 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolution for SMART-101 Challenge of CVPR Multi-modal Algorithmic Reasoning Task 2024
Jun 10, 2024



In this paper, the solution of HYU MLLAB KT Team to the Multimodal Algorithmic Reasoning Task: SMART-101 CVPR 2024 Challenge is presented. Beyond conventional visual question-answering problems, the SMART-101 challenge aims to achieve human-level multimodal understanding by tackling complex visio-linguistic puzzles designed for children in the 6-8 age group. To solve this problem, we suggest two main ideas. First, to utilize the reasoning ability of a large-scale language model (LLM), the given visual cues (images) are grounded in the text modality. For this purpose, we generate highly detailed text captions that describe the context of the image and use these captions as input for the LLM. Second, due to the nature of puzzle images, which often contain various geometric visual patterns, we utilize an object detection algorithm to ensure these patterns are not overlooked in the captioning process. We employed the SAM algorithm, which can detect various-size objects, to capture the visual features of these geometric patterns and used this information as input for the LLM. Under the puzzle split configuration, we achieved an option selection accuracy Oacc of 29.5 on the test set and a weighted option selection accuracy (WOSA) of 27.1 on the challenge set.
Bridging the Domain Gap by Clustering-based Image-Text Graph Matching
Oct 04, 2023Learning domain-invariant representations is important to train a model that can generalize well to unseen target task domains. Text descriptions inherently contain semantic structures of concepts and such auxiliary semantic cues can be used as effective pivot embedding for domain generalization problems. Here, we use multimodal graph representations, fusing images and text, to get domain-invariant pivot embeddings by considering the inherent semantic structure between local images and text descriptors. Specifically, we aim to learn domain-invariant features by (i) representing the image and text descriptions with graphs, and by (ii) clustering and matching the graph-based image node features into textual graphs simultaneously. We experiment with large-scale public datasets, such as CUB-DG and DomainBed, and our model achieves matched or better state-of-the-art performance on these datasets. Our code will be publicly available upon publication.
Dense but Efficient VideoQA for Intricate Compositional Reasoning
Oct 19, 2022
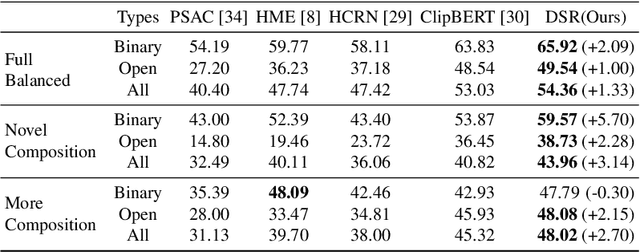
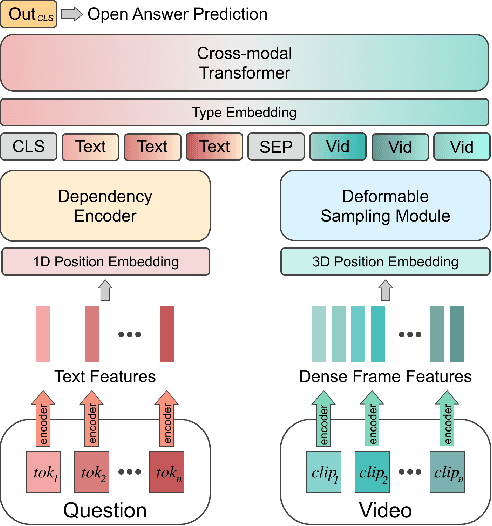
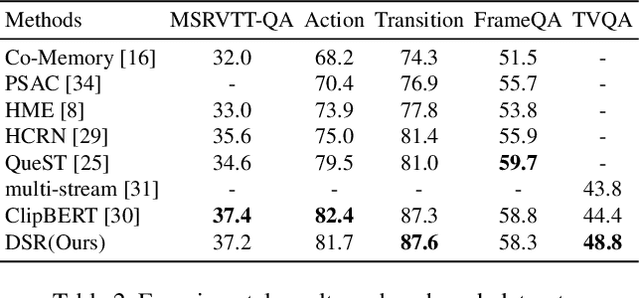
It is well known that most of the conventional video question answering (VideoQA) datasets consist of easy questions requiring simple reasoning processes. However, long videos inevitably contain complex and compositional semantic structures along with the spatio-temporal axis, which requires a model to understand the compositional structures inherent in the videos. In this paper, we suggest a new compositional VideoQA method based on transformer architecture with a deformable attention mechanism to address the complex VideoQA tasks. The deformable attentions are introduced to sample a subset of informative visual features from the dense visual feature map to cover a temporally long range of frames efficiently. Furthermore, the dependency structure within the complex question sentences is also combined with the language embeddings to readily understand the relations among question words. Extensive experiments and ablation studies show that the suggested dense but efficient model outperforms other baselines.
