 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness of Diffusion-Based Zero-Shot Speech Synthesis via Stable Formant Generation
Sep 14, 2024



Diffusion models have achieved remarkable success in text-to-speech (TTS), even in zero-shot scenarios. Recent efforts aim to address the trade-off between inference speed and sound quality, often considered the primary drawback of diffusion models. However, we find a critical mispronunciation issue is being overlooked. Our preliminary study reveals the unstable pronunciation resulting from the diffusion process. Based on this observation, we introduce StableForm-TTS, a novel zero-shot speech synthesis framework designed to produce robust pronunciation while maintaining the advantages of diffusion modeling. By pioneering the adoption of source-filter theory in diffusion TTS, we propose an elaborate architecture for stable formant generation. Experimental results on unseen speakers show that our model outperforms the state-of-the-art method in terms of pronunciation accuracy and naturalness, with comparable speaker similarity. Moreover, our model demonstrates effective scalability as both data and model sizes increase.
Good Neighbors Are All You Need for Chinese Grapheme-to-Phoneme Conversion
Mar 14, 2023



Most Chinese Grapheme-to-Phoneme (G2P) systems employ a three-stage framework that first transforms input sequences into character embeddings, obtains linguistic information using language models, and then predicts the phonemes based on global context about the entire input sequence. However, linguistic knowledge alone is often inadequate. Language models frequently encode overly general structures of a sentence and fail to cover specific cases needed to use phonetic knowledge. Also, a handcrafted post-processing system is needed to address the problems relevant to the tone of the characters. However, the system exhibits inconsistency in the segmentation of word boundaries which consequently degrades the performance of the G2P system. To address these issues, we propose the Reinforcer that provides strong inductive bias for language models by emphasizing the phonological information between neighboring characters to help disambiguate pronunciations. Experimental results show that the Reinforcer boosts the cutting-edge architectures by a large margin. We also combine the Reinforcer with a large-scale pre-trained model and demonstrate the validity of using neighboring context in knowledge transfer scenarios.
Image-to-Image Retrieval by Learning Similarity between Scene Graphs
Dec 29, 2020

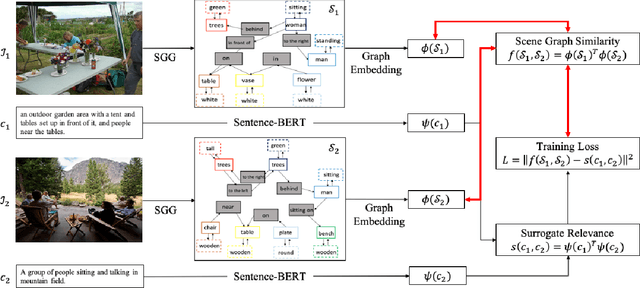
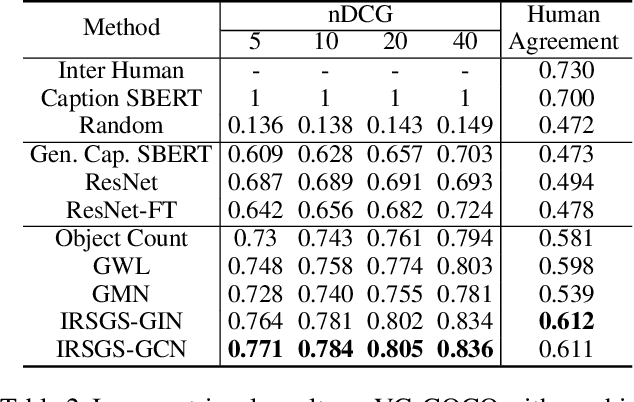
As a scene graph compactly summarizes the high-level content of an image in a structured and symbolic manner, the similarity between scene graphs of two images reflects the relevance of their contents. Based on this idea, we propose a novel approach for image-to-image retrieval using scene graph similarity measured by graph neural networks. In our approach, graph neural networks are trained to predict the proxy image relevance measure, computed from human-annotated captions using a pre-trained sentence similarity model. We collect and publish the dataset for image relevance measured by human annotators to evaluate retrieval algorithms. The collected dataset shows that our method agrees well with the human perception of image similarity than other competitive baselines.