 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNote-Level Singing Melody Transcription for Time-Aligned Musical Score Generation
Feb 18, 2025



Automatic music transcription converts audio recordings into symbolic representations, facilitating music analysis, retrieval, and generation. A musical note is characterized by pitch, onset, and offset in an audio domain, whereas it is defined in terms of pitch and note value in a musical score domain. A time-aligned score, derived from timing information along with pitch and note value, allows matching a part of the score with the corresponding part of the music audio, enabling various applications. In this paper, we consider an extended version of the traditional note-level transcription task that recognizes onset, offset, and pitch, through including extraction of additional note value to generate a time-aligned score from an audio input. To address this new challenge, we propose an end-to-end framework that integrates recognition of the note value, pitch, and temporal information. This approach avoids error accumulation inherent in multi-stage methods and enhances accuracy through mutual reinforcement. Our framework employs tokenized representations specifically targeted for this task, through incorporating note value information. Furthermore, we introduce a pseudo-labeling technique to address a scarcity problem of annotated note value data. This technique produces approximate note value labels from existing datasets for the traditional note-level transcription. Experimental results demonstrate the superior performance of the proposed model in note-level transcription tasks when compared to existing state-of-the-art approaches. We also introduce new evaluation metrics that assess both temporal and note value aspects to demonstrate the robustness of the model. Moreover, qualitative assessments via visualized musical scores confirmed the effectiveness of our model in capturing the note values.
Image-to-Image Retrieval by Learning Similarity between Scene Graphs
Dec 29, 2020

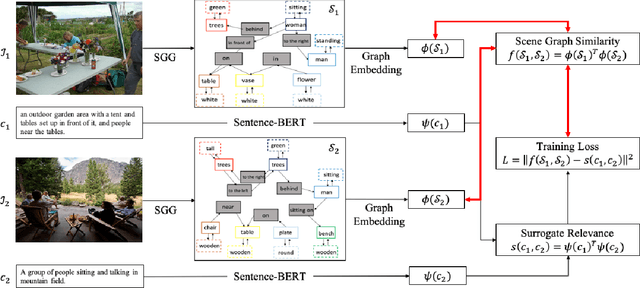
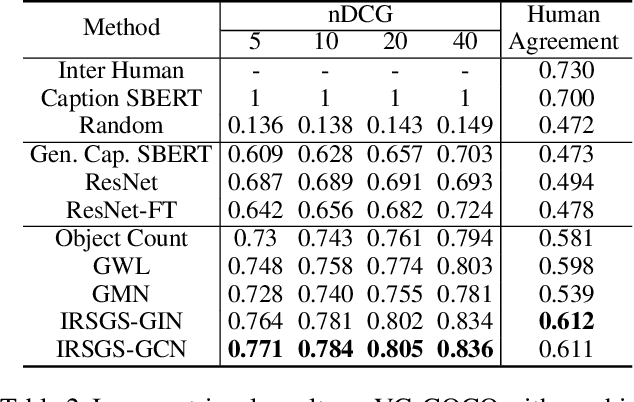
As a scene graph compactly summarizes the high-level content of an image in a structured and symbolic manner, the similarity between scene graphs of two images reflects the relevance of their contents. Based on this idea, we propose a novel approach for image-to-image retrieval using scene graph similarity measured by graph neural networks. In our approach, graph neural networks are trained to predict the proxy image relevance measure, computed from human-annotated captions using a pre-trained sentence similarity model. We collect and publish the dataset for image relevance measured by human annotators to evaluate retrieval algorithms. The collected dataset shows that our method agrees well with the human perception of image similarity than other competitive baselines.
A Bi-directional Transformer for Musical Chord Recognition
Jul 05, 2019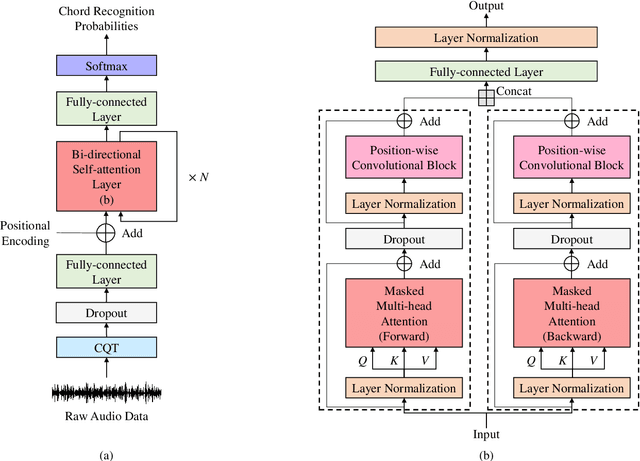
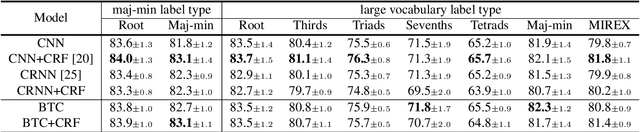
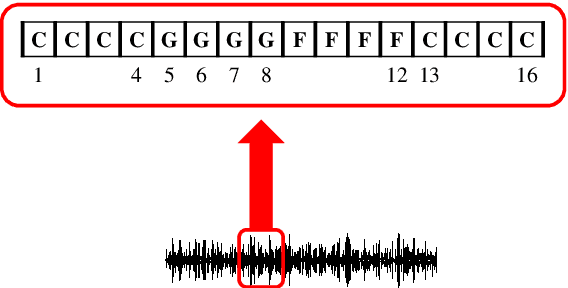

Chord recognition is an important task since chords are highly abstract and descriptive features of music. For effective chord recognition, it is essential to utilize relevant context in audio sequence. While various machine learning models such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been employed for the task, most of them have limitations in capturing long-term dependency or require training of an additional model. In this work, we utilize a self-attention mechanism for chord recognition to focus on certain regions of chords. Training of the proposed bi-directional Transformer for chord recognition (BTC) consists of a single phase while showing competitive performance. Through an attention map analysis, we have visualized how attention was performed. It turns out that the model was able to divide segments of chords by utilizing adaptive receptive field of the attention mechanism. Furthermore, it was observed that the model was able to effectively capture long-term dependencies, making use of essential information regardless of distance.