 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTABED: Test-Time Adaptive Ensemble Drafting for Robust Speculative Decoding in LVLMs
Jan 28, 2026Speculative decoding (SD) has proven effective for accelerating LLM inference by quickly generating draft tokens and verifying them in parallel. However, SD remains largely unexplored for Large Vision-Language Models (LVLMs), which extend LLMs to process both image and text prompts. To address this gap, we benchmark existing inference methods with small draft models on 11 datasets across diverse input scenarios and observe scenario-specific performance fluctuations. Motivated by these findings, we propose Test-time Adaptive Batched Ensemble Drafting (TABED), which dynamically ensembles multiple drafts obtained via batch inference by leveraging deviations from past ground truths available in the SD setting. The dynamic ensemble method achieves an average robust walltime speedup of 1.74x over autoregressive decoding and a 5% improvement over single drafting methods, while remaining training-free and keeping ensembling costs negligible through parameter sharing. With its plug-and-play compatibility, we further enhance TABED by integrating advanced verification and alternative drafting methods. Code and custom-trained models are available at https://github.com/furiosa-ai/TABED.
ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs
Oct 06, 2025While most autoregressive LLMs are constrained to one-by-one decoding, diffusion LLMs (dLLMs) have attracted growing interest for their potential to dramatically accelerate inference through parallel decoding. Despite this promise, the conditional independence assumption in dLLMs causes parallel decoding to ignore token dependencies, inevitably degrading generation quality when these dependencies are strong. However, existing works largely overlook these inherent challenges, and evaluations on standard benchmarks (e.g., math and coding) are not sufficient to capture the quality degradation caused by parallel decoding. To address this gap, we first provide an information-theoretic analysis of parallel decoding. We then conduct case studies on analytically tractable synthetic list operations from both data distribution and decoding strategy perspectives, offering quantitative insights that highlight the fundamental limitations of parallel decoding. Building on these insights, we propose ParallelBench, the first benchmark specifically designed for dLLMs, featuring realistic tasks that are trivial for humans and autoregressive LLMs yet exceptionally challenging for dLLMs under parallel decoding. Using ParallelBench, we systematically analyze both dLLMs and autoregressive LLMs, revealing that: (i) dLLMs under parallel decoding can suffer dramatic quality degradation in real-world scenarios, and (ii) current parallel decoding strategies struggle to adapt their degree of parallelism based on task difficulty, thus failing to achieve meaningful speedup without compromising quality. Our findings underscore the pressing need for innovative decoding methods that can overcome the current speed-quality trade-off. We release our benchmark to help accelerate the development of truly efficient dLLMs.
XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization
Aug 14, 2025Although LLM inference has emerged as a critical workload for many downstream applications, efficiently inferring LLMs is challenging due to the substantial memory footprint and bandwidth requirements. In parallel, compute capabilities have steadily outpaced both memory capacity and bandwidth over the last few decades, a trend that remains evident in modern GPU hardware and exacerbates the challenge of LLM inference. As such, new algorithms are emerging that trade increased computation for reduced memory operations. To that end, we present XQuant, which takes advantage of this trend, enabling an order-of-magnitude reduction in memory consumption through low-bit quantization with substantial accuracy benefits relative to state-of-the-art KV cache quantization methods. We accomplish this by quantizing and caching the layer input activations X, instead of using standard KV caching, and then rematerializing the Keys and Values on-the-fly during inference. This results in an immediate 2$\times$ memory savings compared to KV caching. By applying XQuant, we achieve up to $\sim 7.7\times$ memory savings with $<0.1$ perplexity degradation compared to the FP16 baseline. Furthermore, our approach leverages the fact that X values are similar across layers. Building on this observation, we introduce XQuant-CL, which exploits the cross-layer similarity in the X embeddings for extreme compression. Across different models, XQuant-CL attains up to 10$\times$ memory savings relative to the FP16 baseline with only 0.01 perplexity degradation, and 12.5$\times$ memory savings with only $0.1$ perplexity degradation. XQuant exploits the rapidly increasing compute capabilities of hardware platforms to eliminate the memory bottleneck, while surpassing state-of-the-art KV cache quantization methods and achieving near-FP16 accuracy across a wide range of models.
