 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparrow: Sparse Rollout for Stable and Efficient Long-context RL of Large Language Models
Jun 07, 2026Despite being powerful, reinforcement learning with verifiable rewards (RLVR) induces extremely long COT, making it computationally expensive. Since RLVR per-step cost is dominated by long-context rollout generation, sparse attention offers a promising way to accelerate dense rollout. However, sparse rollouts require a delicate stability-efficiency tradeoff: overly aggressive sparsity causes collapse, while overly lenient sparsity gives insufficient speedup. In this work, we study this tradeoff through sparse-to-dense actor-policy mismatch. We first observe that sparse rollout collapse is not driven by uniform degradation across tokens: most sparse tokens align perfectly with dense even under aggressive sparsity. Motivated by this, we hypothesize that sparse rollout training remains stable if the lower tail of per-token actor-policy mismatch stays above a critical threshold throughout the trajectory. We introduce a dynamic sparsity schedule that keeps this tail statistic constant during generation and validate our hypothesis. Across Qwen3 thinking-family models, keeping the tail mismatch statistic near a consistent threshold generally enables stable training. We then use a cost model to find the sparsity schedule for maximum speedup under this mismatch threshold, achieving 2.2x, 2.4x, and 2.0x rollout speedups when training Qwen3-1.7B, Qwen3-4B, and Qwen3-8B. Empirically, we show the thresholds generalize to a larger model (Qwen3-14B) and another RL domain (coding). Finally, our analysis naturally motivates DistillSparse: lightweight LoRA-based distillation on sparse rollout lets more aggressive sparsity reach the same sparse-to-dense mismatch threshold, yielding higher speedup.
The Last Human-Written Paper: Agent-Native Research Artifacts
Apr 27, 2026Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
MonarchRT: Efficient Attention for Real-Time Video Generation
Feb 12, 2026Real-time video generation with Diffusion Transformers is bottlenecked by the quadratic cost of 3D self-attention, especially in real-time regimes that are both few-step and autoregressive, where errors compound across time and each denoising step must carry substantially more information. In this setting, we find that prior sparse-attention approximations break down, despite showing strong results for bidirectional, many-step diffusion. Specifically, we observe that video attention is not reliably sparse, but instead combines pronounced periodic structure driven by spatiotemporal position with dynamic, sparse semantic correspondences and dense mixing, exceeding the representational capacity of even oracle top-k attention. Building on this insight, we propose Monarch-RT, a structured attention parameterization for video diffusion models that factorizes attention using Monarch matrices. Through appropriately aligned block structure and our extended tiled Monarch parameterization, we achieve high expressivity while preserving computational efficiency. We further overcome the overhead of parameterization through finetuning, with custom Triton kernels. We first validate the high efficacy of Monarch-RT over existing sparse baselines designed only for bidirectional models. We further observe that Monarch-RT attains up to 95% attention sparsity with no loss in quality when applied to the state-of-the-art model Self-Forcing, making Monarch-RT a pioneering work on highly-capable sparse attention parameterization for real-time video generation. Our optimized implementation outperforms FlashAttention-2, FlashAttention-3, and FlashAttention-4 kernels on Nvidia RTX 5090, H100, and B200 GPUs respectively, providing kernel speedups in the range of 1.4-11.8X. This enables us, for the first time, to achieve true real-time video generation with Self-Forcing at 16 FPS on a single RTX 5090.
Jackpot: Optimal Budgeted Rejection Sampling for Extreme Actor-Policy Mismatch Reinforcement Learning
Feb 05, 2026Reinforcement learning (RL) for large language models (LLMs) remains expensive, particularly because the rollout is expensive. Decoupling rollout generation from policy optimization (e.g., leveraging a more efficient model to rollout) could enable substantial efficiency gains, yet doing so introduces a severe distribution mismatch that destabilizes learning. We propose Jackpot, a framework that leverages Optimal Budget Rejection Sampling (OBRS) to directly reduce the discrepancy between the rollout model and the evolving policy. Jackpot integrates a principled OBRS procedure, a unified training objective that jointly updates the policy and rollout models, and an efficient system implementation enabled by top-$k$ probability estimation and batch-level bias correction. Our theoretical analysis shows that OBRS consistently moves the rollout distribution closer to the target distribution under a controllable acceptance budget. Empirically, \sys substantially improves training stability compared to importance-sampling baselines, achieving performance comparable to on-policy RL when training Qwen3-8B-Base for up to 300 update steps of batchsize 64. Taken together, our results show that OBRS-based alignment brings us a step closer to practical and effective decoupling of rollout generation from policy optimization for RL for LLMs.