Selective Token Generation for Few-shot Natural Language Generation
Sep 17, 2022
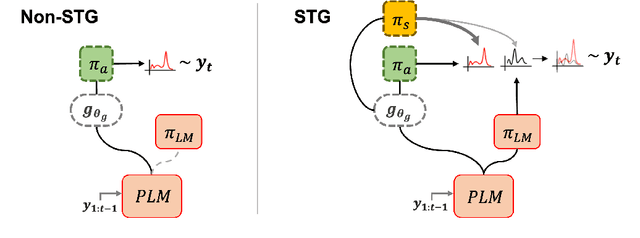
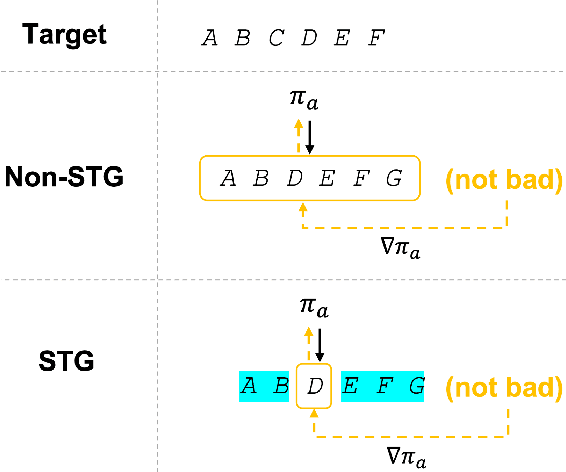
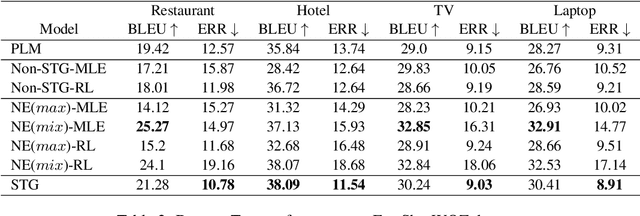
Natural language modeling with limited training data is a challenging problem, and many algorithms make use of large-scale pretrained language models (PLMs) for this due to its great generalization ability. Among them, additive learning that incorporates a task-specific adapter on top of the fixed large-scale PLM has been popularly used in the few-shot setting. However, this added adapter is still easy to disregard the knowledge of the PLM especially for few-shot natural language generation (NLG) since an entire sequence is usually generated by only the newly trained adapter. Therefore, in this work, we develop a novel additive learning algorithm based on reinforcement learning (RL) that selectively outputs language tokens between the task-general PLM and the task-specific adapter during both training and inference. This output token selection over the two generators allows the adapter to take into account solely the task-relevant parts in sequence generation, and therefore makes it more robust to overfitting as well as more stable in RL training. In addition, to obtain the complementary adapter from the PLM for each few-shot task, we exploit a separate selecting module that is also simultaneously trained using RL. Experimental results on various few-shot NLG tasks including question answering, data-to-text generation and text summarization demonstrate that the proposed selective token generation significantly outperforms the previous additive learning algorithms based on the PLMs.
