 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Router: Routing in Multi-turn Agentic Software Engineering Tasks
Jun 30, 2026Large language models (LLMs) embedded in multi-turn agentic harnesses are reshaping software engineering (SWE), but routing every task to a frontier model is wasteful when many issues admit cheap fixes. Existing LLM routers operate on the task description alone, which inherits an information-theoretic Bayes-error floor in agentic settings: a similar issue can hide either a localized typo or a multi-module refactor, and the prompt does not separate the two. We introduce SWE-Router, a value-based temporal approach that lets a cheap model run for a few exploratory turns and reads the resulting partial trajectory before deciding whether to continue cheaply or to escalate to an expensive model. We provide a Bayes-optimality theorem showing that conditioning on the partial trajectory never harms routing and is strictly better whenever exploration is informative. Across the LLM pairs of weak and strong models spanning the contemporary cost--capability frontier, we show that SWE-Router greatly improves the cost efficiency of SWE tasks, while maintaining the majority of the performances of the stronger model. We additionally release a multi-LLM trajectory dataset which allows reproduction of our trajectory-level routing.
GDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
May 28, 2026Reinforcement learning (RL) can be used to improve the policy (denoiser) of diffusion large language models (dLLMs), while being hindered by the intractability of the policy likelihood. A dominant and efficient family of methods replaces the likelihood in standard RL with its evidence lower bound (ELBO), estimated from randomly masked sequences. Despite being well aligned with pre-training, these approaches introduce bias through training--inference mismatch by using the ELBO as a likelihood surrogate, which can degrade performance. In this work, we propose Guided Denoiser Self-Distillation (GDSD) to directly distill the denoiser of dLLMs from an advantage-guided self-teacher, derived from the closed-form optimum of reverse-KL regularized RL. GDSD matches the dLLM's denoiser logits to the teacher's via a normalization-free objective, which reduces RL to likelihood-free self-distillation and thus bypasses the TIM biases. Recent ELBO-based methods emerge as instances of applying different distillation divergences, but with diagnosable pathologies that GDSD avoids. On planning, math, and coding benchmarks with LLaDA-8B and Dream-7B, GDSD consistently outperforms prior state-of-the-art ELBO-based methods with a more stable training reward dynamics, achieving test-accuracy improvements of up to $+19.6\%$. These results suggest that direct denoiser self-distillation, without relying on an ELBO likelihood surrogate, can provide a more stable and effective RL procedure for dLLMs. Code is available at https://github.com/GaryBall/GDSD.
Multi-Task GRPO: Reliable LLM Reasoning Across Tasks
Feb 05, 2026RL-based post-training with GRPO is widely used to improve large language models on individual reasoning tasks. However, real-world deployment requires reliable performance across diverse tasks. A straightforward multi-task adaptation of GRPO often leads to imbalanced outcomes, with some tasks dominating optimization while others stagnate. Moreover, tasks can vary widely in how frequently prompts yield zero advantages (and thus zero gradients), which further distorts their effective contribution to the optimization signal. To address these issues, we propose a novel Multi-Task GRPO (MT-GRPO) algorithm that (i) dynamically adapts task weights to explicitly optimize worst-task performance and promote balanced progress across tasks, and (ii) introduces a ratio-preserving sampler to ensure task-wise policy gradients reflect the adapted weights. Experiments on both 3-task and 9-task settings show that MT-GRPO consistently outperforms baselines in worst-task accuracy. In particular, MT-GRPO achieves 16-28% and 6% absolute improvement on worst-task performance over standard GRPO and DAPO, respectively, while maintaining competitive average accuracy. Moreover, MT-GRPO requires 50% fewer training steps to reach 50% worst-task accuracy in the 3-task setting, demonstrating substantially improved efficiency in achieving reliable performance across tasks.
