 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet Back Here: Robust Imitation by Return-to-Distribution Planning
May 02, 2023We consider the Imitation Learning (IL) setup where expert data are not collected on the actual deployment environment but on a different version. To address the resulting distribution shift, we combine behavior cloning (BC) with a planner that is tasked to bring the agent back to states visited by the expert whenever the agent deviates from the demonstration distribution. The resulting algorithm, POIR, can be trained offline, and leverages online interactions to efficiently fine-tune its planner to improve performance over time. We test POIR on a variety of human-generated manipulation demonstrations in a realistic robotic manipulation simulator and show robustness of the learned policy to different initial state distributions and noisy dynamics.
Safe Reinforcement Learning via Confidence-Based Filters
Jul 04, 2022
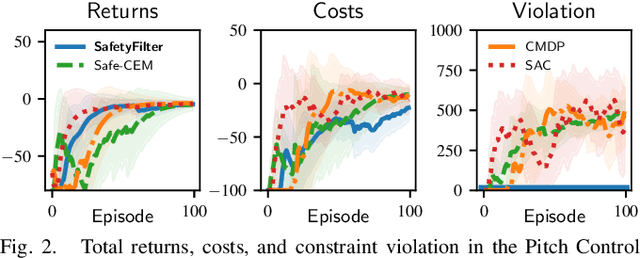
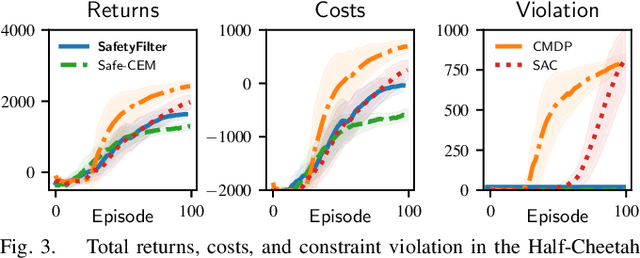

Ensuring safety is a crucial challenge when deploying reinforcement learning (RL) to real-world systems. We develop confidence-based safety filters, a control-theoretic approach for certifying state safety constraints for nominal policies learned via standard RL techniques, based on probabilistic dynamics models. Our approach is based on a reformulation of state constraints in terms of cost functions, reducing safety verification to a standard RL task. By exploiting the concept of hallucinating inputs, we extend this formulation to determine a "backup" policy that is safe for the unknown system with high probability. Finally, the nominal policy is minimally adjusted at every time step during a roll-out towards the backup policy, such that safe recovery can be guaranteed afterwards. We provide formal safety guarantees, and empirically demonstrate the effectiveness of our approach.
Constrained Policy Optimization via Bayesian World Models
Feb 06, 2022


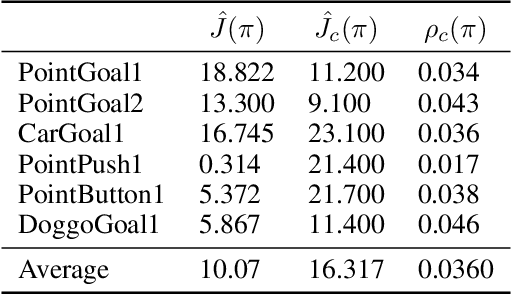
Improving sample-efficiency and safety are crucial challenges when deploying reinforcement learning in high-stakes real world applications. We propose LAMBDA, a novel model-based approach for policy optimization in safety critical tasks modeled via constrained Markov decision processes. Our approach utilizes Bayesian world models, and harnesses the resulting uncertainty to maximize optimistic upper bounds on the task objective, as well as pessimistic upper bounds on the safety constraints. We demonstrate LAMBDA's state of the art performance on the Safety-Gym benchmark suite in terms of sample efficiency and constraint violation.
Combining Pessimism with Optimism for Robust and Efficient Model-Based Deep Reinforcement Learning
Mar 18, 2021
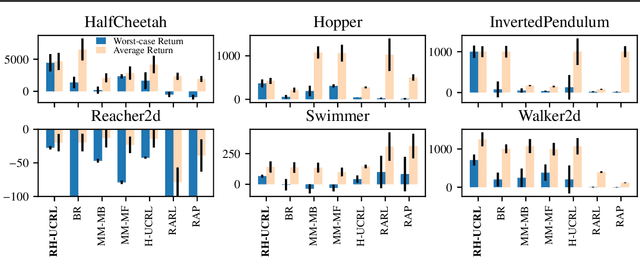