Hypergraph Transformer: Weakly-supervised Multi-hop Reasoning for Knowledge-based Visual Question Answering
Apr 22, 2022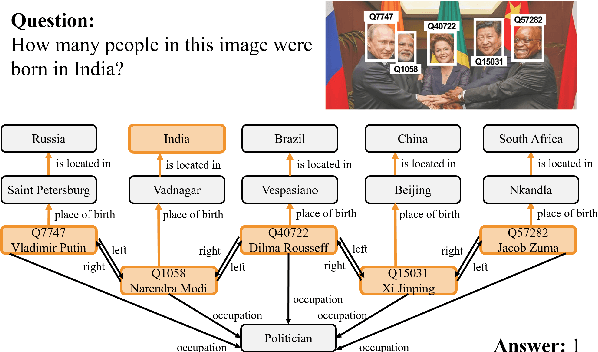
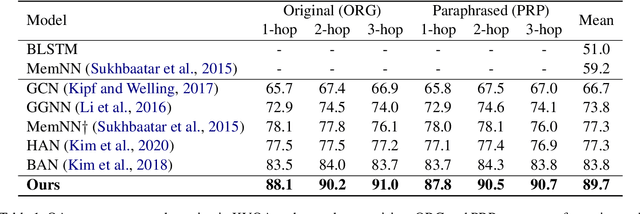
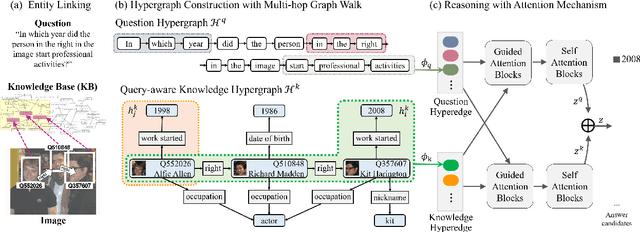
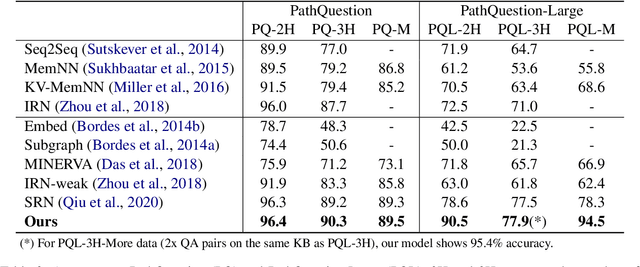
Knowledge-based visual question answering (QA) aims to answer a question which requires visually-grounded external knowledge beyond image content itself. Answering complex questions that require multi-hop reasoning under weak supervision is considered as a challenging problem since i) no supervision is given to the reasoning process and ii) high-order semantics of multi-hop knowledge facts need to be captured. In this paper, we introduce a concept of hypergraph to encode high-level semantics of a question and a knowledge base, and to learn high-order associations between them. The proposed model, Hypergraph Transformer, constructs a question hypergraph and a query-aware knowledge hypergraph, and infers an answer by encoding inter-associations between two hypergraphs and intra-associations in both hypergraph itself. Extensive experiments on two knowledge-based visual QA and two knowledge-based textual QA demonstrate the effectiveness of our method, especially for multi-hop reasoning problem. Our source code is available at https://github.com/yujungheo/kbvqa-public.
Video-Text Representation Learning via Differentiable Weak Temporal Alignment
Mar 31, 2022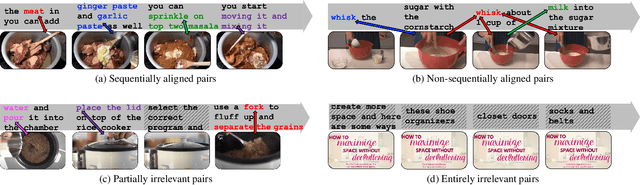
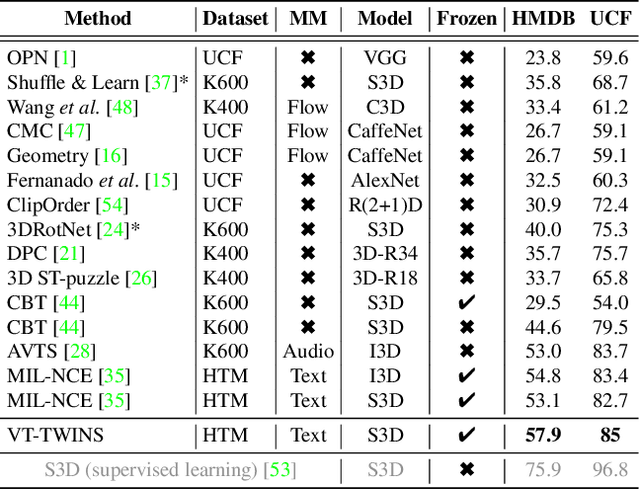
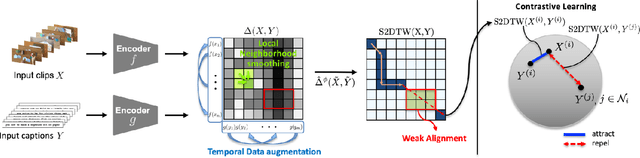
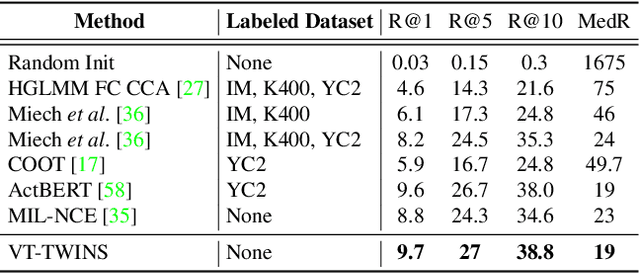
