 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem
Feb 05, 2024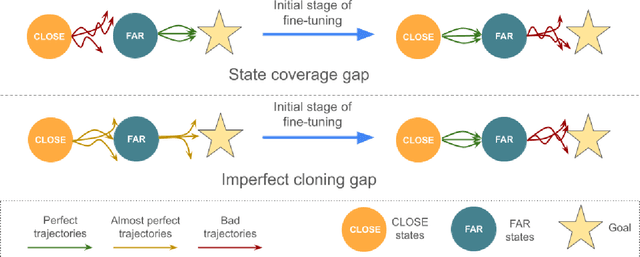
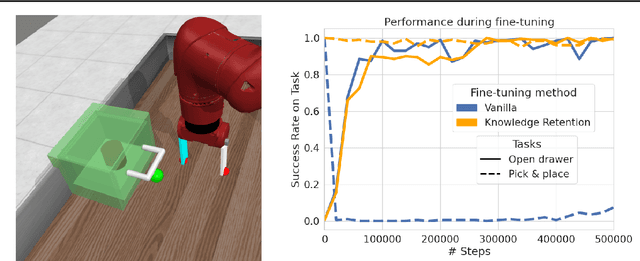
Fine-tuning is a widespread technique that allows practitioners to transfer pre-trained capabilities, as recently showcased by the successful applications of foundation models. However, fine-tuning reinforcement learning (RL) models remains a challenge. This work conceptualizes one specific cause of poor transfer, accentuated in the RL setting by the interplay between actions and observations: forgetting of pre-trained capabilities. Namely, a model deteriorates on the state subspace of the downstream task not visited in the initial phase of fine-tuning, on which the model behaved well due to pre-training. This way, we lose the anticipated transfer benefits. We identify conditions when this problem occurs, showing that it is common and, in many cases, catastrophic. Through a detailed empirical analysis of the challenging NetHack and Montezuma's Revenge environments, we show that standard knowledge retention techniques mitigate the problem and thus allow us to take full advantage of the pre-trained capabilities. In particular, in NetHack, we achieve a new state-of-the-art for neural models, improving the previous best score from $5$K to over $10$K points in the Human Monk scenario.
Exploiting Novel GPT-4 APIs
Dec 21, 2023Language model attacks typically assume one of two extreme threat models: full white-box access to model weights, or black-box access limited to a text generation API. However, real-world APIs are often more flexible than just text generation: these APIs expose ``gray-box'' access leading to new threat vectors. To explore this, we red-team three new functionalities exposed in the GPT-4 APIs: fine-tuning, function calling and knowledge retrieval. We find that fine-tuning a model on as few as 15 harmful examples or 100 benign examples can remove core safeguards from GPT-4, enabling a range of harmful outputs. Furthermore, we find that GPT-4 Assistants readily divulge the function call schema and can be made to execute arbitrary function calls. Finally, we find that knowledge retrieval can be hijacked by injecting instructions into retrieval documents. These vulnerabilities highlight that any additions to the functionality exposed by an API can create new vulnerabilities.
Prediction Error-based Classification for Class-Incremental Learning
May 30, 2023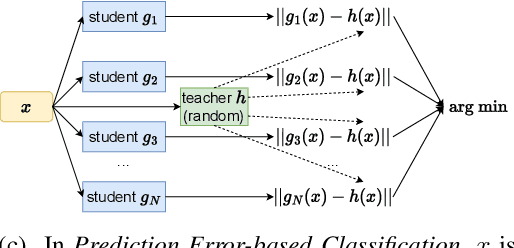
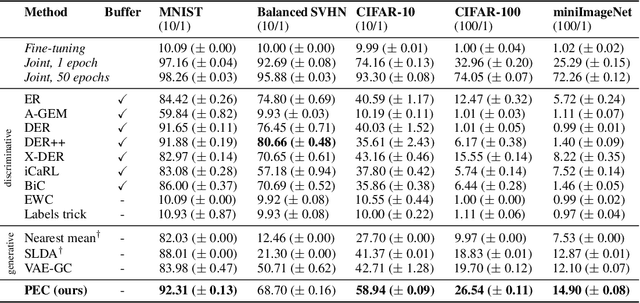
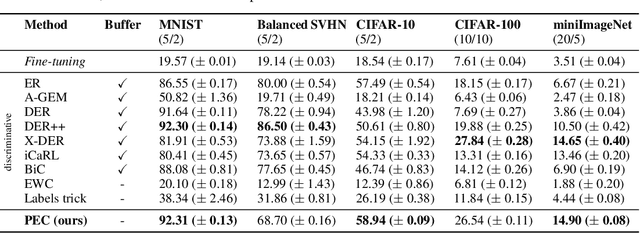
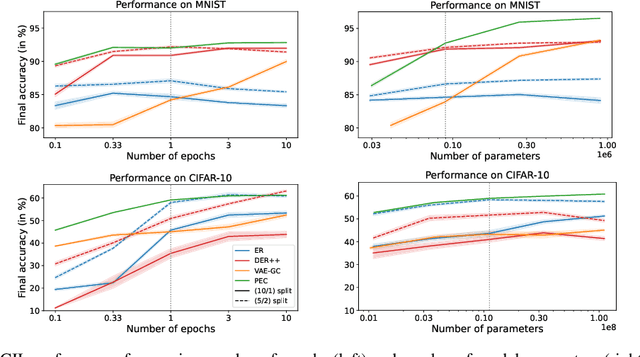