Robust Multi-Objective Controlled Decoding of Large Language Models
Mar 11, 2025
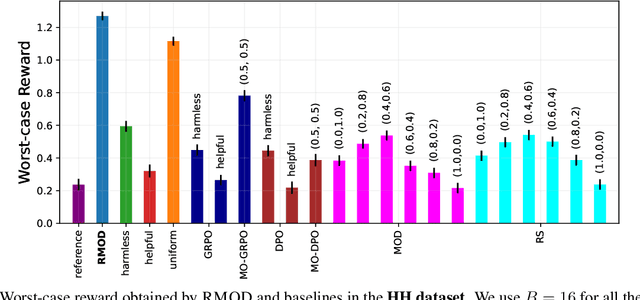
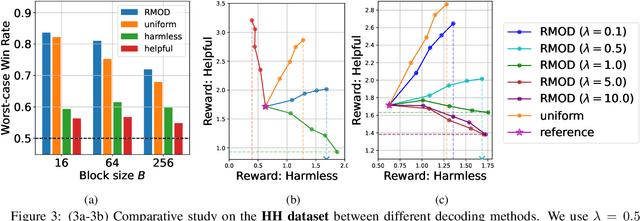
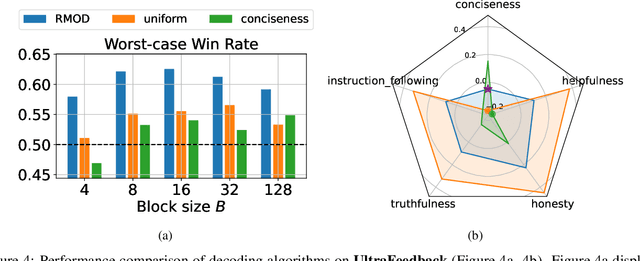
Test-time alignment of Large Language Models (LLMs) to human preferences offers a flexible way to generate responses aligned to diverse objectives without extensive retraining of LLMs. Existing methods achieve alignment to multiple objectives simultaneously (e.g., instruction-following, helpfulness, conciseness) by optimizing their corresponding reward functions. However, they often rely on predefined weights or optimize for averages, sacrificing one objective for another and leading to unbalanced outcomes. To address this, we introduce Robust Multi-Objective Decoding (RMOD), a novel inference-time algorithm that optimizes for improving worst-case rewards. RMOD formalizes the robust decoding problem as a maximin two-player game between reward weights and the sampling policy, solving for the Nash equilibrium. We show that the game reduces to a convex optimization problem to find the worst-case weights, while the best response policy can be computed analytically. We also introduce a practical RMOD variant designed for efficient decoding with contemporary LLMs, incurring minimal computational overhead compared to non-robust Multi-Objective Decoding (MOD) methods. Our experimental results showcase the effectiveness of RMOD in generating responses equitably aligned with diverse objectives, outperforming baselines up to 20%.
This Is Your Doge, If It Please You: Exploring Deception and Robustness in Mixture of LLMs
Mar 07, 2025Mixture of large language model (LLMs) Agents (MoA) architectures achieve state-of-the-art performance on prominent benchmarks like AlpacaEval 2.0 by leveraging the collaboration of multiple LLMs at inference time. Despite these successes, an evaluation of the safety and reliability of MoA is missing. We present the first comprehensive study of MoA's robustness against deceptive LLM agents that deliberately provide misleading responses. We examine factors like the propagation of deceptive information, model size, and information availability, and uncover critical vulnerabilities. On AlpacaEval 2.0, the popular LLaMA 3.1-70B model achieves a length-controlled Win Rate (LC WR) of 49.2% when coupled with 3-layer MoA (6 LLM agents). However, we demonstrate that introducing only a $\textit{single}$ carefully-instructed deceptive agent into the MoA can reduce performance to 37.9%, effectively nullifying all MoA gains. On QuALITY, a multiple-choice comprehension task, the impact is also severe, with accuracy plummeting by a staggering 48.5%. Inspired in part by the historical Doge of Venice voting process, designed to minimize influence and deception, we propose a range of unsupervised defense mechanisms that recover most of the lost performance.
Value Gradient Sampler: Sampling as Sequential Decision Making
Feb 18, 2025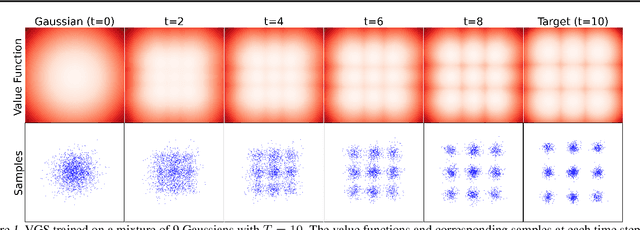

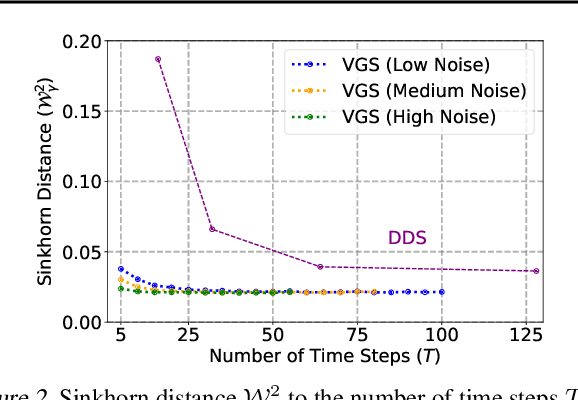

We propose the Value Gradient Sampler (VGS), a trainable sampler based on the interpretation of sampling as discrete-time sequential decision-making. VGS generates samples from a given unnormalized density (i.e., energy) by drifting and diffusing randomly initialized particles. In VGS, finding the optimal drift is equivalent to solving an optimal control problem where the cost is the upper bound of the KL divergence between the target density and the samples. We employ value-based dynamic programming to solve this optimal control problem, which gives the gradient of the value function as the optimal drift vector. The connection to sequential decision making allows VGS to leverage extensively studied techniques in reinforcement learning, making VGS a fast, adaptive, and accurate sampler that achieves competitive results in various sampling benchmarks. Furthermore, VGS can replace MCMC in contrastive divergence training of energy-based models. We demonstrate the effectiveness of VGS in training accurate energy-based models in industrial anomaly detection applications.
