 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task GRPO: Reliable LLM Reasoning Across Tasks
Feb 05, 2026RL-based post-training with GRPO is widely used to improve large language models on individual reasoning tasks. However, real-world deployment requires reliable performance across diverse tasks. A straightforward multi-task adaptation of GRPO often leads to imbalanced outcomes, with some tasks dominating optimization while others stagnate. Moreover, tasks can vary widely in how frequently prompts yield zero advantages (and thus zero gradients), which further distorts their effective contribution to the optimization signal. To address these issues, we propose a novel Multi-Task GRPO (MT-GRPO) algorithm that (i) dynamically adapts task weights to explicitly optimize worst-task performance and promote balanced progress across tasks, and (ii) introduces a ratio-preserving sampler to ensure task-wise policy gradients reflect the adapted weights. Experiments on both 3-task and 9-task settings show that MT-GRPO consistently outperforms baselines in worst-task accuracy. In particular, MT-GRPO achieves 16-28% and 6% absolute improvement on worst-task performance over standard GRPO and DAPO, respectively, while maintaining competitive average accuracy. Moreover, MT-GRPO requires 50% fewer training steps to reach 50% worst-task accuracy in the 3-task setting, demonstrating substantially improved efficiency in achieving reliable performance across tasks.
Robust Bayesian Optimisation with Unbounded Corruptions
Nov 19, 2025Bayesian Optimization is critically vulnerable to extreme outliers. Existing provably robust methods typically assume a bounded cumulative corruption budget, which makes them defenseless against even a single corruption of sufficient magnitude. To address this, we introduce a new adversary whose budget is only bounded in the frequency of corruptions, not in their magnitude. We then derive RCGP-UCB, an algorithm coupling the famous upper confidence bound (UCB) approach with a Robust Conjugate Gaussian Process (RCGP). We present stable and adaptive versions of RCGP-UCB, and prove that they achieve sublinear regret in the presence of up to $O(T^{1/2})$ and $O(T^{1/3})$ corruptions with possibly infinite magnitude. This robustness comes at near zero cost: without outliers, RCGP-UCB's regret bounds match those of the standard GP-UCB algorithm.
Synthetic Data is Sufficient for Zero-Shot Visual Generalization from Offline Data
Aug 17, 2025Offline reinforcement learning (RL) offers a promising framework for training agents using pre-collected datasets without the need for further environment interaction. However, policies trained on offline data often struggle to generalise due to limited exposure to diverse states. The complexity of visual data introduces additional challenges such as noise, distractions, and spurious correlations, which can misguide the policy and increase the risk of overfitting if the training data is not sufficiently diverse. Indeed, this makes it challenging to leverage vision-based offline data in training robust agents that can generalize to unseen environments. To solve this problem, we propose a simple approach generating additional synthetic training data. We propose a two-step process, first augmenting the originally collected offline data to improve zero-shot generalization by introducing diversity, then using a diffusion model to generate additional data in latent space. We test our method across both continuous action spaces (Visual D4RL) and discrete action spaces (Procgen), demonstrating that it significantly improves generalization without requiring any algorithmic changes to existing model-free offline RL methods. We show that our method not only increases the diversity of the training data but also significantly reduces the generalization gap at test time while maintaining computational efficiency. We believe this approach could fuel additional progress in generating synthetic data to train more general agents in the future.