In real-world tasks, reinforcement learning (RL) agents frequently encounter situations that are not present during training time. To ensure reliable performance, the RL agents need to exhibit robustness against worst-case situations. The robust RL framework addresses this challenge via a worst-case optimization between an agent and an adversary. Previous robust RL algorithms are either sample inefficient, lack robustness guarantees, or do not scale to large problems. We propose the Robust Hallucinated Upper-Confidence RL (RH-UCRL) algorithm to provably solve this problem while attaining near-optimal sample complexity guarantees. RH-UCRL is a model-based reinforcement learning (MBRL) algorithm that effectively distinguishes between epistemic and aleatoric uncertainty and efficiently explores both the agent and adversary decision spaces during policy learning. We scale RH-UCRL to complex tasks via neural networks ensemble models as well as neural network policies. Experimentally, we demonstrate that RH-UCRL outperforms other robust deep RL algorithms in a variety of adversarial environments.
Risk-Averse Offline Reinforcement Learning
Feb 10, 2021
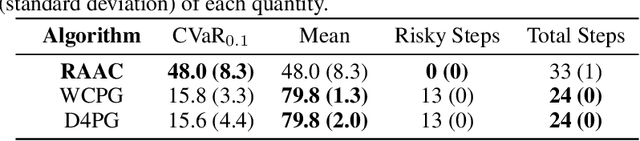

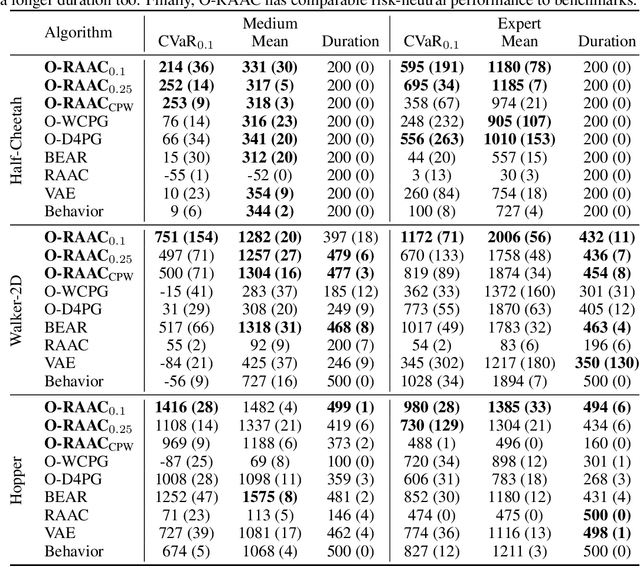
Training Reinforcement Learning (RL) agents in high-stakes applications might be too prohibitive due to the risk associated to exploration. Thus, the agent can only use data previously collected by safe policies. While previous work considers optimizing the average performance using offline data, we focus on optimizing a risk-averse criteria, namely the CVaR. In particular, we present the Offline Risk-Averse Actor-Critic (O-RAAC), a model-free RL algorithm that is able to learn risk-averse policies in a fully offline setting. We show that O-RAAC learns policies with higher CVaR than risk-neutral approaches in different robot control tasks. Furthermore, considering risk-averse criteria guarantees distributional robustness of the average performance with respect to particular distribution shifts. We demonstrate empirically that in the presence of natural distribution-shifts, O-RAAC learns policies with good average performance.
Logistic $Q$-Learning
Oct 21, 2020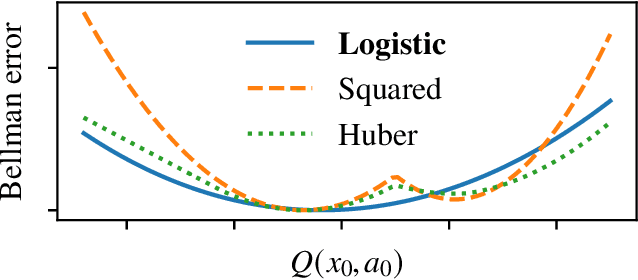
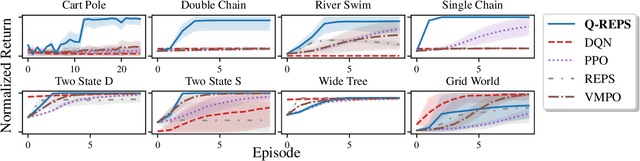
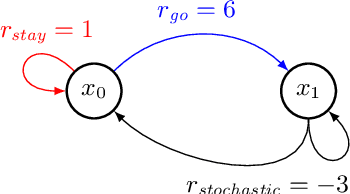
We propose a new reinforcement learning algorithm derived from a regularized linear-programming formulation of optimal control in MDPs. The method is closely related to the classic Relative Entropy Policy Search (REPS) algorithm of Peters et al. (2010), with the key difference that our method introduces a Q-function that enables efficient exact model-free implementation. The main feature of our algorithm (called QREPS) is a convex loss function for policy evaluation that serves as a theoretically sound alternative to the widely used squared Bellman error. We provide a practical saddle-point optimization method for minimizing this loss function and provide an error-propagation analysis that relates the quality of the individual updates to the performance of the output policy. Finally, we demonstrate the effectiveness of our method on a range of benchmark problems.
Efficient Model-Based Reinforcement Learning through Optimistic Policy Search and Planning
Jul 13, 2020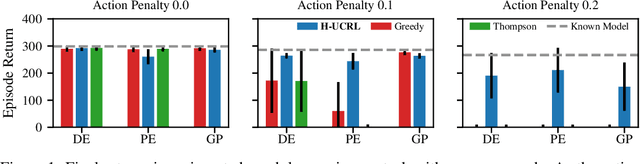

