 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Human-Written Paper: Agent-Native Research Artifacts
Apr 27, 2026Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
Concept Incongruence: An Exploration of Time and Death in Role Playing
May 20, 2025Consider this prompt "Draw a unicorn with two horns". Should large language models (LLMs) recognize that a unicorn has only one horn by definition and ask users for clarifications, or proceed to generate something anyway? We introduce concept incongruence to capture such phenomena where concept boundaries clash with each other, either in user prompts or in model representations, often leading to under-specified or mis-specified behaviors. In this work, we take the first step towards defining and analyzing model behavior under concept incongruence. Focusing on temporal boundaries in the Role-Play setting, we propose three behavioral metrics--abstention rate, conditional accuracy, and answer rate--to quantify model behavior under incongruence due to the role's death. We show that models fail to abstain after death and suffer from an accuracy drop compared to the Non-Role-Play setting. Through probing experiments, we identify two main causes: (i) unreliable encoding of the "death" state across different years, leading to unsatisfactory abstention behavior, and (ii) role playing causes shifts in the model's temporal representations, resulting in accuracy drops. We leverage these insights to improve consistency in the model's abstention and answer behaviors. Our findings suggest that concept incongruence leads to unexpected model behaviors and point to future directions on improving model behavior under concept incongruence.
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Feb 13, 2024



Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. Existing methods only focus on utilizing this naturally formed activation sparsity, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like GPT and LLaMA with soft activation functions. We evaluate LTE on four models and eleven datasets. The experiments show that LTE achieves a better trade-off between sparsity and task performance. For instance, LTE with LLaMA provides a 1.83x-2.59x FLOPs speed-up on language generation tasks, outperforming the state-of-the-art methods.
A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity
Jan 03, 2024



While alignment algorithms are now commonly used to tune pre-trained language models towards a user's preferences, we lack explanations for the underlying mechanisms in which models become ``aligned'', thus making it difficult to explain phenomena like jailbreaks. In this work we study a popular algorithm, direct preference optimization (DPO), and the mechanisms by which it reduces toxicity. Namely, we first study how toxicity is represented and elicited in a pre-trained language model, GPT2-medium. We then apply DPO with a carefully crafted pairwise dataset to reduce toxicity. We examine how the resulting model averts toxic outputs, and find that capabilities learned from pre-training are not removed, but rather bypassed. We use this insight to demonstrate a simple method to un-align the model, reverting it back to its toxic behavior.
PromptRank: Unsupervised Keyphrase Extraction Using Prompt
May 15, 2023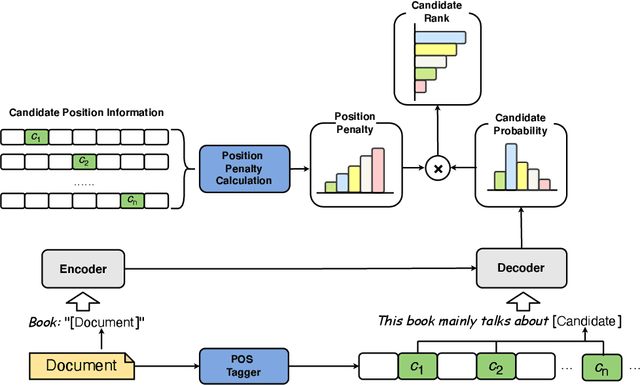



The keyphrase extraction task refers to the automatic selection of phrases from a given document to summarize its core content. State-of-the-art (SOTA) performance has recently been achieved by embedding-based algorithms, which rank candidates according to how similar their embeddings are to document embeddings. However, such solutions either struggle with the document and candidate length discrepancies or fail to fully utilize the pre-trained language model (PLM) without further fine-tuning. To this end, in this paper, we propose a simple yet effective unsupervised approach, PromptRank, based on the PLM with an encoder-decoder architecture. Specifically, PromptRank feeds the document into the encoder and calculates the probability of generating the candidate with a designed prompt by the decoder. We extensively evaluate the proposed PromptRank on six widely used benchmarks. PromptRank outperforms the SOTA approach MDERank, improving the F1 score relatively by 34.18%, 24.87%, and 17.57% for 5, 10, and 15 returned results, respectively. This demonstrates the great potential of using prompt for unsupervised keyphrase extraction. We release our code at https://github.com/HLT-NLP/PromptRank.