Robust Multi-Objective Controlled Decoding of Large Language Models
Mar 11, 2025
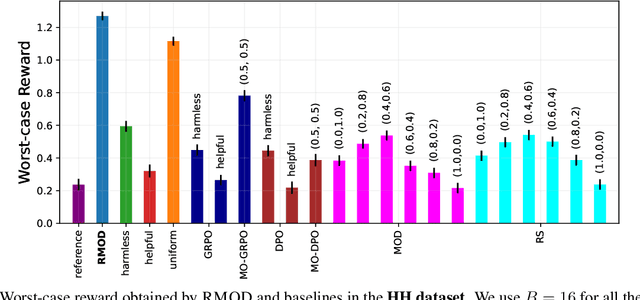
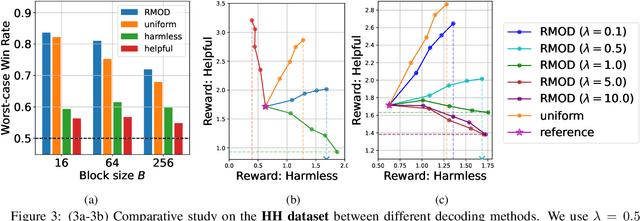
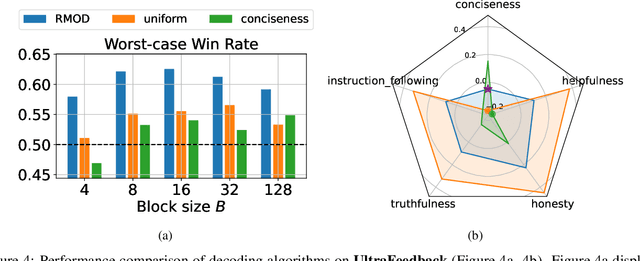
Test-time alignment of Large Language Models (LLMs) to human preferences offers a flexible way to generate responses aligned to diverse objectives without extensive retraining of LLMs. Existing methods achieve alignment to multiple objectives simultaneously (e.g., instruction-following, helpfulness, conciseness) by optimizing their corresponding reward functions. However, they often rely on predefined weights or optimize for averages, sacrificing one objective for another and leading to unbalanced outcomes. To address this, we introduce Robust Multi-Objective Decoding (RMOD), a novel inference-time algorithm that optimizes for improving worst-case rewards. RMOD formalizes the robust decoding problem as a maximin two-player game between reward weights and the sampling policy, solving for the Nash equilibrium. We show that the game reduces to a convex optimization problem to find the worst-case weights, while the best response policy can be computed analytically. We also introduce a practical RMOD variant designed for efficient decoding with contemporary LLMs, incurring minimal computational overhead compared to non-robust Multi-Objective Decoding (MOD) methods. Our experimental results showcase the effectiveness of RMOD in generating responses equitably aligned with diverse objectives, outperforming baselines up to 20%.
This Is Your Doge, If It Please You: Exploring Deception and Robustness in Mixture of LLMs
Mar 07, 2025Mixture of large language model (LLMs) Agents (MoA) architectures achieve state-of-the-art performance on prominent benchmarks like AlpacaEval 2.0 by leveraging the collaboration of multiple LLMs at inference time. Despite these successes, an evaluation of the safety and reliability of MoA is missing. We present the first comprehensive study of MoA's robustness against deceptive LLM agents that deliberately provide misleading responses. We examine factors like the propagation of deceptive information, model size, and information availability, and uncover critical vulnerabilities. On AlpacaEval 2.0, the popular LLaMA 3.1-70B model achieves a length-controlled Win Rate (LC WR) of 49.2% when coupled with 3-layer MoA (6 LLM agents). However, we demonstrate that introducing only a $\textit{single}$ carefully-instructed deceptive agent into the MoA can reduce performance to 37.9%, effectively nullifying all MoA gains. On QuALITY, a multiple-choice comprehension task, the impact is also severe, with accuracy plummeting by a staggering 48.5%. Inspired in part by the historical Doge of Venice voting process, designed to minimize influence and deception, we propose a range of unsupervised defense mechanisms that recover most of the lost performance.
