 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticControl: A Training-Free Approach for Handling Loosely Aligned Visual Conditions in ControlNet
Sep 26, 2025ControlNet has enabled detailed spatial control in text-to-image diffusion models by incorporating additional visual conditions such as depth or edge maps. However, its effectiveness heavily depends on the availability of visual conditions that are precisely aligned with the generation goal specified by text prompt-a requirement that often fails in practice, especially for uncommon or imaginative scenes. For example, generating an image of a cat cooking in a specific pose may be infeasible due to the lack of suitable visual conditions. In contrast, structurally similar cues can often be found in more common settings-for instance, poses of humans cooking are widely available and can serve as rough visual guides. Unfortunately, existing ControlNet models struggle to use such loosely aligned visual conditions, often resulting in low text fidelity or visual artifacts. To address this limitation, we propose SemanticControl, a training-free method for effectively leveraging misaligned but semantically relevant visual conditions. Our approach adaptively suppresses the influence of the visual condition where it conflicts with the prompt, while strengthening guidance from the text. The key idea is to first run an auxiliary denoising process using a surrogate prompt aligned with the visual condition (e.g., "a human playing guitar" for a human pose condition) to extract informative attention masks, and then utilize these masks during the denoising of the actual target prompt (e.g., cat playing guitar). Experimental results demonstrate that our method improves performance under loosely aligned conditions across various conditions, including depth maps, edge maps, and human skeletons, outperforming existing baselines. Our code is available at https://mung3477.github.io/semantic-control.
DiffExp: Efficient Exploration in Reward Fine-tuning for Text-to-Image Diffusion Models
Feb 19, 2025



Fine-tuning text-to-image diffusion models to maximize rewards has proven effective for enhancing model performance. However, reward fine-tuning methods often suffer from slow convergence due to online sample generation. Therefore, obtaining diverse samples with strong reward signals is crucial for improving sample efficiency and overall performance. In this work, we introduce DiffExp, a simple yet effective exploration strategy for reward fine-tuning of text-to-image models. Our approach employs two key strategies: (a) dynamically adjusting the scale of classifier-free guidance to enhance sample diversity, and (b) randomly weighting phrases of the text prompt to exploit high-quality reward signals. We demonstrate that these strategies significantly enhance exploration during online sample generation, improving the sample efficiency of recent reward fine-tuning methods, such as DDPO and AlignProp.
VersaPRM: Multi-Domain Process Reward Model via Synthetic Reasoning Data
Feb 10, 2025



Process Reward Models (PRMs) have proven effective at enhancing mathematical reasoning for Large Language Models (LLMs) by leveraging increased inference-time computation. However, they are predominantly trained on mathematical data and their generalizability to non-mathematical domains has not been rigorously studied. In response, this work first shows that current PRMs have poor performance in other domains. To address this limitation, we introduce VersaPRM, a multi-domain PRM trained on synthetic reasoning data generated using our novel data generation and annotation method. VersaPRM achieves consistent performance gains across diverse domains. For instance, in the MMLU-Pro category of Law, VersaPRM via weighted majority voting, achieves a 7.9% performance gain over the majority voting baseline -- surpassing Qwen2.5-Math-PRM's gain of 1.3%. We further contribute to the community by open-sourcing all data, code and models for VersaPRM.
ENTP: Encoder-only Next Token Prediction
Oct 02, 2024



Next-token prediction models have predominantly relied on decoder-only Transformers with causal attention, driven by the common belief that causal attention is essential to prevent "cheating" by masking future tokens. We challenge this widely accepted notion and argue that this design choice is about efficiency rather than necessity. While decoder-only Transformers are still a good choice for practical reasons, they are not the only viable option. In this work, we introduce Encoder-only Next Token Prediction (ENTP). We explore the differences between ENTP and decoder-only Transformers in expressive power and complexity, highlighting potential advantages of ENTP. We introduce the Triplet-Counting task and show, both theoretically and experimentally, that while ENTP can perform this task easily, a decoder-only Transformer cannot. Finally, we empirically demonstrate ENTP's superior performance across various realistic tasks, such as length generalization and in-context learning.
InstructBooth: Instruction-following Personalized Text-to-Image Generation
Dec 04, 2023


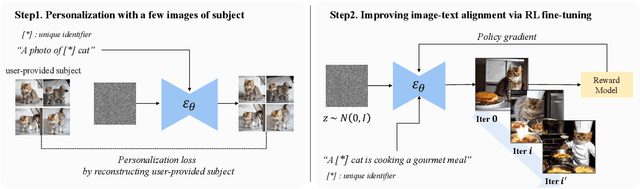
Personalizing text-to-image models using a limited set of images for a specific object has been explored in subject-specific image generation. However, existing methods often encounter challenges in aligning with text prompts due to overfitting to the limited training images. In this work, we introduce InstructBooth, a novel method designed to enhance image-text alignment in personalized text-to-image models. Our approach first personalizes text-to-image models with a small number of subject-specific images using a unique identifier. After personalization, we fine-tune personalized text-to-image models using reinforcement learning to maximize a reward that quantifies image-text alignment. Additionally, we propose complementary techniques to increase the synergy between these two processes. Our method demonstrates superior image-text alignment compared to baselines while maintaining personalization ability. In human evaluations, InstructBooth outperforms DreamBooth when considering all comprehensive factors.
Bridging the Domain Gap by Clustering-based Image-Text Graph Matching
Oct 04, 2023Learning domain-invariant representations is important to train a model that can generalize well to unseen target task domains. Text descriptions inherently contain semantic structures of concepts and such auxiliary semantic cues can be used as effective pivot embedding for domain generalization problems. Here, we use multimodal graph representations, fusing images and text, to get domain-invariant pivot embeddings by considering the inherent semantic structure between local images and text descriptors. Specifically, we aim to learn domain-invariant features by (i) representing the image and text descriptions with graphs, and by (ii) clustering and matching the graph-based image node features into textual graphs simultaneously. We experiment with large-scale public datasets, such as CUB-DG and DomainBed, and our model achieves matched or better state-of-the-art performance on these datasets. Our code will be publicly available upon publication.