 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaunchpad: A Programming Model for Distributed Machine Learning Research
Jun 07, 2021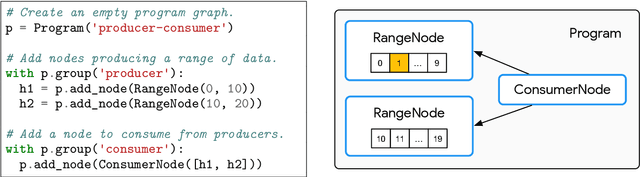
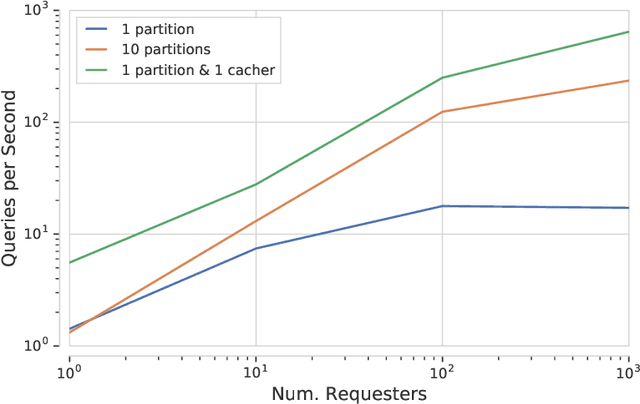
A major driver behind the success of modern machine learning algorithms has been their ability to process ever-larger amounts of data. As a result, the use of distributed systems in both research and production has become increasingly prevalent as a means to scale to this growing data. At the same time, however, distributing the learning process can drastically complicate the implementation of even simple algorithms. This is especially problematic as many machine learning practitioners are not well-versed in the design of distributed systems, let alone those that have complicated communication topologies. In this work we introduce Launchpad, a programming model that simplifies the process of defining and launching distributed systems that is specifically tailored towards a machine learning audience. We describe our framework, its design philosophy and implementation, and give a number of examples of common learning algorithms whose designs are greatly simplified by this approach.
What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
Jun 10, 2020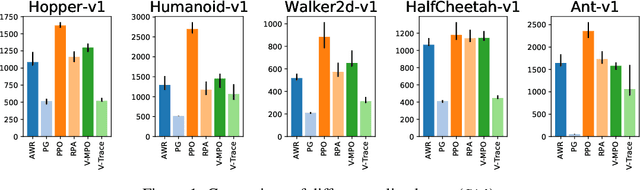

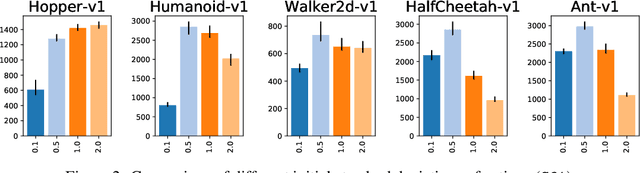

In recent years, on-policy reinforcement learning (RL) has been successfully applied to many different continuous control tasks. While RL algorithms are often conceptually simple, their state-of-the-art implementations take numerous low- and high-level design decisions that strongly affect the performance of the resulting agents. Those choices are usually not extensively discussed in the literature, leading to discrepancy between published descriptions of algorithms and their implementations. This makes it hard to attribute progress in RL and slows down overall progress [Engstrom'20]. As a step towards filling that gap, we implement >50 such ``choices'' in a unified on-policy RL framework, allowing us to investigate their impact in a large-scale empirical study. We train over 250'000 agents in five continuous control environments of different complexity and provide insights and practical recommendations for on-policy training of RL agents.
Google Research Football: A Novel Reinforcement Learning Environment
Jul 25, 2019


Recent progress in the field of reinforcement learning has been accelerated by virtual learning environments such as video games, where novel algorithms and ideas can be quickly tested in a safe and reproducible manner. We introduce the Google Research Football Environment, a new reinforcement learning environment where agents are trained to play football in an advanced, physics-based 3D simulator. The resulting environment is challenging, easy to use and customize, and it is available under a permissive open-source license. In addition, it provides support for multiplayer and multi-agent experiments. We propose three full-game scenarios of varying difficulty with the Football Benchmarks and report baseline results for three commonly used reinforcement algorithms (IMPALA, PPO, and Ape-X DQN). We also provide a diverse set of simpler scenarios with the Football Academy and showcase several promising research directions.