Mean-Field Bayesian Optimisation
Feb 17, 2025
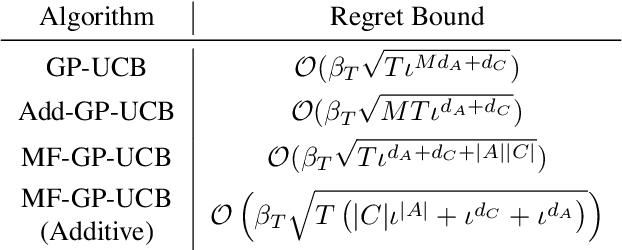
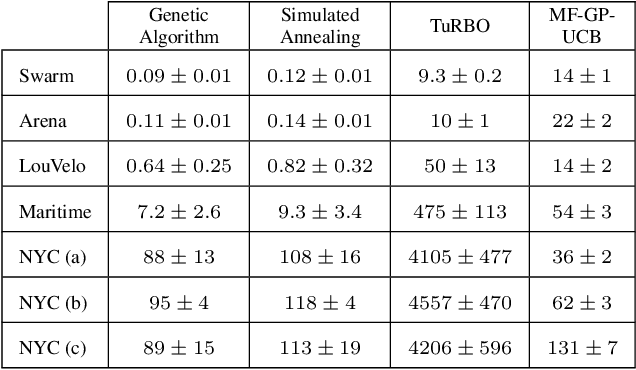
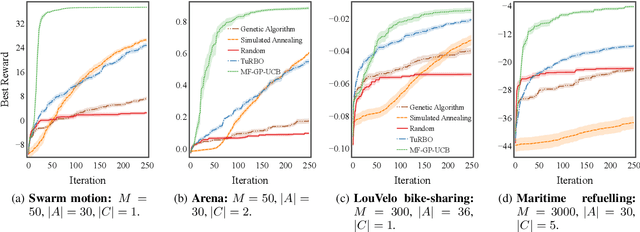
We address the problem of optimising the average payoff for a large number of cooperating agents, where the payoff function is unknown and treated as a black box. While standard Bayesian Optimisation (BO) methods struggle with the scalability required for high-dimensional input spaces, we demonstrate how leveraging the mean-field assumption on the black-box function can transform BO into an efficient and scalable solution. Specifically, we introduce MF-GP-UCB, a novel efficient algorithm designed to optimise agent payoffs in this setting. Our theoretical analysis establishes a regret bound for MF-GP-UCB that is independent of the number of agents, contrasting sharply with the exponential dependence observed when naive BO methods are applied. We evaluate our algorithm on a diverse set of tasks, including real-world problems, such as optimising the location of public bikes for a bike-sharing programme, distributing taxi fleets, and selecting refuelling ports for maritime vessels. Empirical results demonstrate that MF-GP-UCB significantly outperforms existing benchmarks, offering substantial improvements in performance and scalability, constituting a promising solution for mean-field, black-box optimisation. The code is available at https://github.com/petarsteinberg/MF-BO.
Almost Surely Safe Alignment of Large Language Models at Inference-Time
Feb 03, 2025Even highly capable large language models (LLMs) can produce biased or unsafe responses, and alignment techniques, such as RLHF, aimed at mitigating this issue, are expensive and prone to overfitting as they retrain the LLM. This paper introduces a novel inference-time alignment approach that ensures LLMs generate safe responses almost surely, i.e., with a probability approaching one. We achieve this by framing the safe generation of inference-time responses as a constrained Markov decision process within the LLM's latent space. Crucially, we augment a safety state that tracks the evolution of safety constraints and enables us to demonstrate formal safety guarantees upon solving the MDP in the latent space. Building on this foundation, we propose InferenceGuard, a practical implementation that safely aligns LLMs without modifying the model weights. Empirically, we demonstrate InferenceGuard effectively balances safety and task performance, outperforming existing inference-time alignment methods in generating safe and aligned responses.