Learning generic joint representations for video and text by a supervised method requires a prohibitively substantial amount of manually annotated video datasets. As a practical alternative, a large-scale but uncurated and narrated video dataset, HowTo100M, has recently been introduced. But it is still challenging to learn joint embeddings of video and text in a self-supervised manner, due to its ambiguity and non-sequential alignment. In this paper, we propose a novel multi-modal self-supervised framework Video-Text Temporally Weak Alignment-based Contrastive Learning (VT-TWINS) to capture significant information from noisy and weakly correlated data using a variant of Dynamic Time Warping (DTW). We observe that the standard DTW inherently cannot handle weakly correlated data and only considers the globally optimal alignment path. To address these problems, we develop a differentiable DTW which also reflects local information with weak temporal alignment. Moreover, our proposed model applies a contrastive learning scheme to learn feature representations on weakly correlated data. Our extensive experiments demonstrate that VT-TWINS attains significant improvements in multi-modal representation learning and outperforms various challenging downstream tasks. Code is available at https://github.com/mlvlab/VT-TWINS.
MSTR: Multi-Scale Transformer for End-to-End Human-Object Interaction Detection
Mar 28, 2022
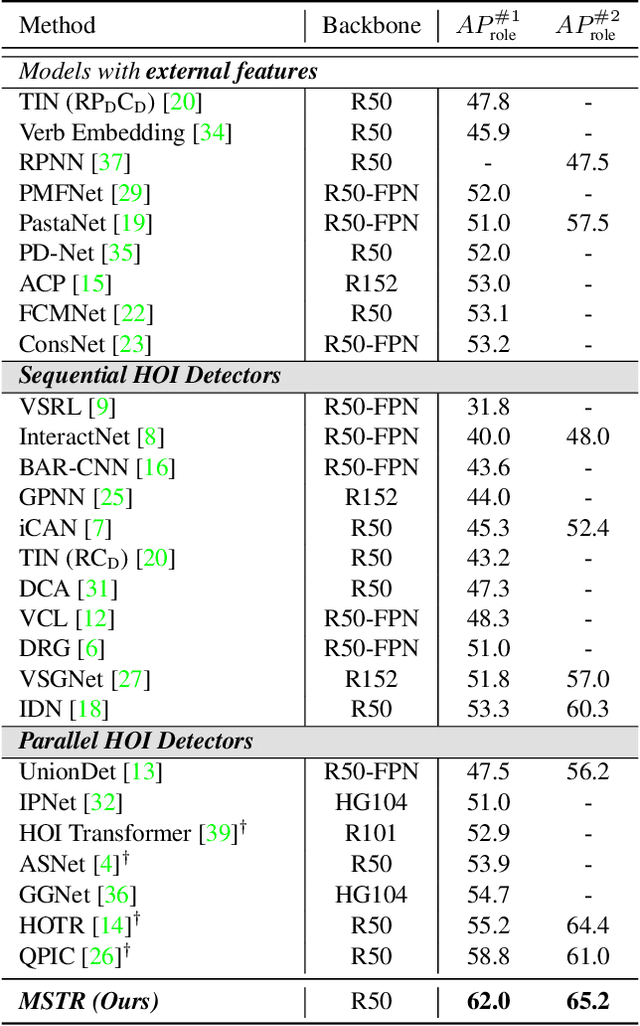
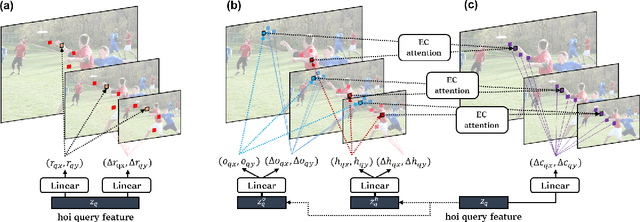
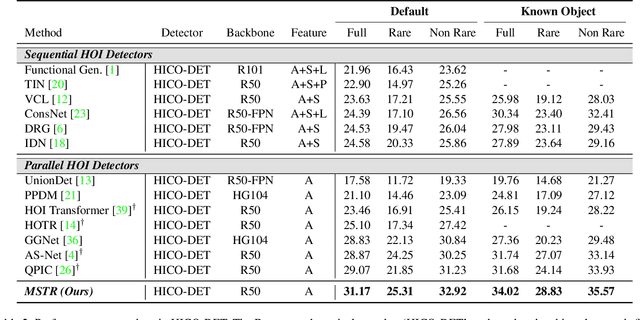
Human-Object Interaction (HOI) detection is the task of identifying a set of <human, object, interaction> triplets from an image. Recent work proposed transformer encoder-decoder architectures that successfully eliminated the need for many hand-designed components in HOI detection through end-to-end training. However, they are limited to single-scale