 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Prompt Tuning: Enable Autonomous Role-Playing in LLMs
Jul 12, 2024



Recent advancements in LLMs have showcased their remarkable role-playing capabilities, able to accurately simulate the dialogue styles and cognitive processes of various roles based on different instructions and contexts. Studies indicate that assigning LLMs the roles of experts, a strategy known as role-play prompting, can enhance their performance in the corresponding domains. However, the prompt needs to be manually designed for the given problem, requiring certain expertise and iterative modifications. To this end, we propose self-prompt tuning, making LLMs themselves generate role-play prompts through fine-tuning. Leveraging the LIMA dataset as our foundational corpus, we employ GPT-4 to annotate role-play prompts for each data points, resulting in the creation of the LIMA-Role dataset. We then fine-tune LLMs like Llama-2-7B and Mistral-7B on LIMA-Role. Consequently, the self-prompt tuned LLMs can automatically generate expert role prompts for any given question. We extensively evaluate self-prompt tuned LLMs on widely used NLP benchmarks and open-ended question test. Our empirical results illustrate that self-prompt tuned LLMs outperform standard instruction tuned baselines across most datasets. This highlights the great potential of utilizing fine-tuning to enable LLMs to self-prompt, thereby automating complex prompting strategies. We release the dataset, models, and code at this \href{https://anonymous.4open.science/r/Self-Prompt-Tuning-739E/}{url}.
CSST Strong Lensing Preparation: a Framework for Detecting Strong Lenses in the Multi-color Imaging Survey by the China Survey Space Telescope (CSST)
Apr 02, 2024Strong gravitational lensing is a powerful tool for investigating dark matter and dark energy properties. With the advent of large-scale sky surveys, we can discover strong lensing systems on an unprecedented scale, which requires efficient tools to extract them from billions of astronomical objects. The existing mainstream lens-finding tools are based on machine learning algorithms and applied to cut-out-centered galaxies. However, according to the design and survey strategy of optical surveys by CSST, preparing cutouts with multiple bands requires considerable efforts. To overcome these challenges, we have developed a framework based on a hierarchical visual Transformer with a sliding window technique to search for strong lensing systems within entire images. Moreover, given that multi-color images of strong lensing systems can provide insights into their physical characteristics, our framework is specifically crafted to identify strong lensing systems in images with any number of channels. As evaluated using CSST mock data based on an Semi-Analytic Model named CosmoDC2, our framework achieves precision and recall rates of 0.98 and 0.90, respectively. To evaluate the effectiveness of our method in real observations, we have applied it to a subset of images from the DESI Legacy Imaging Surveys and media images from Euclid Early Release Observations. 61 new strong lensing system candidates are discovered by our method. However, we also identified false positives arising primarily from the simplified galaxy morphology assumptions within the simulation. This underscores the practical limitations of our approach while simultaneously highlighting potential avenues for future improvements.
ONE-SA: Enabling Nonlinear Operations in Systolic Arrays for Efficient and Flexible Neural Network Inference
Feb 01, 2024



The computation and memory-intensive nature of DNNs limits their use in many mobile and embedded contexts. Application-specific integrated circuit (ASIC) hardware accelerators employ matrix multiplication units (such as the systolic arrays) and dedicated nonlinear function units to speed up DNN computations. A close examination of these ASIC accelerators reveals that the designs are often specialized and lack versatility across different networks, especially when the networks have different types of computation. In this paper, we introduce a novel systolic array architecture, which is capable of executing nonlinear functions. By encompassing both inherent linear and newly enabled nonlinear functions within the systolic arrays, the proposed architecture facilitates versatile network inferences, substantially enhancing computational power and energy efficiency. Experimental results show that employing this systolic array enables seamless execution of entire DNNs, incurring only a negligible loss in the network inference accuracy. Furthermore, assessment and evaluation with FPGAs reveal that integrating nonlinear computation capacity into a systolic array does not introduce extra notable (less than 1.5%) block memory memories (BRAMs), look-up-tables (LUTs), or digital signal processors (DSPs) but a mere 13.3% - 24.1% more flip flops (FFs). In comparison to existing methodologies, executing the networks with the proposed systolic array, which enables the flexibility of different network models, yields up to 25.73x, 5.21x, and 1.54x computational efficiency when compared to general-purpose CPUs, GPUs, and SoCs respectively, while achieving comparable (83.4% - 135.8%) performance with the conventional accelerators which are designed for specific neural network models.
Better Zero-Shot Reasoning with Role-Play Prompting
Aug 15, 2023