UNCAGE: Contrastive Attention Guidance for Masked Generative Transformers in Text-to-Image Generation
Aug 07, 2025Text-to-image (T2I) generation has been actively studied using Diffusion Models and Autoregressive Models. Recently, Masked Generative Transformers have gained attention as an alternative to Autoregressive Models to overcome the inherent limitations of causal attention and autoregressive decoding through bidirectional attention and parallel decoding, enabling efficient and high-quality image generation. However, compositional T2I generation remains challenging, as even state-of-the-art Diffusion Models often fail to accurately bind attributes and achieve proper text-image alignment. While Diffusion Models have been extensively studied for this issue, Masked Generative Transformers exhibit similar limitations but have not been explored in this context. To address this, we propose Unmasking with Contrastive Attention Guidance (UNCAGE), a novel training-free method that improves compositional fidelity by leveraging attention maps to prioritize the unmasking of tokens that clearly represent individual objects. UNCAGE consistently improves performance in both quantitative and qualitative evaluations across multiple benchmarks and metrics, with negligible inference overhead. Our code is available at https://github.com/furiosa-ai/uncage.
Draft-based Approximate Inference for LLMs
Jun 10, 2025Optimizing inference for long-context Large Language Models (LLMs) is increasingly important due to the quadratic compute and linear memory complexity of Transformers. Existing approximation methods, such as key-value (KV) cache dropping, sparse attention, and prompt compression, typically rely on rough predictions of token or KV pair importance. We propose a novel framework for approximate LLM inference that leverages small draft models to more accurately predict the importance of tokens and KV pairs. Specifically, we introduce two instantiations of our proposed framework: (i) SpecKV, which leverages a draft output to accurately assess the importance of each KV pair for more effective KV cache dropping, and (ii) SpecPC, which uses the draft model's attention activations to identify and discard unimportant prompt tokens. To the best of our knowledge, this is the first work to use draft models for approximate LLM inference acceleration, extending their utility beyond traditional lossless speculative decoding. We motivate our methods with theoretical and empirical analyses, and show a strong correlation between the attention patterns of draft and target models. Extensive experiments on long-context benchmarks show that our methods consistently achieve higher accuracy than existing baselines, while preserving the same improvements in memory usage, latency, and throughput. Our code is available at https://github.com/furiosa-ai/draft-based-approx-llm.
TabFlex: Scaling Tabular Learning to Millions with Linear Attention
Jun 05, 2025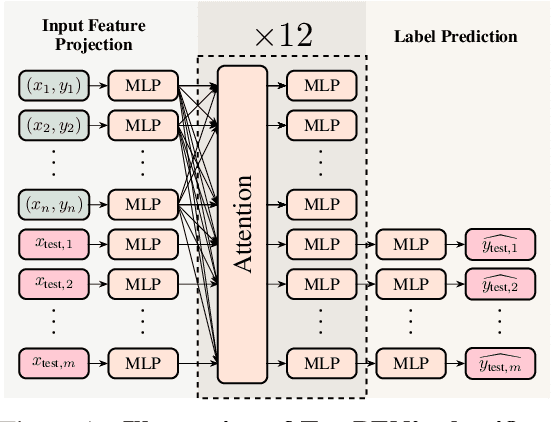
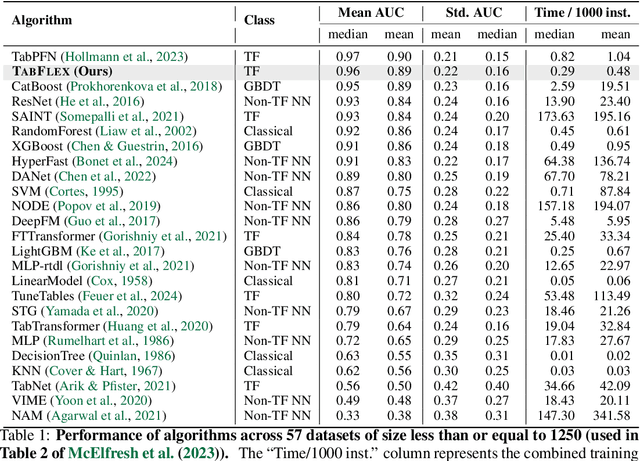
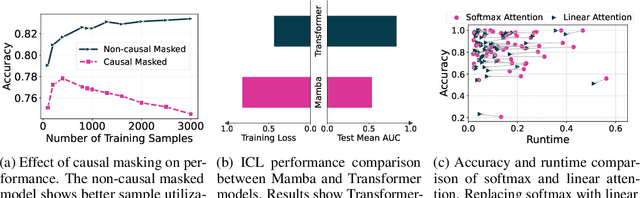
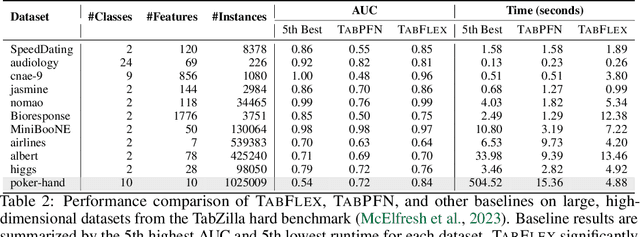
Leveraging the in-context learning (ICL) capability of Large Language Models (LLMs) for tabular classification has gained significant attention for its training-free adaptability across diverse datasets. Recent advancements, like TabPFN, excel in small-scale tabular datasets but struggle to scale for large and complex datasets. Our work enhances the efficiency and scalability of TabPFN for larger datasets by incorporating linear attention mechanisms as a scalable alternative to complexity-quadratic self-attention. Our model, TabFlex, efficiently handles tabular datasets with thousands of features and hundreds of classes, scaling seamlessly to millions of samples. For instance, TabFlex processes the poker-hand dataset with over a million samples in just 5 seconds. Our extensive evaluations demonstrate that TabFlex can achieve over a 2x speedup compared to TabPFN and a 1.5x speedup over XGBoost, outperforming 25 tested baselines in terms of efficiency across a diverse range of datasets. Furthermore, TabFlex remains highly effective on large-scale datasets, delivering strong performance with significantly reduced computational costs, especially when combined with data-efficient techniques such as dimensionality reduction and data sampling.
