 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLDS: an Ecosystem to Generate, Share and Use Datasets in Reinforcement Learning
Nov 04, 2021



We introduce RLDS (Reinforcement Learning Datasets), an ecosystem for recording, replaying, manipulating, annotating and sharing data in the context of Sequential Decision Making (SDM) including Reinforcement Learning (RL), Learning from Demonstrations, Offline RL or Imitation Learning. RLDS enables not only reproducibility of existing research and easy generation of new datasets, but also accelerates novel research. By providing a standard and lossless format of datasets it enables to quickly test new algorithms on a wider range of tasks. The RLDS ecosystem makes it easy to share datasets without any loss of information and to be agnostic to the underlying original format when applying various data processing pipelines to large collections of datasets. Besides, RLDS provides tools for collecting data generated by either synthetic agents or humans, as well as for inspecting and manipulating the collected data. Ultimately, integration with TFDS facilitates the sharing of RL datasets with the research community.
Hyperparameter Selection for Imitation Learning
May 25, 2021
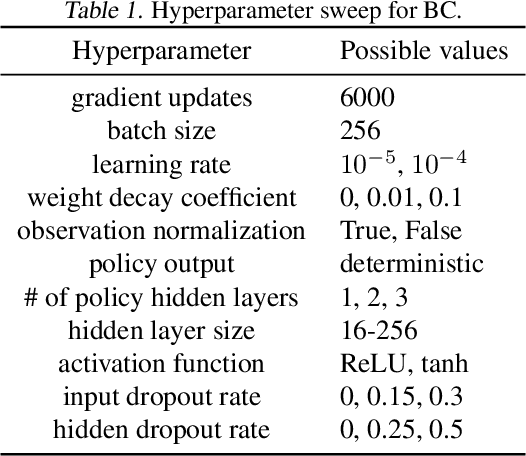
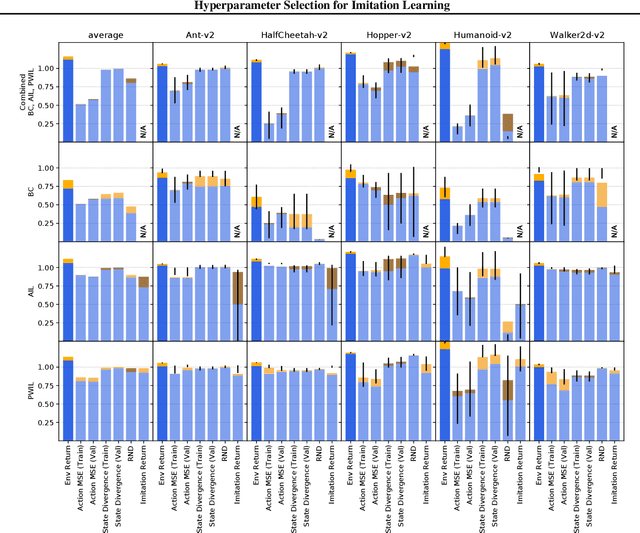
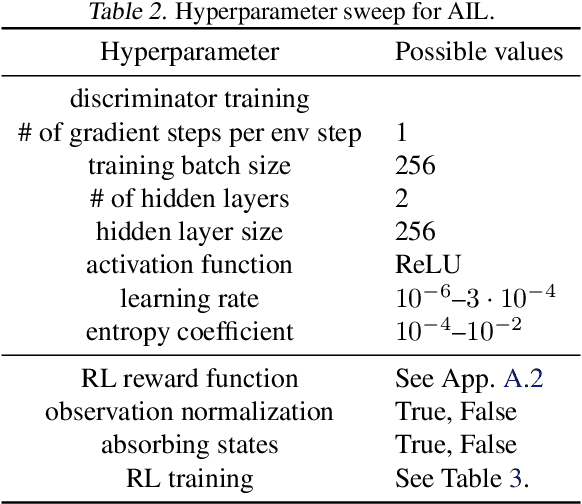
We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.
What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
Jun 10, 2020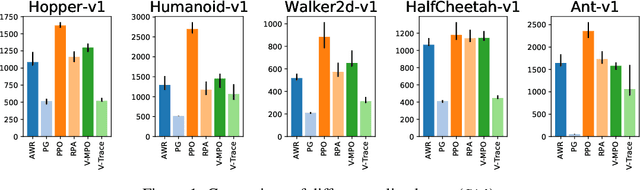

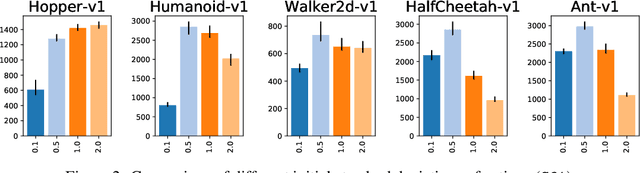

In recent years, on-policy reinforcement learning (RL) has been successfully applied to many different continuous control tasks. While RL algorithms are often conceptually simple, their state-of-the-art implementations take numerous low- and high-level design decisions that strongly affect the performance of the resulting agents. Those choices are usually not extensively discussed in the literature, leading to discrepancy between published descriptions of algorithms and their implementations. This makes it hard to attribute progress in RL and slows down overall progress [Engstrom'20]. As a step towards filling that gap, we implement >50 such ``choices'' in a unified on-policy RL framework, allowing us to investigate their impact in a large-scale empirical study. We train over 250'000 agents in five continuous control environments of different complexity and provide insights and practical recommendations for on-policy training of RL agents.
Towards Accurate Generative Models of Video: A New Metric & Challenges
Dec 03, 2018



Recent advances in deep generative models have lead to remarkable progress in synthesizing high quality images. Following their successful application in image processing and representation learning, an important next step is to consider videos. Learning generative models of video is a much harder task, requiring a model to capture the temporal dynamics of a scene, in addition to the visual presentation of objects. Although recent attempts at formulating generative models of video have had some success, current progress is hampered by (1) the lack of qualitative metrics that consider visual quality, temporal coherence, and diversity of samples, and (2) the wide gap between purely synthetic video datasets and challenging real-world datasets in terms of complexity. To this extent we propose Fr\'echet Video Distance (FVD), a new metric for generative models of video based on FID, and StarCraft 2 Videos (SCV), a collection of progressively harder datasets that challenge the capabilities of the current iteration of generative models for video. We conduct a large-scale human study, which confirms that FVD correlates well with qualitative human judgment of generated videos, and provide initial benchmark results on SCV.