Maximum Entropy Inverse Reinforcement Learning of Diffusion Models with Energy-Based Models
Jun 30, 2024
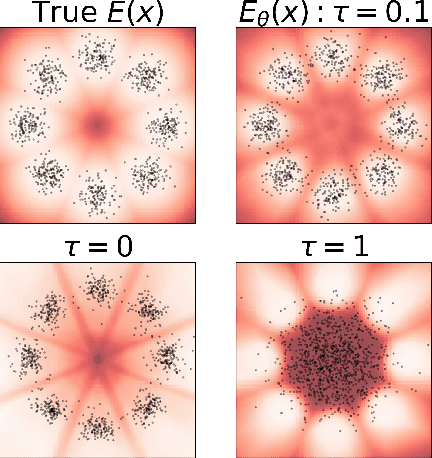
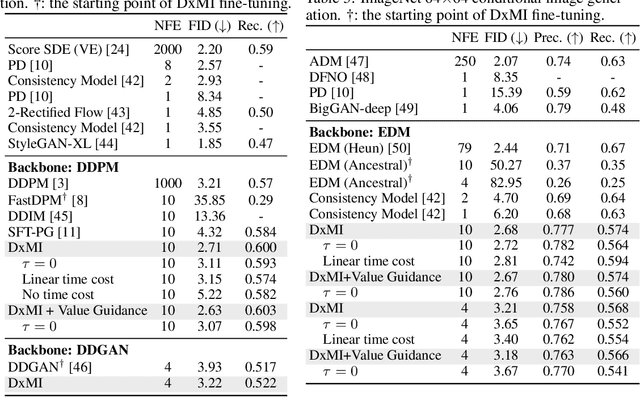

We present a maximum entropy inverse reinforcement learning (IRL) approach for improving the sample quality of diffusion generative models, especially when the number of generation time steps is small. Similar to how IRL trains a policy based on the reward function learned from expert demonstrations, we train (or fine-tune) a diffusion model using the log probability density estimated from training data. Since we employ an energy-based model (EBM) to represent the log density, our approach boils down to the joint training of a diffusion model and an EBM. Our IRL formulation, named Diffusion by Maximum Entropy IRL (DxMI), is a minimax problem that reaches equilibrium when both models converge to the data distribution. The entropy maximization plays a key role in DxMI, facilitating the exploration of the diffusion model and ensuring the convergence of the EBM. We also propose Diffusion by Dynamic Programming (DxDP), a novel reinforcement learning algorithm for diffusion models, as a subroutine in DxMI. DxDP makes the diffusion model update in DxMI efficient by transforming the original problem into an optimal control formulation where value functions replace back-propagation in time. Our empirical studies show that diffusion models fine-tuned using DxMI can generate high-quality samples in as few as 4 and 10 steps. Additionally, DxMI enables the training of an EBM without MCMC, stabilizing EBM training dynamics and enhancing anomaly detection performance.
