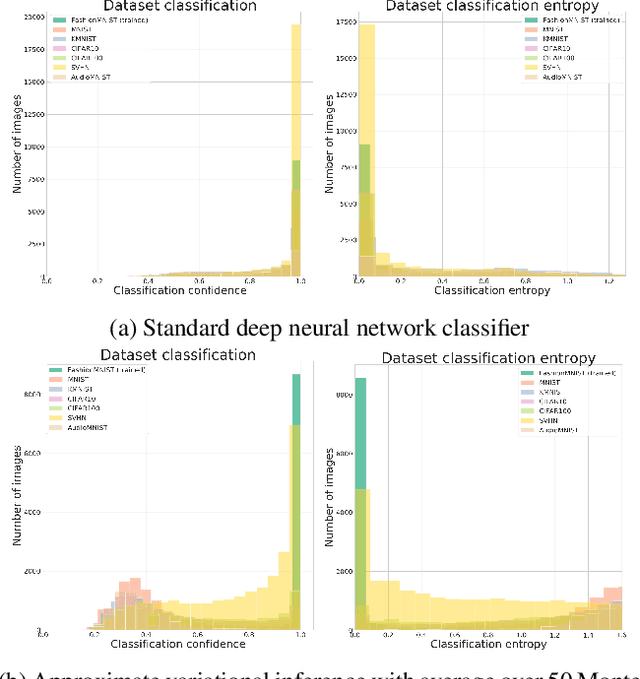
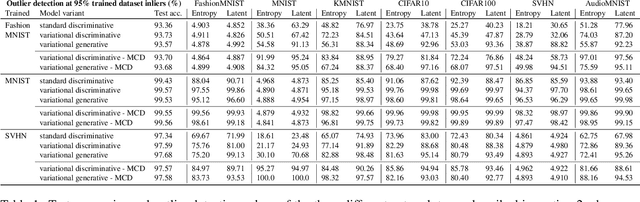
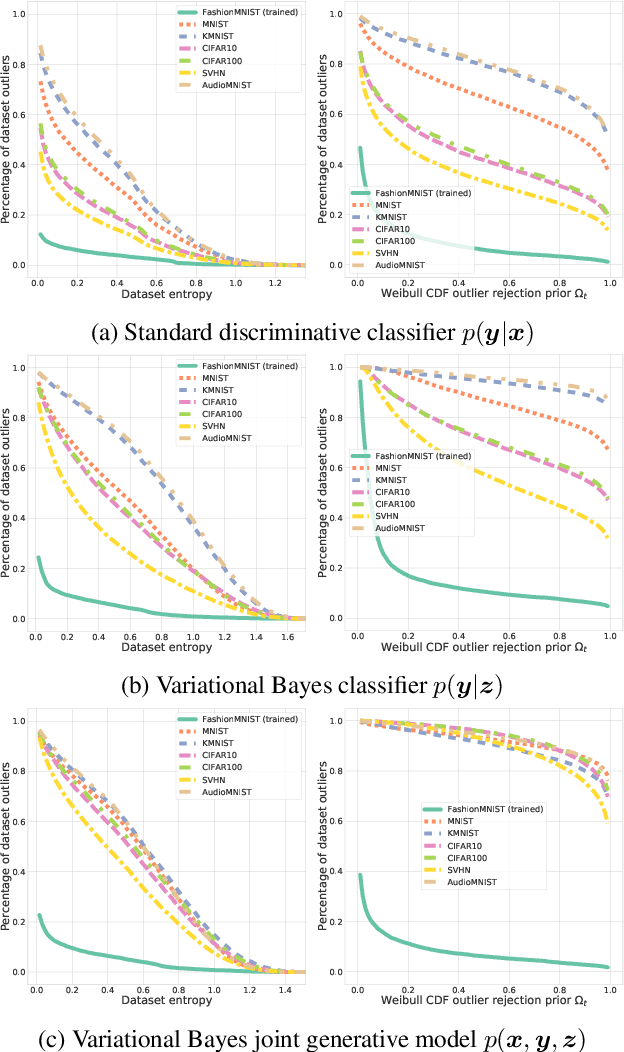
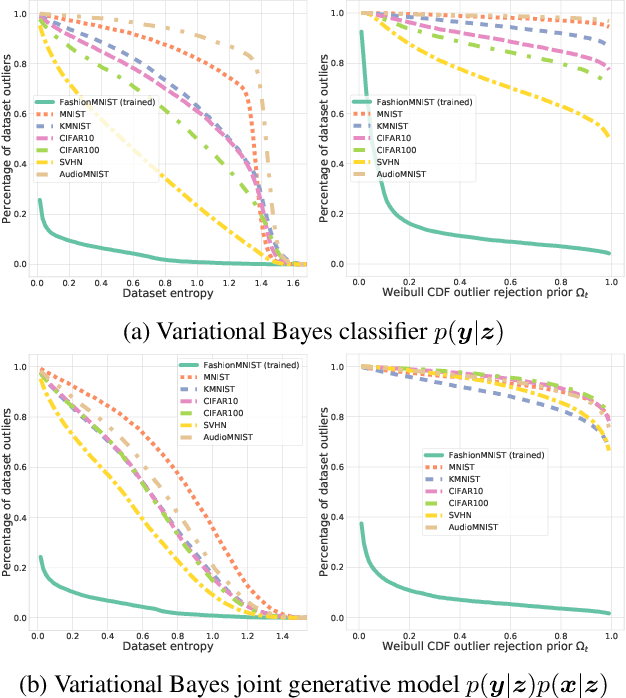
We present an analysis of predictive uncertainty based out-of-distribution detection for different approaches to estimate various models' epistemic uncertainty and contrast it with extreme value theory based open set recognition. While the former alone does not seem to be enough to overcome this challenge, we demonstrate that uncertainty goes hand in hand with the latter method. This seems to be particularly reflected in a generative model approach, where we show that posterior based open set recognition outperforms discriminative models and predictive uncertainty based outlier rejection, raising the question of whether classifiers need to be generative in order to know what they have not seen.
Unified Probabilistic Deep Continual Learning through Generative Replay and Open Set Recognition
May 28, 2019


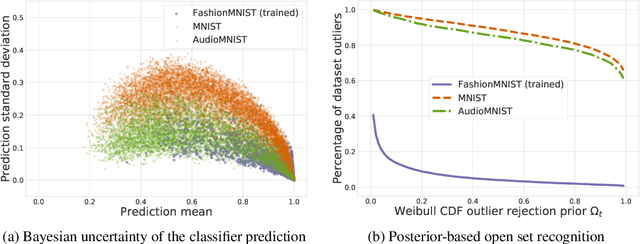
We introduce a unified probabilistic approach for deep continual learning based on variational Bayesian inference with open set recognition. Our model combines a probabilistic encoder with a generative model and a generative linear classifier that get shared across tasks. The open set recognition bounds the approximate posterior by fitting regions of high density on the basis of correctly classified data points and balances open-space risk with recognition errors. Catastrophic inference for both generative models is significantly alleviated through generative replay, where the open set recognition is used to sample from high density areas of the class specific posterior and reject statistical outliers. Our approach naturally allows for forward and backward transfer while maintaining past knowledge without the necessity of storing old data, regularization or inferring task labels. We demonstrate compelling results in the challenging scenario of incrementally expanding the single-head classifier for both class incremental visual and audio classification tasks, as well as incremental learning of datasets across modalities.