No-Regret Linear Bandits under Gap-Adjusted Misspecification
Jan 09, 2025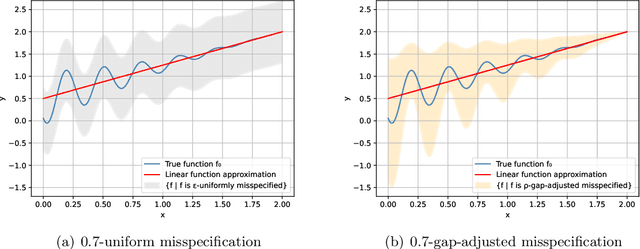
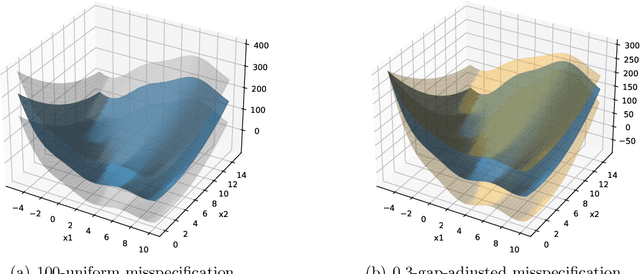
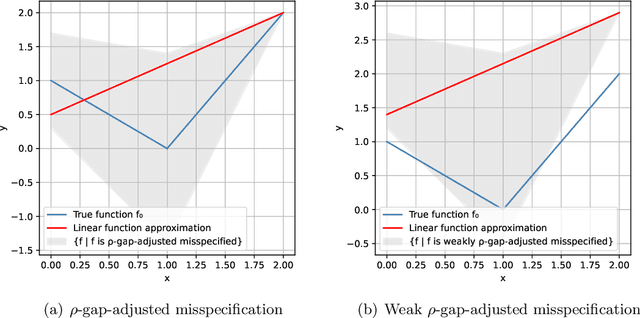
This work studies linear bandits under a new notion of gap-adjusted misspecification and is an extension of Liu et al. (2023). When the underlying reward function is not linear, existing linear bandits work usually relies on a uniform misspecification parameter $\epsilon$ that measures the sup-norm error of the best linear approximation. This results in an unavoidable linear regret whenever $\epsilon > 0$. We propose a more natural model of misspecification which only requires the approximation error at each input $x$ to be proportional to the suboptimality gap at $x$. It captures the intuition that, for optimization problems, near-optimal regions should matter more and we can tolerate larger approximation errors in suboptimal regions. Quite surprisingly, we show that the classical LinUCB algorithm -- designed for the realizable case -- is automatically robust against such $\rho$-gap-adjusted misspecification with parameter $\rho$ diminishing at $O(1/(d \sqrt{\log T}))$. It achieves a near-optimal $O(\sqrt{T})$ regret for problems that the best-known regret is almost linear in time horizon $T$. We further advance this frontier by presenting a novel phased elimination-based algorithm whose gap-adjusted misspecification parameter $\rho = O(1/\sqrt{d})$ does not scale with $T$. This algorithm attains optimal $O(\sqrt{T})$ regret and is deployment-efficient, requiring only $\log T$ batches of exploration. It also enjoys an adaptive $O(\log T)$ regret when a constant suboptimality gap exists. Technically, our proof relies on a novel self-bounding argument that bounds the part of the regret due to misspecification by the regret itself, and a new inductive lemma that limits the misspecification error within the suboptimality gap for all valid actions in each batch selected by G-optimal design.