Generalized Contrastive Divergence: Joint Training of Energy-Based Model and Diffusion Model through Inverse Reinforcement Learning
Dec 06, 2023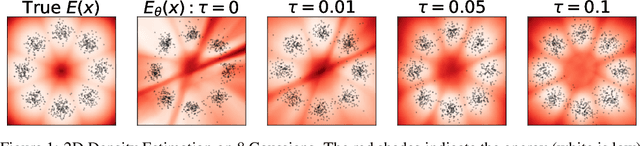
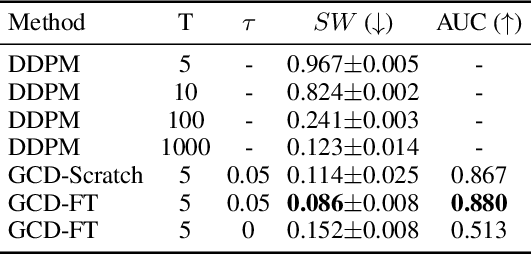

We present Generalized Contrastive Divergence (GCD), a novel objective function for training an energy-based model (EBM) and a sampler simultaneously. GCD generalizes Contrastive Divergence (Hinton, 2002), a celebrated algorithm for training EBM, by replacing Markov Chain Monte Carlo (MCMC) distribution with a trainable sampler, such as a diffusion model. In GCD, the joint training of EBM and a diffusion model is formulated as a minimax problem, which reaches an equilibrium when both models converge to the data distribution. The minimax learning with GCD bears interesting equivalence to inverse reinforcement learning, where the energy corresponds to a negative reward, the diffusion model is a policy, and the real data is expert demonstrations. We present preliminary yet promising results showing that joint training is beneficial for both EBM and a diffusion model. GCD enables EBM training without MCMC while improving the sample quality of a diffusion model.
Variational Weighting for Kernel Density Ratios
Nov 06, 2023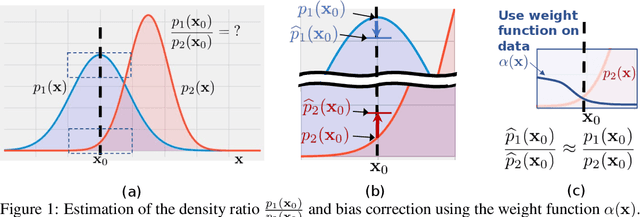
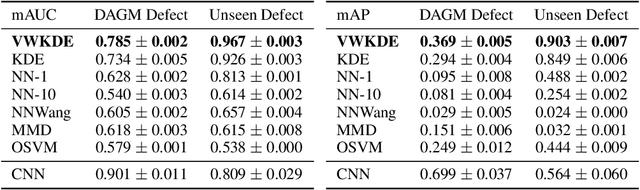
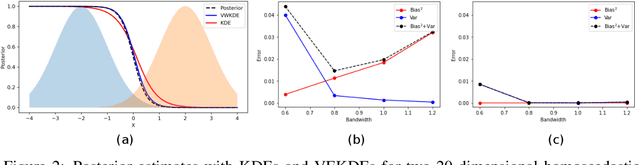

Kernel density estimation (KDE) is integral to a range of generative and discriminative tasks in machine learning. Drawing upon tools from the multidimensional calculus of variations, we derive an optimal weight function that reduces bias in standard kernel density estimates for density ratios, leading to improved estimates of prediction posteriors and information-theoretic measures. In the process, we shed light on some fundamental aspects of density estimation, particularly from the perspective of algorithms that employ KDEs as their main building blocks.
Energy-Based Models for Anomaly Detection: A Manifold Diffusion Recovery Approach
Oct 28, 2023
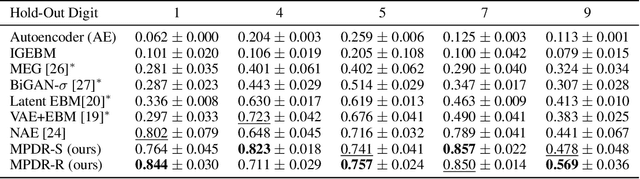

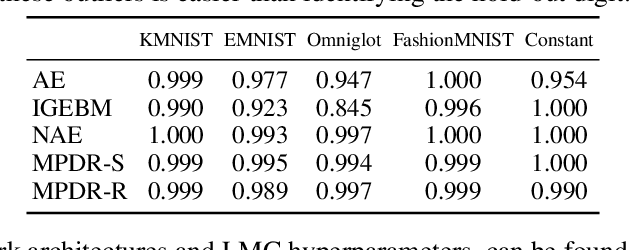
We present a new method of training energy-based models (EBMs) for anomaly detection that leverages low-dimensional structures within data. The proposed algorithm, Manifold Projection-Diffusion Recovery (MPDR), first perturbs a data point along a low-dimensional manifold that approximates the training dataset. Then, EBM is trained to maximize the probability of recovering the original data. The training involves the generation of negative samples via MCMC, as in conventional EBM training, but from a different distribution concentrated near the manifold. The resulting near-manifold negative samples are highly informative, reflecting relevant modes of variation in data. An energy function of MPDR effectively learns accurate boundaries of the training data distribution and excels at detecting out-of-distribution samples. Experimental results show that MPDR exhibits strong performance across various anomaly detection tasks involving diverse data types, such as images, vectors, and acoustic signals.