feature resolution, providing suboptimal performance in scenes containing humans, objects and their interactions with vastly different scales and distances. To tackle this problem, we propose a Multi-Scale TRansformer (MSTR) for HOI detection powered by two novel HOI-aware deformable attention modules called Dual-Entity attention and Entity-conditioned Context attention. While existing deformable attention comes at a huge cost in HOI detection performance, our proposed attention modules of MSTR learn to effectively attend to sampling points that are essential to identify interactions. In experiments, we achieve the new state-of-the-art performance on two HOI detection benchmarks.
Boundary-aware Self-supervised Learning for Video Scene Segmentation
Jan 14, 2022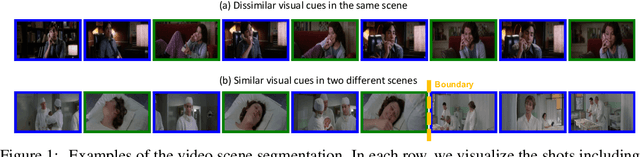
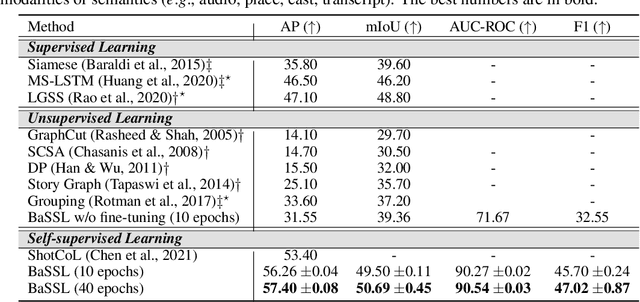
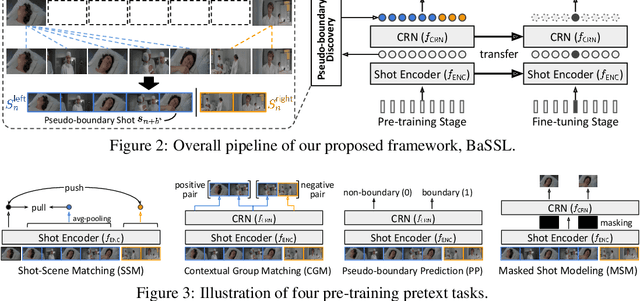
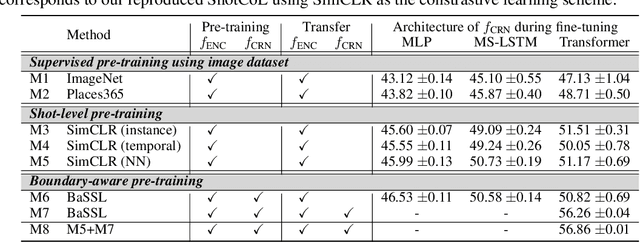
Self-supervised learning has drawn attention through its effectiveness in learning in-domain representations with no ground-truth annotations; in particular, it is shown that properly designed pretext tasks (e.g., contrastive prediction task) bring significant performance gains for downstream tasks (e.g., classification task). Inspired from this, we tackle video scene segmentation, which is a task of temporally localizing scene boundaries in a video, with a self-supervised learning framework where we mainly focus on designing effective pretext tasks. In our framework, we discover a pseudo-boundary from a sequence of shots by splitting it into two continuous, non-overlapping sub-sequences and leverage the pseudo-boundary to facilitate the pre-training. Based on this, we introduce three novel boundary-aware