 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersaPRM: Multi-Domain Process Reward Model via Synthetic Reasoning Data
Feb 10, 2025



Process Reward Models (PRMs) have proven effective at enhancing mathematical reasoning for Large Language Models (LLMs) by leveraging increased inference-time computation. However, they are predominantly trained on mathematical data and their generalizability to non-mathematical domains has not been rigorously studied. In response, this work first shows that current PRMs have poor performance in other domains. To address this limitation, we introduce VersaPRM, a multi-domain PRM trained on synthetic reasoning data generated using our novel data generation and annotation method. VersaPRM achieves consistent performance gains across diverse domains. For instance, in the MMLU-Pro category of Law, VersaPRM via weighted majority voting, achieves a 7.9% performance gain over the majority voting baseline -- surpassing Qwen2.5-Math-PRM's gain of 1.3%. We further contribute to the community by open-sourcing all data, code and models for VersaPRM.
WIPI: A New Web Threat for LLM-Driven Web Agents
Feb 26, 2024



With the fast development of large language models (LLMs), LLM-driven Web Agents (Web Agents for short) have obtained tons of attention due to their superior capability where LLMs serve as the core part of making decisions like the human brain equipped with multiple web tools to actively interact with external deployed websites. As uncountable Web Agents have been released and such LLM systems are experiencing rapid development and drawing closer to widespread deployment in our daily lives, an essential and pressing question arises: "Are these Web Agents secure?". In this paper, we introduce a novel threat, WIPI, that indirectly controls Web Agent to execute malicious instructions embedded in publicly accessible webpages. To launch a successful WIPI works in a black-box environment. This methodology focuses on the form and content of indirect instructions within external webpages, enhancing the efficiency and stealthiness of the attack. To evaluate the effectiveness of the proposed methodology, we conducted extensive experiments using 7 plugin-based ChatGPT Web Agents, 8 Web GPTs, and 3 different open-source Web Agents. The results reveal that our methodology achieves an average attack success rate (ASR) exceeding 90% even in pure black-box scenarios. Moreover, through an ablation study examining various user prefix instructions, we demonstrated that the WIPI exhibits strong robustness, maintaining high performance across diverse prefix instructions.
DiffusionPhase: Motion Diffusion in Frequency Domain
Dec 07, 2023



In this study, we introduce a learning-based method for generating high-quality human motion sequences from text descriptions (e.g., ``A person walks forward"). Existing techniques struggle with motion diversity and smooth transitions in generating arbitrary-length motion sequences, due to limited text-to-motion datasets and the pose representations used that often lack expressiveness or compactness. To address these issues, we propose the first method for text-conditioned human motion generation in the frequency domain of motions. We develop a network encoder that converts the motion space into a compact yet expressive parameterized phase space with high-frequency details encoded, capturing the local periodicity of motions in time and space with high accuracy. We also introduce a conditional diffusion model for predicting periodic motion parameters based on text descriptions and a start pose, efficiently achieving smooth transitions between motion sequences associated with different text descriptions. Experiments demonstrate that our approach outperforms current methods in generating a broader variety of high-quality motions, and synthesizing long sequences with natural transitions.