RLBoost: Harvesting Preemptible Resources for Cost-Efficient Reinforcement Learning on LLMs
Oct 22, 2025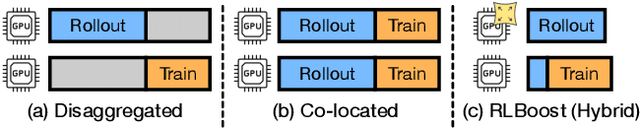
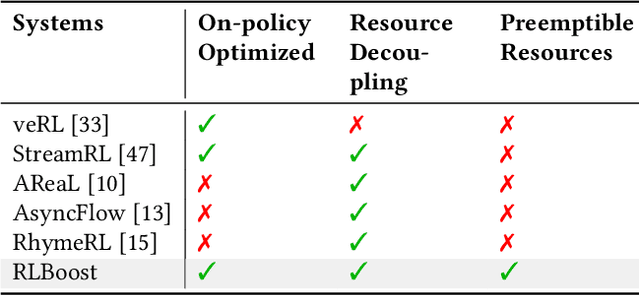
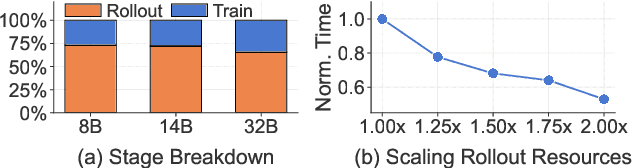
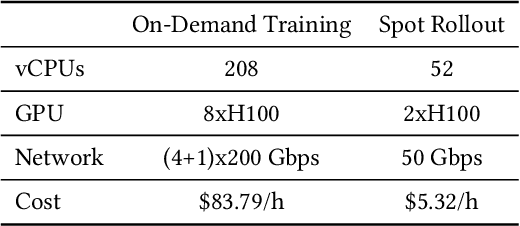
Reinforcement learning (RL) has become essential for unlocking advanced reasoning capabilities in large language models (LLMs). RL workflows involve interleaving rollout and training stages with fundamentally different resource requirements. Rollout typically dominates overall execution time, yet scales efficiently through multiple independent instances. In contrast, training requires tightly-coupled GPUs with full-mesh communication. Existing RL frameworks fall into two categories: co-located and disaggregated architectures. Co-located ones fail to address this resource tension by forcing both stages to share the same GPUs. Disaggregated architectures, without modifications of well-established RL algorithms, suffer from resource under-utilization. Meanwhile, preemptible GPU resources, i.e., spot instances on public clouds and spare capacity in production clusters, present significant cost-saving opportunities for accelerating RL workflows, if efficiently harvested for rollout. In this paper, we present RLBoost, a systematic solution for cost-efficient RL training that harvests preemptible GPU resources. Our key insight is that rollout's stateless and embarrassingly parallel nature aligns perfectly with preemptible and often fragmented resources. To efficiently utilize these resources despite frequent and unpredictable availability changes, RLBoost adopts a hybrid architecture with three key techniques: (1) adaptive rollout offload to dynamically adjust workloads on the reserved (on-demand) cluster, (2) pull-based weight transfer that quickly provisions newly available instances, and (3) token-level response collection and migration for efficient preemption handling and continuous load balancing. Extensive experiments show RLBoost increases training throughput by 1.51x-1.97x while improving cost efficiency by 28%-49% compared to using only on-demand GPU resources.