Class-incremental learning (CIL) is a particularly challenging variant of continual learning, where the goal is to learn to discriminate between all classes presented in an incremental fashion. Existing approaches often suffer from excessive forgetting and imbalance of the scores assigned to classes that have not been seen together during training. In this study, we introduce a novel approach, Prediction Error-based Classification (PEC), which differs from traditional discriminative and generative classification paradigms. PEC computes a class score by measuring the prediction error of a model trained to replicate the outputs of a frozen random neural network on data from that class. The method can be interpreted as approximating a classification rule based on Gaussian Process posterior variance. PEC offers several practical advantages, including sample efficiency, ease of tuning, and effectiveness even when data are presented one class at a time. Our empirical results show that PEC performs strongly in single-pass-through-data CIL, outperforming other rehearsal-free baselines in all cases and rehearsal-based methods with moderate replay buffer size in most cases across multiple benchmarks.
Exploring Continual Learning of Diffusion Models
Mar 27, 2023



Diffusion models have achieved remarkable success in generating high-quality images thanks to their novel training procedures applied to unprecedented amounts of data. However, training a diffusion model from scratch is computationally expensive. This highlights the need to investigate the possibility of training these models iteratively, reusing computation while the data distribution changes. In this study, we take the first step in this direction and evaluate the continual learning (CL) properties of diffusion models. We begin by benchmarking the most common CL methods applied to Denoising Diffusion Probabilistic Models (DDPMs), where we note the strong performance of the experience replay with the reduced rehearsal coefficient. Furthermore, we provide insights into the dynamics of forgetting, which exhibit diverse behavior across diffusion timesteps. We also uncover certain pitfalls of using the bits-per-dimension metric for evaluating CL.
Trust Your $ abla$: Gradient-based Intervention Targeting for Causal Discovery
Nov 24, 2022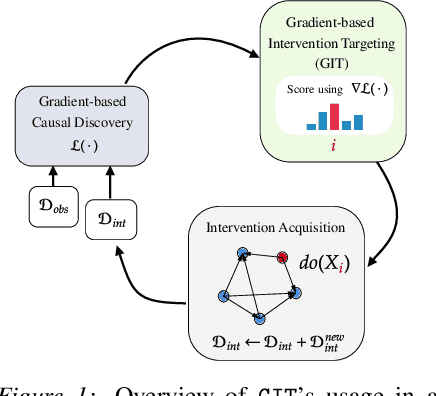

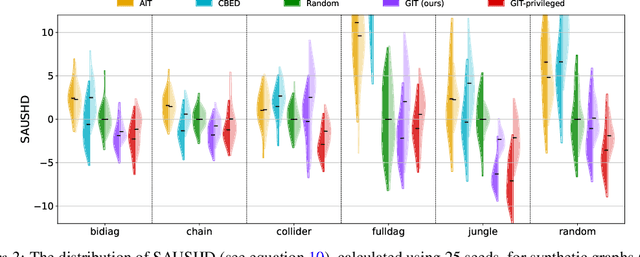

Inferring causal structure from data is a challenging task of fundamental importance in science. Observational data are often insufficient to identify a system's causal structure uniquely. While conducting interventions (i.e., experiments) can improve the identifiability, such samples are usually challenging and expensive to obtain. Hence, experimental design approaches for causal discovery aim to minimize the number of interventions by estimating the most informative intervention target. In this work, we propose a novel Gradient-based Intervention Targeting method, abbreviated GIT, that 'trusts' the gradient estimator of a gradient-based causal discovery framework to provide signals for the intervention acquisition function. We provide extensive experiments in simulated and real-world datasets and demonstrate that GIT performs on par with competitive baselines, surpassing them in the low-data regime.