pretext tasks: 1) Shot-Scene Matching (SSM), 2) Contextual Group Matching (CGM) and 3) Pseudo-boundary Prediction (PP); SSM and CGM guide the model to maximize intra-scene similarity and inter-scene discrimination while PP encourages the model to identify transitional moments. Through comprehensive analysis, we empirically show that pre-training and transferring contextual representation are both critical to improving the video scene segmentation performance. Lastly, we achieve the new state-of-the-art on the MovieNet-SSeg benchmark. The code is available at https://github.com/kakaobrain/bassl.
Winning the ICCV'2021 VALUE Challenge: Task-aware Ensemble and Transfer Learning with Visual Concepts
Oct 13, 2021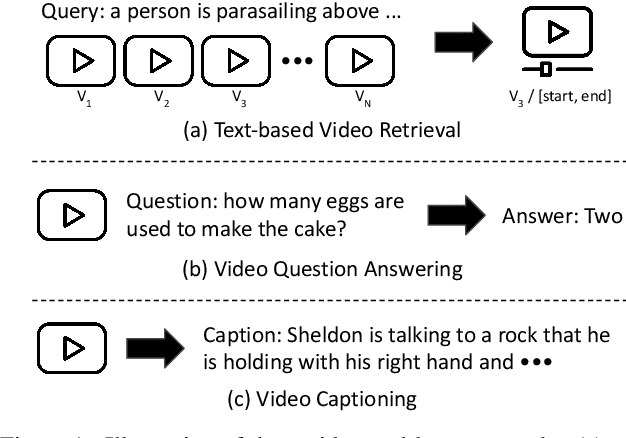

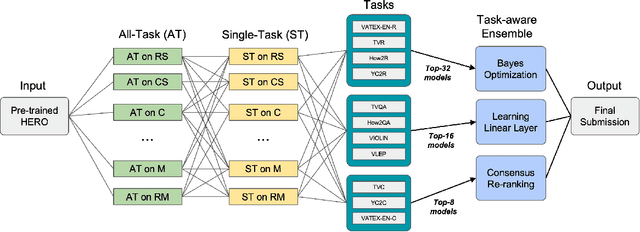
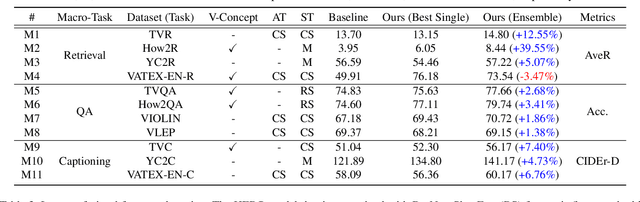
The VALUE (Video-And-Language Understanding Evaluation) benchmark is newly introduced to evaluate and analyze multi-modal representation learning algorithms on three video-and-language tasks: Retrieval, QA, and Captioning. The main objective of the VALUE challenge is to train a task-agnostic model that is simultaneously applicable for various tasks with different characteristics. This technical report describes our winning strategies for the VALUE challenge: 1) single model optimization, 2) transfer learning with visual concepts, and 3) task-aware ensemble. The first and third strategies are designed to address heterogeneous characteristics of each task, and the second one is to leverage rich and fine-grained visual information. We provide a detailed and comprehensive analysis with extensive experimental results. Based on our approach, we ranked first place on the VALUE and QA phases for the competition.