Kinetics: Rethinking Test-Time Scaling Laws
Jun 06, 2025We rethink test-time scaling laws from a practical efficiency perspective, revealing that the effectiveness of smaller models is significantly overestimated. Prior work, grounded in compute-optimality, overlooks critical memory access bottlenecks introduced by inference-time strategies (e.g., Best-of-$N$, long CoTs). Our holistic analysis, spanning models from 0.6B to 32B parameters, reveals a new Kinetics Scaling Law that better guides resource allocation by incorporating both computation and memory access costs. Kinetics Scaling Law suggests that test-time compute is more effective when used on models above a threshold than smaller ones. A key reason is that in TTS, attention, rather than parameter count, emerges as the dominant cost factor. Motivated by this, we propose a new scaling paradigm centered on sparse attention, which lowers per-token cost and enables longer generations and more parallel samples within the same resource budget. Empirically, we show that sparse attention models consistently outperform dense counterparts, achieving over 60 points gains in low-cost regimes and over 5 points gains in high-cost regimes for problem-solving accuracy on AIME, encompassing evaluations on state-of-the-art MoEs. These results suggest that sparse attention is essential and increasingly important with more computing invested, for realizing the full potential of test-time scaling where, unlike training, accuracy has yet to saturate as a function of computation, and continues to improve through increased generation. The code is available at https://github.com/Infini-AI-Lab/Kinetics.
ELFS: Enhancing Label-Free Coreset Selection via Clustering-based Pseudo-Labeling
Jun 06, 2024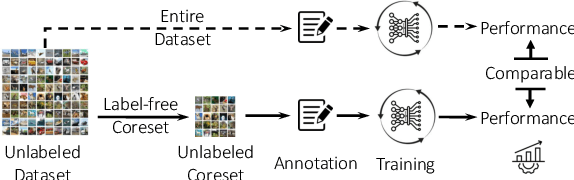
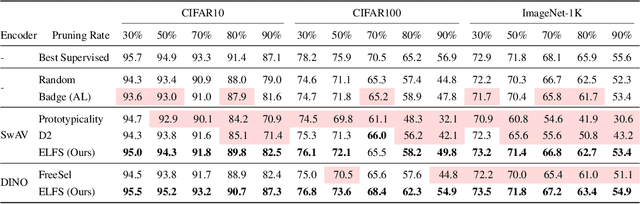

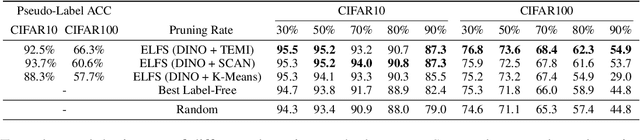
High-quality human-annotated data is crucial for modern deep learning pipelines, yet the human annotation process is both costly and time-consuming. Given a constrained human labeling budget, selecting an informative and representative data subset for labeling can significantly reduce human annotation effort. Well-performing state-of-the-art (SOTA) coreset selection methods require ground-truth labels over the whole dataset, failing to reduce the human labeling burden. Meanwhile, SOTA label-free coreset selection methods deliver inferior performance due to poor geometry-based scores. In this paper, we introduce ELFS, a novel label-free coreset selection method. ELFS employs deep clustering to estimate data difficulty scores without ground-truth labels. Furthermore, ELFS uses a simple but effective double-end pruning method to mitigate bias on calculated scores, which further improves the performance on selected coresets. We evaluate ELFS on five vision benchmarks and show that ELFS consistently outperforms SOTA label-free baselines. For instance, at a 90% pruning rate, ELFS surpasses the best-performing baseline by 5.3% on CIFAR10 and 7.1% on CIFAR100. Moreover, ELFS even achieves comparable performance to supervised coreset selection at low pruning rates (e.g., 30% and 50%) on CIFAR10 and ImageNet-1K.
Adaptive Skeleton Graph Decoding
Feb 19, 2024



Large language models (LLMs) have seen significant adoption for natural language tasks, owing their success to massive numbers of model parameters (e.g., 70B+); however, LLM inference incurs significant computation and memory costs. Recent approaches propose parallel decoding strategies, such as Skeleton-of-Thought (SoT), to improve performance by breaking prompts down into sub-problems that can be decoded in parallel; however, they often suffer from reduced response quality. Our key insight is that we can request additional information, specifically dependencies and difficulty, when generating the sub-problems to improve both response quality and performance. In this paper, we propose Skeleton Graph Decoding (SGD), which uses dependencies exposed between sub-problems to support information forwarding between dependent sub-problems for improved quality while exposing parallelization opportunities for decoding independent sub-problems. Additionally, we leverage difficulty estimates for each sub-problem to select an appropriately-sized model, improving performance without significantly reducing quality. Compared to standard autoregressive generation and SoT, SGD achieves a 1.69x speedup while improving quality by up to 51%.