State-offset Tuning: State-based Parameter-Efficient Fine-Tuning for State Space Models
Mar 05, 2025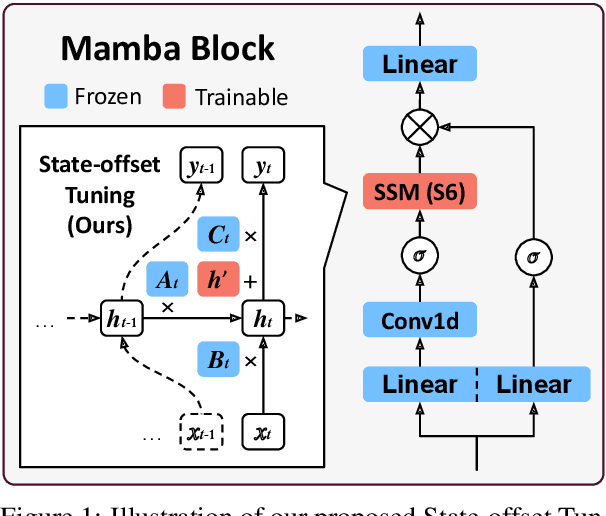


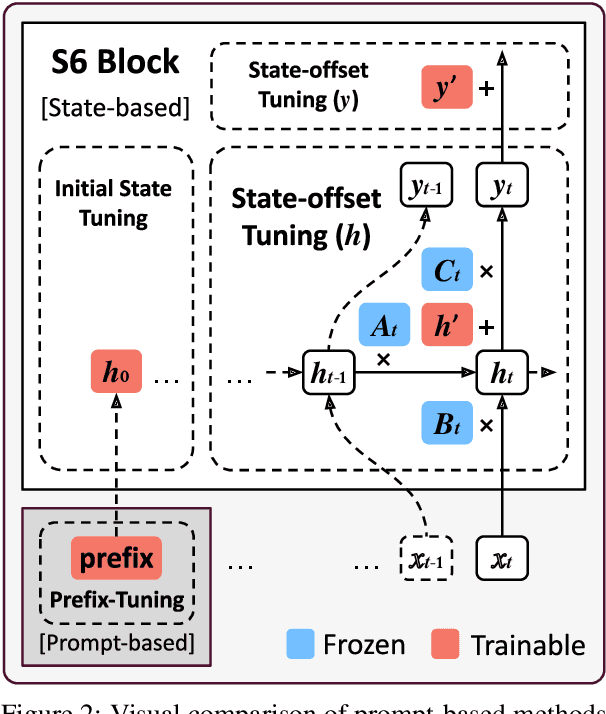
State Space Models (SSMs) have emerged as efficient alternatives to Transformers, mitigating their quadratic computational cost. However, the application of Parameter-Efficient Fine-Tuning (PEFT) methods to SSMs remains largely unexplored. In particular, prompt-based methods like Prompt Tuning and Prefix-Tuning, which are widely used in Transformers, do not perform well on SSMs. To address this, we propose state-based methods as a superior alternative to prompt-based methods. This new family of methods naturally stems from the architectural characteristics of SSMs. State-based methods adjust state-related features directly instead of depending on external prompts. Furthermore, we introduce a novel state-based PEFT method: State-offset Tuning. At every timestep, our method directly affects the state at the current step, leading to more effective adaptation. Through extensive experiments across diverse datasets, we demonstrate the effectiveness of our method. Code is available at https://github.com/furiosa-ai/ssm-state-tuning.
