 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet Back Here: Robust Imitation by Return-to-Distribution Planning
May 02, 2023We consider the Imitation Learning (IL) setup where expert data are not collected on the actual deployment environment but on a different version. To address the resulting distribution shift, we combine behavior cloning (BC) with a planner that is tasked to bring the agent back to states visited by the expert whenever the agent deviates from the demonstration distribution. The resulting algorithm, POIR, can be trained offline, and leverages online interactions to efficiently fine-tune its planner to improve performance over time. We test POIR on a variety of human-generated manipulation demonstrations in a realistic robotic manipulation simulator and show robustness of the learned policy to different initial state distributions and noisy dynamics.
Hyperparameter Selection for Imitation Learning
May 25, 2021
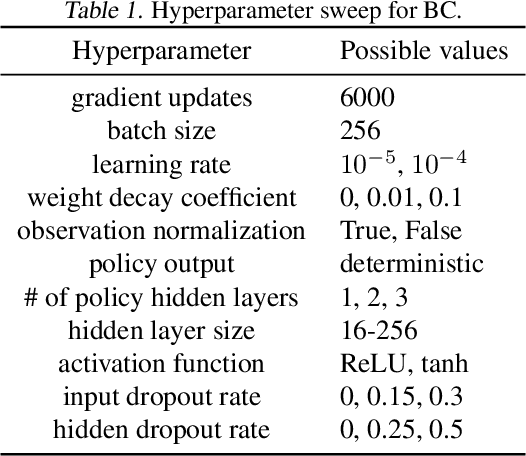
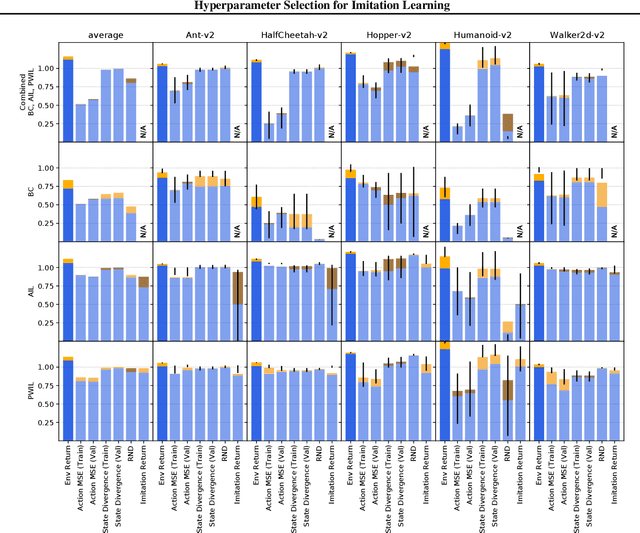
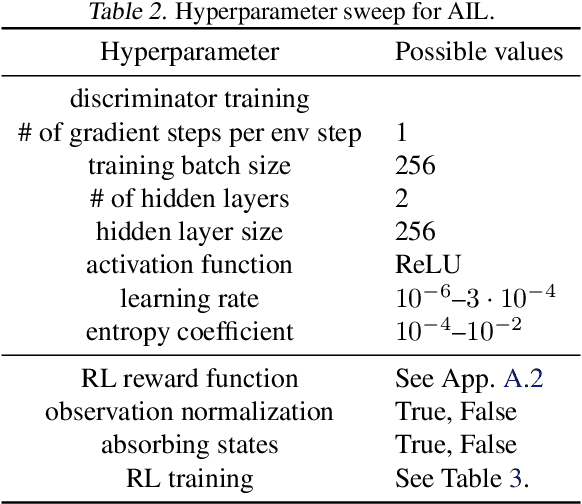
We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.