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Feb 13, 2024



Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. Existing methods only focus on utilizing this naturally formed activation sparsity, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like GPT and LLaMA with soft activation functions. We evaluate LTE on four models and eleven datasets. The experiments show that LTE achieves a better trade-off between sparsity and task performance. For instance, LTE with LLaMA provides a 1.83x-2.59x FLOPs speed-up on language generation tasks, outperforming the state-of-the-art methods.
Leveraging Hierarchical Feature Sharing for Efficient Dataset Condensation
Oct 11, 2023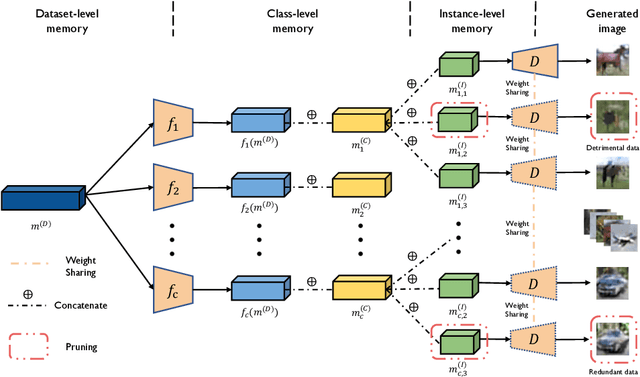
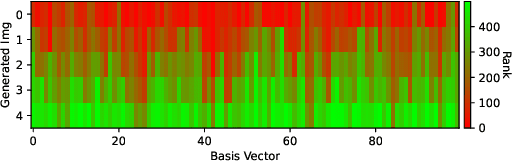
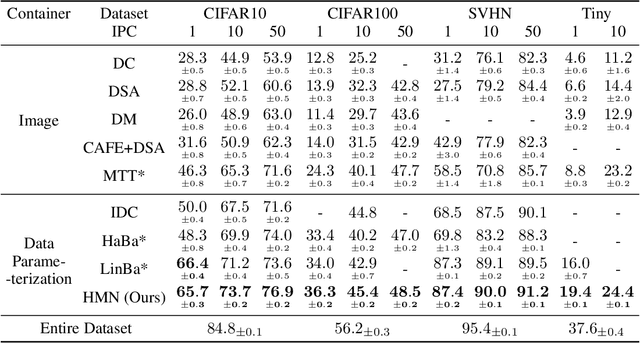
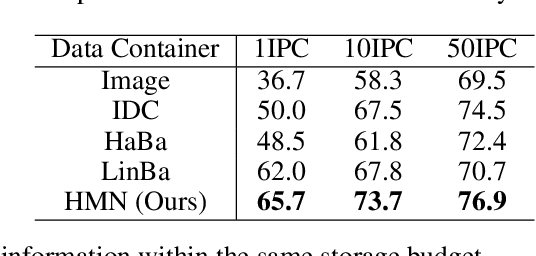
Given a real-world dataset, data condensation (DC) aims to synthesize a significantly smaller dataset that captures the knowledge of this dataset for model training with high performance. Recent works propose to enhance DC with data parameterization, which condenses data into parameterized data containers rather than pixel space. The intuition behind data parameterization is to encode shared features of images to avoid additional storage costs. In this paper, we recognize that images share common features in a hierarchical way due to the inherent hierarchical structure of the classification system, which is overlooked by current data parameterization methods. To better align DC with this hierarchical nature and encourage more efficient information sharing inside data containers, we propose a novel data parameterization architecture, Hierarchical Memory Network (HMN). HMN stores condensed data in a three-tier structure, representing the dataset-level, class-level, and instance-level features. Another helpful property of the hierarchical architecture is that HMN naturally ensures good independence among images despite achieving information sharing. This enables instance-level pruning for HMN to reduce redundant information, thereby further minimizing redundancy and enhancing performance. We evaluate HMN on four public datasets (SVHN, CIFAR10, CIFAR100, and Tiny-ImageNet) and compare HMN with eight DC baselines. The evaluation results show that our proposed method outperforms all baselines, even when trained with a batch-based loss consuming less GPU memory.