Disentangling Transfer in Continual Reinforcement Learning
Sep 28, 2022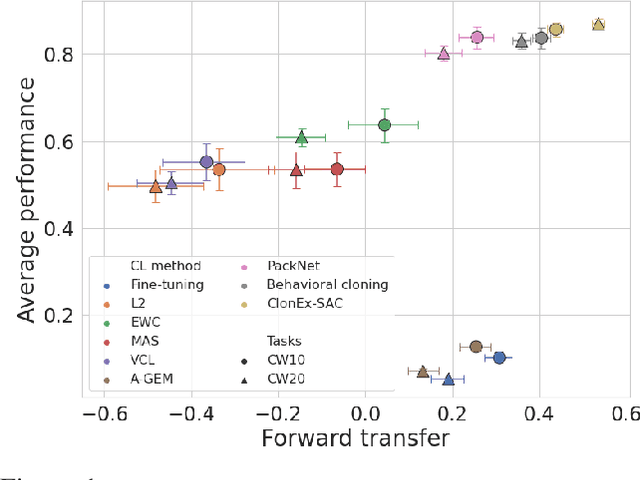
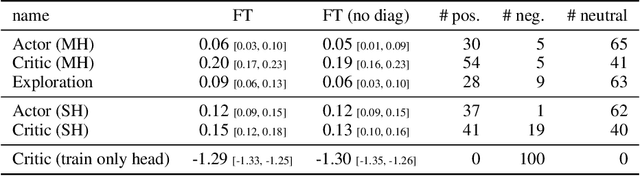
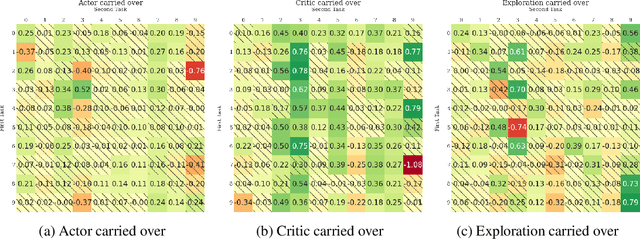
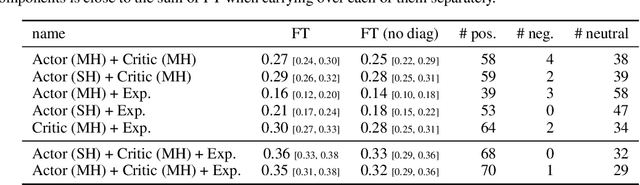
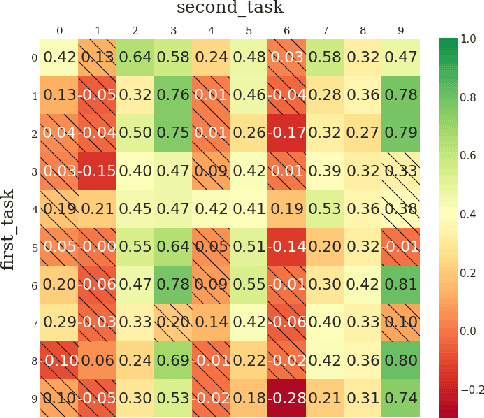
The ability of continual learning systems to transfer knowledge from previously seen tasks in order to maximize performance on new tasks is a significant challenge for the field, limiting the applicability of continual learning solutions to realistic scenarios. Consequently, this study aims to broaden our understanding of transfer and its driving forces in the specific case of continual reinforcement learning. We adopt SAC as the underlying RL algorithm and Continual World as a suite of continuous control tasks. We systematically study how different components of SAC (the actor and the critic, exploration, and data) affect transfer efficacy, and we provide recommendations regarding various modeling options. The best set of choices, dubbed ClonEx-SAC, is evaluated on the recent Continual World benchmark. ClonEx-SAC achieves 87% final success rate compared to 80% of PackNet, the best method in the benchmark. Moreover, the transfer grows from 0.18 to 0.54 according to the metric provided by Continual World.
Continual World: A Robotic Benchmark For Continual Reinforcement Learning
May 23, 2021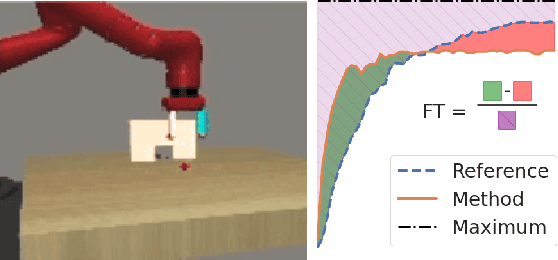
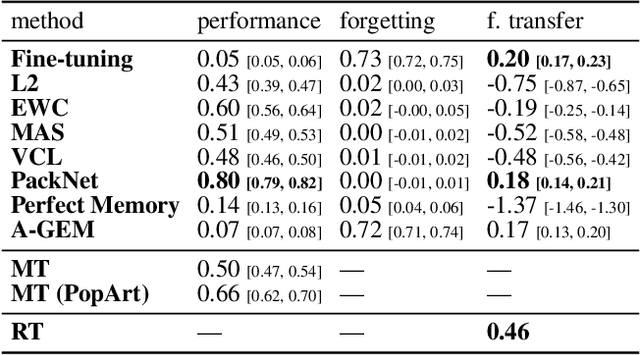

Continual learning (CL) -- the ability to continuously learn, building on previously acquired knowledge -- is a natural requirement for long-lived autonomous reinforcement learning (RL) agents. While building such agents, one needs to balance opposing desiderata, such as constraints on capacity and compute, the ability to not catastrophically forget, and to exhibit positive transfer on new tasks. Understanding the right trade-off is conceptually and computationally challenging, which we argue has led the community to overly focus on catastrophic forgetting. In response to these issues, we advocate for the need to prioritize forward transfer and propose Continual World, a benchmark consisting of realistic and meaningfully diverse robotic tasks built on top of Meta-World as a testbed. Following an in-depth empirical evaluation of existing CL methods, we pinpoint their limitations and highlight unique algorithmic challenges in the RL setting. Our benchmark aims to provide a meaningful and computationally inexpensive challenge for the community and thus help better understand the performance of existing and future solutions.