VersaPRM: Multi-Domain Process Reward Model via Synthetic Reasoning Data
Feb 10, 2025



Process Reward Models (PRMs) have proven effective at enhancing mathematical reasoning for Large Language Models (LLMs) by leveraging increased inference-time computation. However, they are predominantly trained on mathematical data and their generalizability to non-mathematical domains has not been rigorously studied. In response, this work first shows that current PRMs have poor performance in other domains. To address this limitation, we introduce VersaPRM, a multi-domain PRM trained on synthetic reasoning data generated using our novel data generation and annotation method. VersaPRM achieves consistent performance gains across diverse domains. For instance, in the MMLU-Pro category of Law, VersaPRM via weighted majority voting, achieves a 7.9% performance gain over the majority voting baseline -- surpassing Qwen2.5-Math-PRM's gain of 1.3%. We further contribute to the community by open-sourcing all data, code and models for VersaPRM.
Parameter-Efficient Fine-Tuning of State Space Models
Oct 11, 2024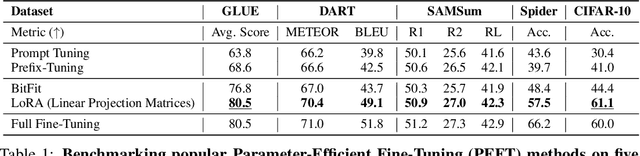
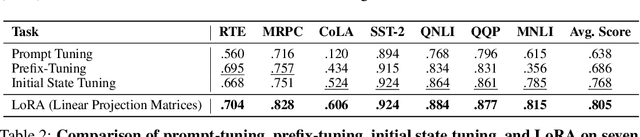
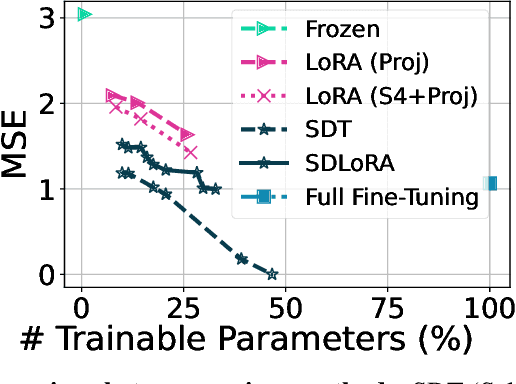
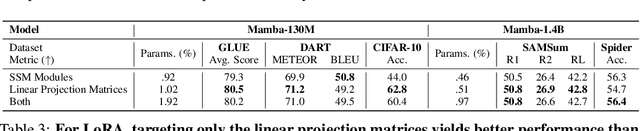
Deep State Space Models (SSMs), such as Mamba (Gu & Dao, 2024), have emerged as powerful tools for language modeling, offering high performance with efficient inference and linear scaling in sequence length. However, the application of parameter-efficient fine-tuning (PEFT) methods to SSM-based models remains largely unexplored. This paper aims to systematically study two key questions: (i) How do existing PEFT methods perform on SSM-based models? (ii) Which modules are most effective for fine-tuning? We conduct an empirical benchmark of four basic PEFT methods on SSM-based models. Our findings reveal that prompt-based methods (e.g., prefix-tuning) are no longer effective, an empirical result further supported by theoretical analysis. In contrast, LoRA remains effective for SSM-based models. We further investigate the optimal application of LoRA within these models, demonstrating both theoretically and experimentally that applying LoRA to linear projection matrices without modifying SSM modules yields the best results, as LoRA is not effective at tuning SSM modules. To further improve performance, we introduce LoRA with Selective Dimension tuning (SDLoRA), which selectively updates certain channels and states on SSM modules while applying LoRA to linear projection matrices. Extensive experimental results show that this approach outperforms standard LoRA.
Eta Inversion: Designing an Optimal Eta Function for Diffusion-based Real Image Editing
Mar 14, 2024Diffusion models have achieved remarkable success in the domain of text-guided image generation and, more recently, in text-guided image editing. A commonly adopted strategy for editing real images involves inverting the diffusion process to obtain a noisy representation of the original image, which is then denoised to achieve the desired edits. However, current methods for diffusion inversion often struggle to produce edits that are both faithful to the specified text prompt and closely resemble the source image. To overcome these limitations, we introduce a novel and adaptable diffusion inversion technique for real image editing, which is grounded in a theoretical analysis of the role of $\eta$ in the DDIM sampling equation for enhanced editability. By designing a universal diffusion inversion method with a time- and region-dependent $\eta$ function, we enable flexible control over the editing extent. Through a comprehensive series of quantitative and qualitative assessments, involving a comparison with a broad array of recent methods, we demonstrate the superiority of our approach. Our method not only sets a new benchmark in the field but also significantly outperforms existing strategies. Our code is available at https://github.com/furiosa-ai/eta-inversion