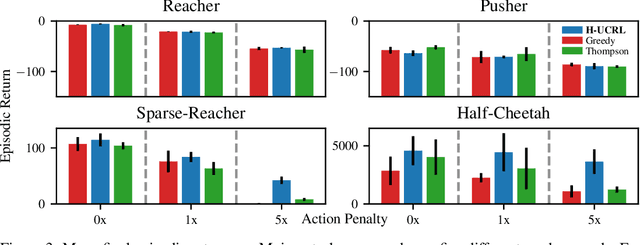

Model-based reinforcement learning algorithms with probabilistic dynamical models are amongst the most data-efficient learning methods. This is often attributed to their ability to distinguish between epistemic and aleatoric uncertainty. However, while most algorithms distinguish these two uncertainties for {\em learning} the model, they ignore it when {\em optimizing} the policy. In this paper, we show that ignoring the epistemic uncertainty leads to greedy algorithms that do not explore sufficiently. In turn, we propose a {\em practical optimistic-exploration algorithm} (\alg), which enlarges the input space with {\em hallucinated} inputs that can exert as much control as the {\em epistemic} uncertainty in the model affords. We analyze this setting and construct a general regret bound for well-calibrated models, which is provably sublinear in the case of Gaussian Process models. Based on this theoretical foundation, we show how optimistic exploration can be easily combined with state-of-the-art reinforcement learning algorithms and different probabilistic models. Our experiments demonstrate that optimistic exploration significantly speeds up learning when there are penalties on actions, a setting that is notoriously difficult for existing model-based reinforcement learning algorithms.
Learning Controllers for Unstable Linear Quadratic Regulators from a Single Trajectory
Jun 19, 2020

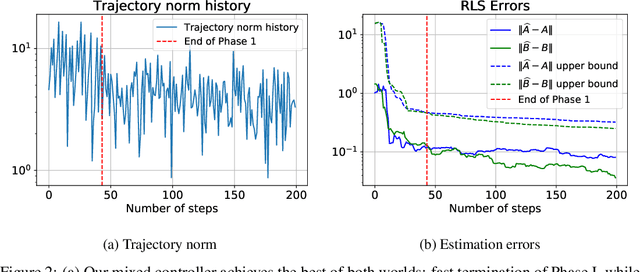
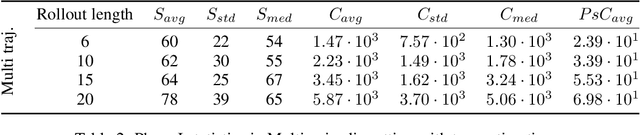
We present the first approach for learning -- from a single trajectory -- a linear quadratic regulator (LQR), even for unstable systems, without knowledge of the system dynamics and without requiring an initial stabilizing controller. Our central contribution is an efficient algorithm -- \emph{eXploration} -- that quickly identifies a stabilizing controller. Our approach utilizes robust System Level Synthesis (SLS), and we prove that it succeeds in a constant number of iterations. Our approach can be used to initialize existing algorithms that require a stabilizing controller as input. When used in this way, it yields a method for learning LQRs from a single trajectory and even for unstable systems, while suffering at most $\widetilde{\mathcal{O}}(\sqrt{T})$ regret.
Adaptive Sampling for Stochastic Risk-Averse Learning
Oct 28, 2019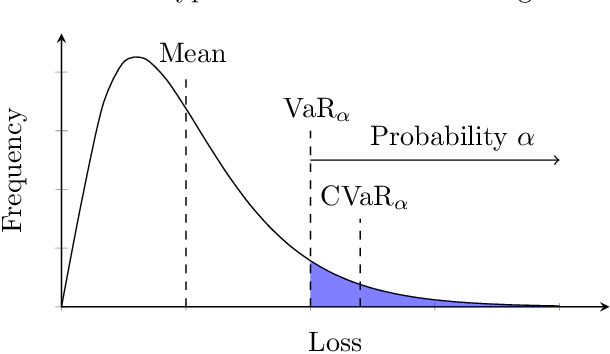
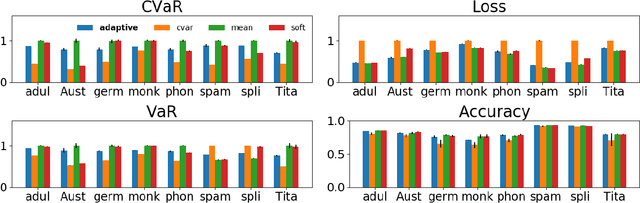