Leveraging Hierarchical Feature Sharing for Efficient Dataset Condensation
Oct 11, 2023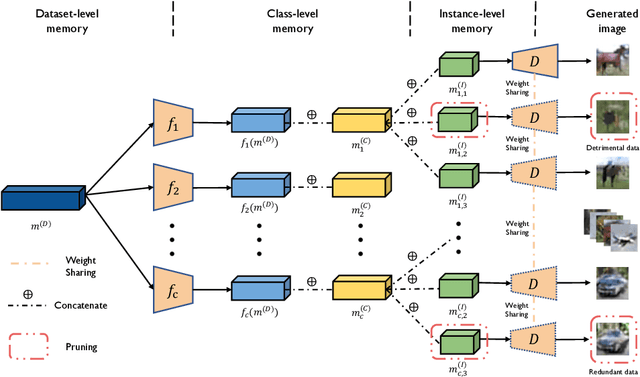
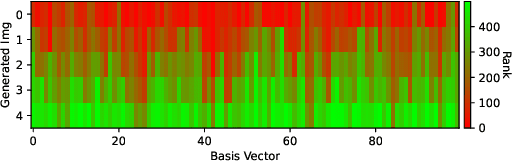
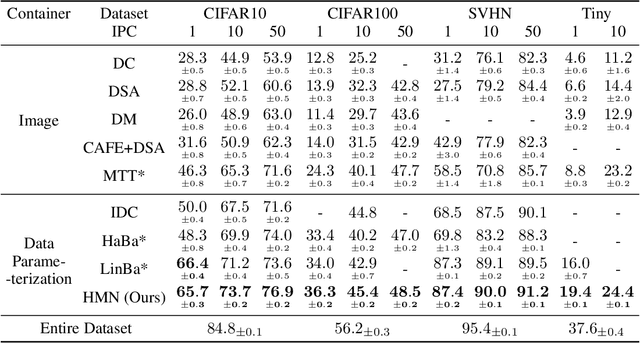
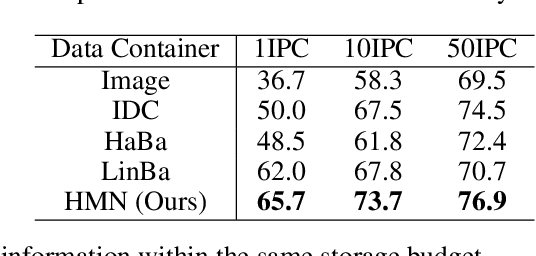
Given a real-world dataset, data condensation (DC) aims to synthesize a significantly smaller dataset that captures the knowledge of this dataset for model training with high performance. Recent works propose to enhance DC with data parameterization, which condenses data into parameterized data containers rather than pixel space. The intuition behind data parameterization is to encode shared features of images to avoid additional storage costs. In this paper, we recognize that images share common features in a hierarchical way due to the inherent hierarchical structure of the classification system, which is overlooked by current data parameterization methods. To better align DC with this hierarchical nature and encourage more efficient information sharing inside data containers, we propose a novel data parameterization architecture, Hierarchical Memory Network (HMN). HMN stores condensed data in a three-tier structure, representing the dataset-level, class-level, and instance-level features. Another helpful property of the hierarchical architecture is that HMN naturally ensures good independence among images despite achieving information sharing. This enables instance-level pruning for HMN to reduce redundant information, thereby further minimizing redundancy and enhancing performance. We evaluate HMN on four public datasets (SVHN, CIFAR10, CIFAR100, and Tiny-ImageNet) and compare HMN with eight DC baselines. The evaluation results show that our proposed method outperforms all baselines, even when trained with a batch-based loss consuming less GPU memory.
Defending against Adversarial Audio via Diffusion Model
Mar 02, 2023Deep learning models have been widely used in commercial acoustic systems in recent years. However, adversarial audio examples can cause abnormal behaviors for those acoustic systems, while being hard for humans to perceive. Various methods, such as transformation-based defenses and adversarial training, have been proposed to protect acoustic systems from adversarial attacks, but they are less effective against adaptive attacks. Furthermore, directly applying the methods from the image domain can lead to suboptimal results because of the unique properties of audio data. In this paper, we propose an adversarial purification-based defense pipeline, AudioPure, for acoustic systems via off-the-shelf diffusion models. Taking advantage of the strong generation ability of diffusion models, AudioPure first adds a small amount of noise to the adversarial audio and then runs the reverse sampling step to purify the noisy audio and recover clean audio. AudioPure is a plug-and-play method that can be directly applied to any pretrained classifier without any fine-tuning or re-training. We conduct extensive experiments on speech command recognition task to evaluate the robustness of AudioPure. Our method is effective against diverse adversarial attacks (e.g. $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm). It outperforms the existing methods under both strong adaptive white-box and black-box attacks bounded by $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm (up to +20\% in robust accuracy). Besides, we also evaluate the certified robustness for perturbations bounded by $\mathcal{L}_2$-norm via randomized smoothing. Our pipeline achieves a higher certified accuracy than baselines.