HOTR: End-to-End Human-Object Interaction Detection with Transformers
Apr 28, 2021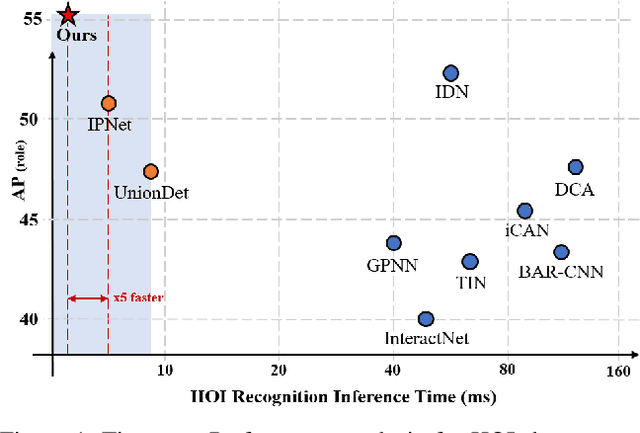
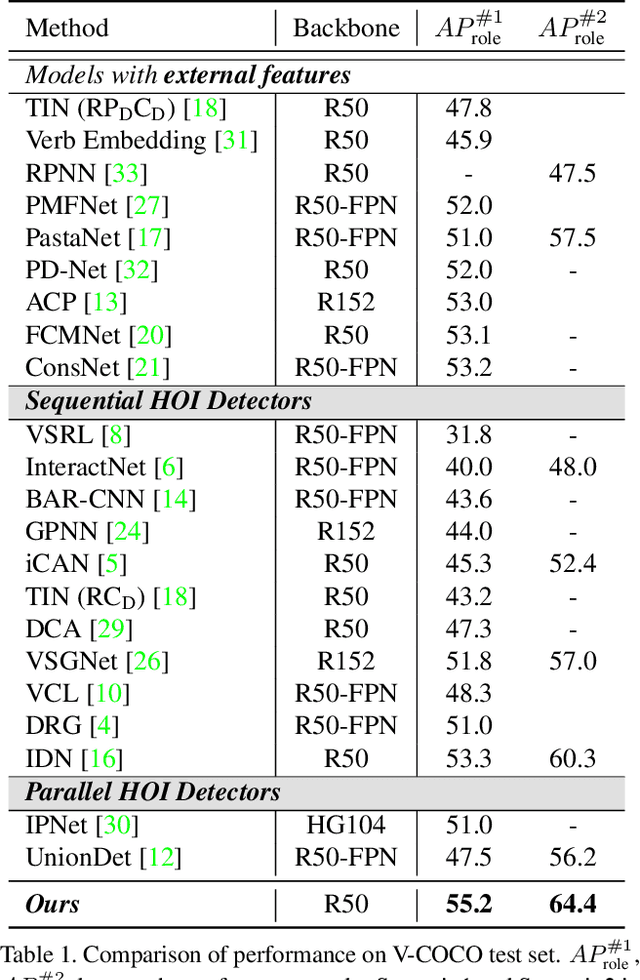
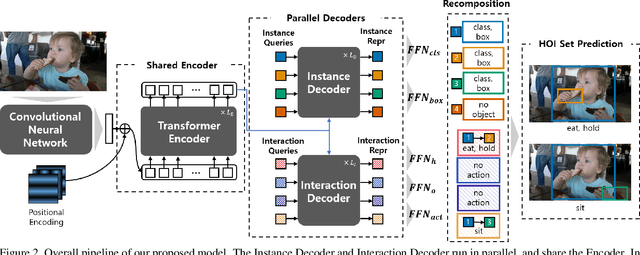
Human-Object Interaction (HOI) detection is a task of identifying "a set of interactions" in an image, which involves the i) localization of the subject (i.e., humans) and target (i.e., objects) of interaction, and ii) the classification of the interaction labels. Most existing methods have indirectly addressed this task by detecting human and object instances and individually inferring every pair of the detected instances. In this paper, we present a novel framework, referred to by HOTR, which directly predicts a set of <human, object, interaction> triplets from an image based on a transformer encoder-decoder architecture. Through the set prediction, our method effectively exploits the inherent semantic relationships in an image and does not require time-consuming post-processing which is the main bottleneck of existing methods. Our proposed algorithm achieves the state-of-the-art performance in two HOI detection benchmarks with an inference time under 1 ms after object detection.