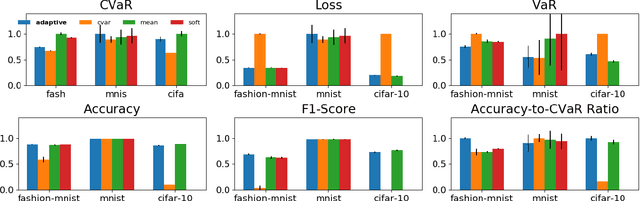
We consider the problem of training machine learning models in a risk-averse manner. In particular, we propose an adaptive sampling algorithm for stochastically optimizing the Conditional Value-at-Risk (CVaR) of a loss distribution. We use a distributionally robust formulation of the CVaR to phrase the problem as a zero-sum game between two players. Our approach solves the game using an efficient no-regret algorithm for each player. Critically, we can apply these algorithms to large-scale settings because the implementation relies on sampling from Determinantal Point Processes. Finally, we empirically demonstrate its effectiveness on large-scale convex and non-convex learning tasks.
Structured Variational Inference in Unstable Gaussian Process State Space Models
Jul 16, 2019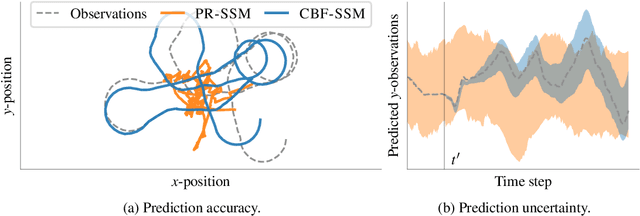
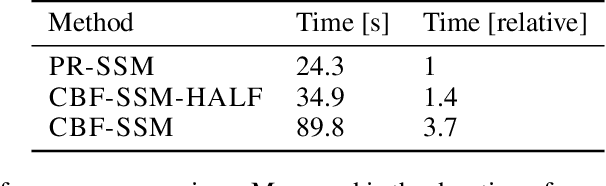
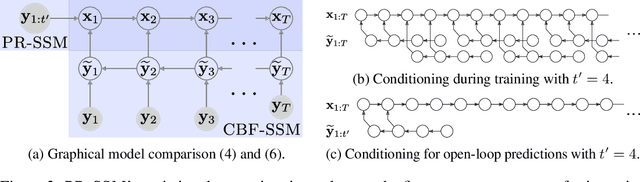
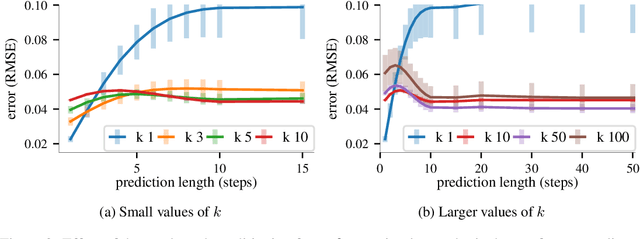
Gaussian processes are expressive, non-parametric statistical models that are well-suited to learn nonlinear dynamical systems. However, large-scale inference in these state space models is a challenging problem. In this paper, we propose CBF-SSM a scalable model that employs a structured variational approximation to maintain temporal correlations. In contrast to prior work, our approach applies to the important class of unstable systems, where state uncertainty grows unbounded over time. For these systems, our method contains a probabilistic, model-based backward pass that infers latent states during training. We demonstrate state-of-the-art performance in our experiments. Moreover, we show that CBF-SSM can be combined with physical models in the form of ordinary differential equations to learn a reliable model of a physical flying robotic vehicle.