One-Pixel Shortcut: on the Learning Preference of Deep Neural Networks
May 24, 2022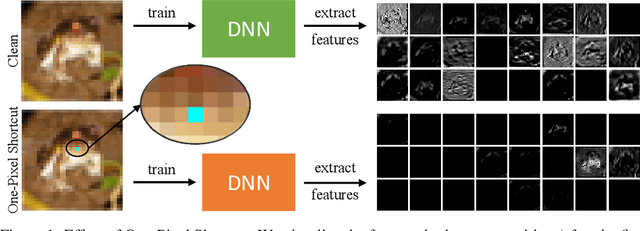
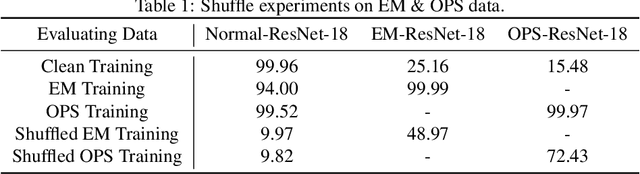
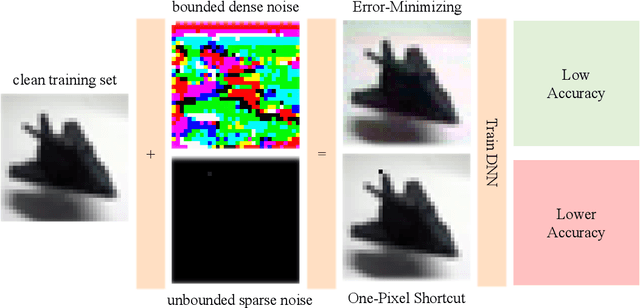
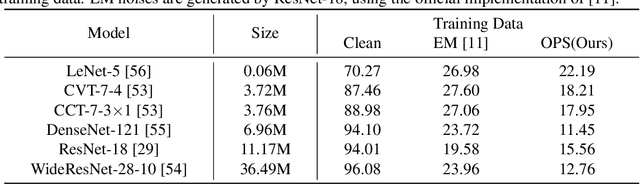
Unlearnable examples (ULEs) aim to protect data from unauthorized usage for training DNNs. Error-minimizing noise, which is injected to clean data, is one of the most successful methods for preventing DNNs from giving correct predictions on incoming new data. Nonetheless, under specific training strategies such as adversarial training, the unlearnability of error-minimizing noise will severely degrade. In addition, the transferability of error-minimizing noise is inherently limited by the mismatch between the generator model and the targeted learner model. In this paper, we investigate the mechanism of unlearnable examples and propose a novel model-free method, named \emph{One-Pixel Shortcut}, which only perturbs a single pixel of each image and makes the dataset unlearnable. Our method needs much less computational cost and obtains stronger transferability and thus can protect data from a wide range of different models. Based on this, we further introduce the first unlearnable dataset called CIFAR-10-S, which is indistinguishable from normal CIFAR-10 by human observers and can serve as a benchmark for different models or training strategies to evaluate their abilities to extract critical features from the disturbance of non-semantic representations. The original error-minimizing ULEs will lose efficiency under adversarial training, where the model can get over 83\% clean test accuracy. Meanwhile, even if adversarial training and strong data augmentation like RandAugment are applied together, the model trained on CIFAR-10-S cannot get over 50\% clean test accuracy.
Weighted Neural Tangent Kernel: A Generalized and Improved Network-Induced Kernel
Mar 22, 2021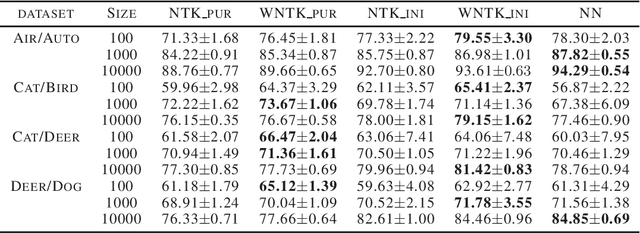
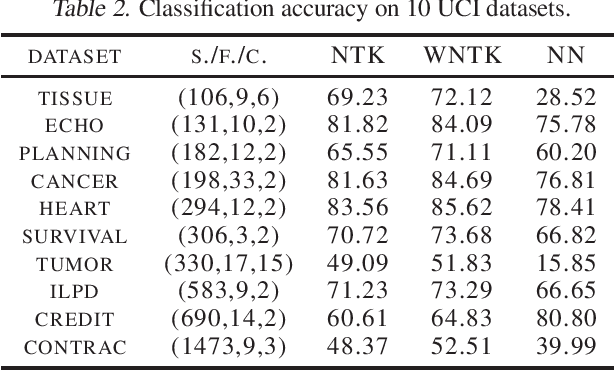
The Neural Tangent Kernel (NTK) has recently attracted intense study, as it describes the evolution of an over-parameterized Neural Network (NN) trained by gradient descent. However, it is now well-known that gradient descent is not always a good optimizer for NNs, which can partially explain the unsatisfactory practical performance of the NTK regression estimator. In this paper, we introduce the Weighted Neural Tangent Kernel (WNTK), a generalized and improved tool, which can capture an over-parameterized NN's training dynamics under different optimizers. Theoretically, in the infinite-width limit, we prove: i) the stability of the WNTK at initialization and during training, and ii) the equivalence between the WNTK regression estimator and the corresponding NN estimator with different learning rates on different parameters. With the proposed weight update algorithm, both empirical and analytical WNTKs outperform the corresponding NTKs in numerical experiments.