Google Research Football: A Novel Reinforcement Learning Environment
Jul 25, 2019


Recent progress in the field of reinforcement learning has been accelerated by virtual learning environments such as video games, where novel algorithms and ideas can be quickly tested in a safe and reproducible manner. We introduce the Google Research Football Environment, a new reinforcement learning environment where agents are trained to play football in an advanced, physics-based 3D simulator. The resulting environment is challenging, easy to use and customize, and it is available under a permissive open-source license. In addition, it provides support for multiplayer and multi-agent experiments. We propose three full-game scenarios of varying difficulty with the Football Benchmarks and report baseline results for three commonly used reinforcement algorithms (IMPALA, PPO, and Ape-X DQN). We also provide a diverse set of simpler scenarios with the Football Academy and showcase several promising research directions.
Split Batch Normalization: Improving Semi-Supervised Learning under Domain Shift
Apr 06, 2019
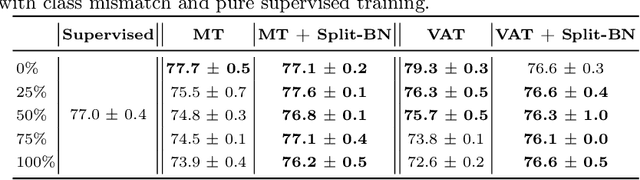
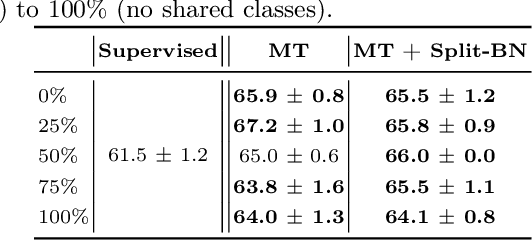
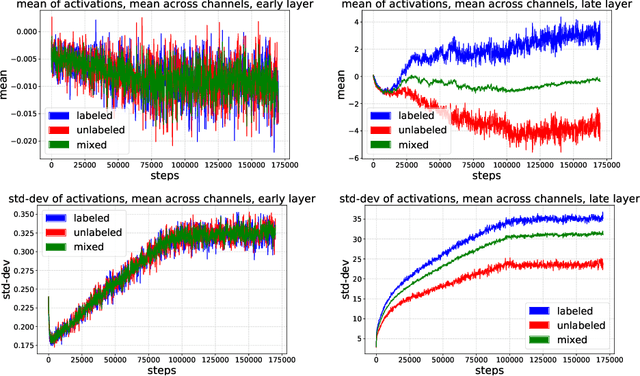
Recent work has shown that using unlabeled data in semi-supervised learning is not always beneficial and can even hurt generalization, especially when there is a class mismatch between the unlabeled and labeled examples. We investigate this phenomenon for image classification on the CIFAR-10 and the ImageNet datasets, and with many other forms of domain shifts applied (e.g. salt-and-pepper noise). Our main contribution is Split Batch Normalization (Split-BN), a technique to improve SSL when the additional unlabeled data comes from a shifted distribution. We achieve it by using separate batch normalization statistics for unlabeled examples. Due to its simplicity, we recommend it as a standard practice. Finally, we analyse how domain shift affects the SSL training process. In particular, we find that during training the statistics of hidden activations in late layers become markedly different between the unlabeled and the labeled examples.
Adversarial Framing for Image and Video Classification
Dec 11, 2018



Neural networks are prone to adversarial attacks. In general, such attacks deteriorate the quality of the input by either slightly modifying most of its pixels, or by occluding it with a patch. In this paper, we propose a method that keeps the image unchanged and only adds an adversarial framing on the border of the image. We show empirically that our method is able to successfully attack state-of-the-art methods on both image and video classification problems. Notably, the proposed method results in a universal attack which is very fast at test time. Source code can be found at https://github.com/zajaczajac/adv_framing .