Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling for Stochastic Risk-Averse Learning
Oct 28, 2019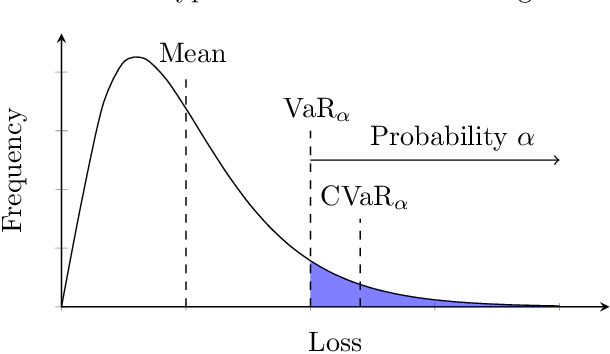
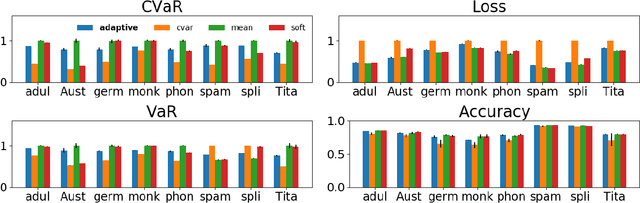

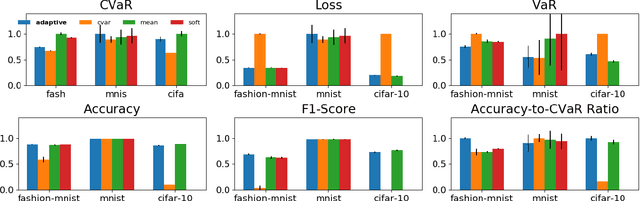
We consider the problem of training machine learning models in a risk-averse manner. In particular, we propose an adaptive sampling algorithm for stochastically optimizing the Conditional Value-at-Risk (CVaR) of a loss distribution. We use a distributionally robust formulation of the CVaR to phrase the problem as a zero-sum game between two players. Our approach solves the game using an efficient no-regret algorithm for each player. Critically, we can apply these algorithms to large-scale settings because the implementation relies on sampling from Determinantal Point Processes. Finally, we empirically demonstrate its effectiveness on large-scale convex and non-convex learning tasks.
Via