Sample-efficient Bayesian Optimisation Using Known Invariances
Oct 22, 2024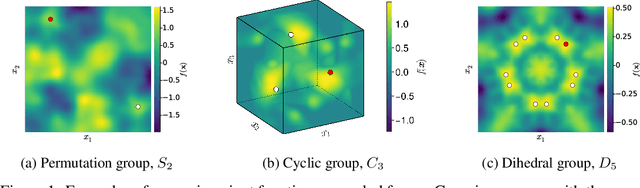
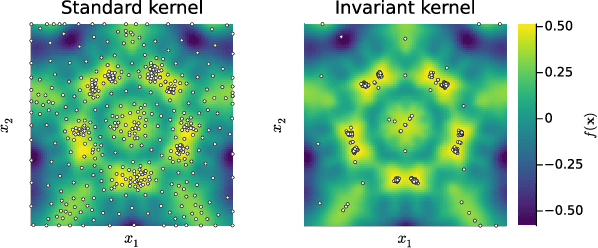
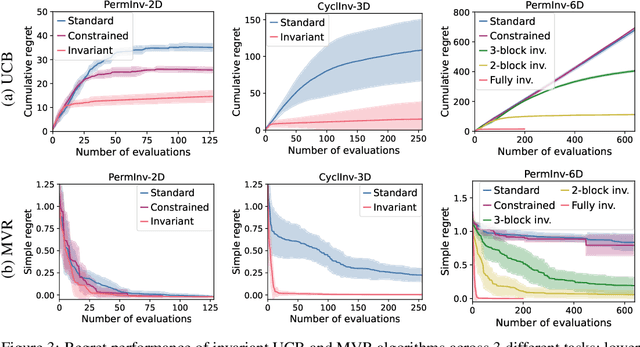
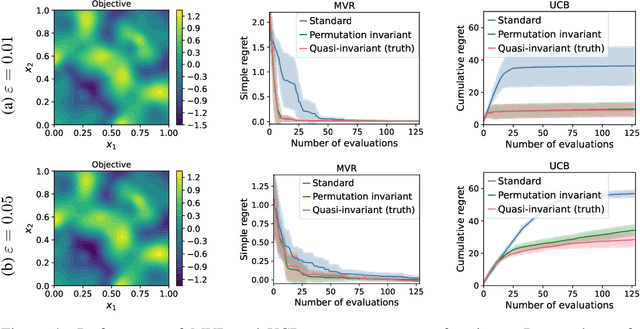
Bayesian optimisation (BO) is a powerful framework for global optimisation of costly functions, using predictions from Gaussian process models (GPs). In this work, we apply BO to functions that exhibit invariance to a known group of transformations. We show that vanilla and constrained BO algorithms are inefficient when optimising such invariant objectives, and provide a method for incorporating group invariances into the kernel of the GP to produce invariance-aware algorithms that achieve significant improvements in sample efficiency. We derive a bound on the maximum information gain of these invariant kernels, and provide novel upper and lower bounds on the number of observations required for invariance-aware BO algorithms to achieve $\epsilon$-optimality. We demonstrate our method's improved performance on a range of synthetic invariant and quasi-invariant functions. We also apply our method in the case where only some of the invariance is incorporated into the kernel, and find that these kernels achieve similar gains in sample efficiency at significantly reduced computational cost. Finally, we use invariant BO to design a current drive system for a nuclear fusion reactor, finding a high-performance solution where non-invariant methods failed.
Right Now, Wrong Then: Non-Stationary Direct Preference Optimization under Preference Drift
Jul 26, 2024



Reinforcement learning from human feedback (RLHF) aligns Large Language Models (LLMs) with human preferences. However, these preferences can often change over time due to external factors (e.g. environment change and societal influence). Consequently, what was wrong then might be right now. Current preference optimization algorithms do not account for temporal preference drift in their modeling, which can lead to severe misalignment. To address this limitation, we use a Dynamic Bradley-Terry model that models preferences via time-dependent reward functions, and propose Non-Stationary Direct Preference Optimisation (NS-DPO). By introducing a discount parameter in the loss function, NS-DPO applies exponential weighting, which proportionally focuses learning on more time-relevant datapoints. We theoretically analyse the convergence of NS-DPO in the offline setting, providing upper bounds on the estimation error caused by non-stationary preferences. Finally, we demonstrate the effectiveness of NS-DPO1 for fine-tuning LLMs in scenarios with drifting preferences. By simulating preference drift using renowned reward models and modifying popular LLM datasets accordingly, we show that NS-DPO fine-tuned LLMs remain robust under non-stationarity, significantly outperforming baseline algorithms that ignore temporal preference changes, without sacrificing performance in stationary cases.