Modern large language models (LLMs), such as ChatGPT, exhibit a remarkable capacity for role-playing, enabling them to embody not only human characters but also non-human entities like a Linux terminal. This versatility allows them to simulate complex human-like interactions and behaviors within various contexts, as well as to emulate specific objects or systems. While these capabilities have enhanced user engagement and introduced novel modes of interaction, the influence of role-playing on LLMs' reasoning abilities remains underexplored. In this study, we introduce a strategically designed role-play prompting methodology and assess its performance under the zero-shot setting across twelve diverse reasoning benchmarks, encompassing arithmetic, commonsense reasoning, symbolic reasoning, and more. Leveraging models such as ChatGPT and Llama 2, our empirical results illustrate that role-play prompting consistently surpasses the standard zero-shot approach across most datasets. Notably, accuracy on AQuA rises from 53.5% to 63.8%, and on Last Letter from 23.8% to 84.2%. Beyond enhancing contextual understanding, we posit that role-play prompting serves as an implicit Chain-of-Thought (CoT) trigger, thereby improving the quality of reasoning. By comparing our approach with the Zero-Shot-CoT technique, which prompts the model to "think step by step", we further demonstrate that role-play prompting can generate a more effective CoT. This highlights its potential to augment the reasoning capabilities of LLMs.
NeuralMatrix: Moving Entire Neural Networks to General Matrix Multiplication for Efficient Inference
May 23, 2023In this study, we introduce NeuralMatrix, a novel framework that enables the computation of versatile deep neural networks (DNNs) on a single general matrix multiplication (GEMM) accelerator. The proposed approach overcomes the specificity limitations of ASIC-based accelerators while achieving application-specific acceleration levels compared to general-purpose processors such as CPUs and GPUs. We address the challenges of mapping both linear and nonlinear operations in DNN computation to general matrix multiplications and the impact of using a GEMM accelerator on DNN inference accuracy. Extensive experiments are conducted on various DNN models from three popular categories (i.e., CNN, Transformers, and GNN) as illustrative backbone models. Our results demonstrate that DNNs suffer only up to a 2.02% accuracy loss after being converted to general matrix multiplication, while achieving 113x to 19.44x improvements in throughput per power compared to CPUs and GPUs.
PromptRank: Unsupervised Keyphrase Extraction Using Prompt
May 15, 2023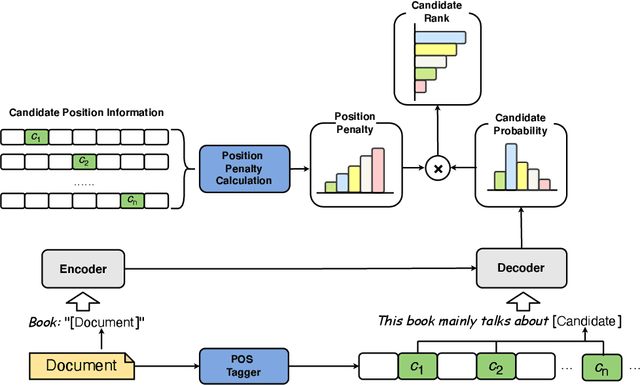



The keyphrase extraction task refers to the automatic selection of phrases from a given document to summarize its core content. State-of-the-art (SOTA) performance has recently been achieved by embedding-based algorithms, which rank candidates according to how similar their embeddings are to document embeddings. However, such solutions either struggle with the document and candidate length discrepancies or fail to fully utilize the pre-trained language model (PLM) without further fine-tuning. To this end, in this paper, we propose a simple yet effective unsupervised approach, PromptRank, based on the PLM with an encoder-decoder architecture. Specifically, PromptRank feeds the document into the encoder and calculates the probability of generating the candidate with a designed prompt by the decoder. We extensively evaluate the proposed PromptRank on six widely used benchmarks. PromptRank outperforms the SOTA approach MDERank, improving the F1 score relatively by 34.18%, 24.87%, and 17.57% for 5, 10, and 15 returned results, respectively. This demonstrates the great potential of using prompt for unsupervised keyphrase extraction. We release our code at https://github.com/HLT-NLP/PromptRank.
Detection of Strongly Lensed Arcs in Galaxy Clusters with Transformers
Nov 11, 2022Strong lensing in galaxy clusters probes properties of dense cores of dark matter halos in mass, studies the distant universe at flux levels and spatial resolutions otherwise unavailable, and constrains cosmological models independently. The next-generation large scale sky imaging surveys are expected to discover thousands of cluster-scale strong lenses, which would lead to unprecedented opportunities for applying cluster-scale strong lenses to solve astrophysical and cosmological problems. However, the large dataset challenges astronomers to identify and extract strong lensing signals, particularly strongly lensed arcs, because of their complexity and variety. Hence, we propose a framework to detect cluster-scale strongly lensed arcs, which contains a transformer-based detection algorithm and an image simulation algorithm. We embed prior information of strongly lensed arcs at cluster-scale into the training data through simulation and then train the detection algorithm with simulated images. We use the trained transformer to detect strongly lensed arcs from simulated and real data. Results show that our approach could achieve 99.63 % accuracy rate, 90.32 % recall rate, 85.37 % precision rate and 0.23 % false positive rate in detection of strongly lensed arcs from simulated images and could detect almost all strongly lensed arcs in real observation images. Besides, with an interpretation method, we have shown that our method could identify important information embedded in simulated data. Next step, to test the reliability and usability of our approach, we will apply it to available observations (e.g., DESI Legacy Imaging Surveys) and simulated data of upcoming large-scale sky surveys, such as the Euclid and the CSST.
Data--driven Image Restoration with Option--driven Learning for Big and Small Astronomical Image Datasets
Nov 07, 2020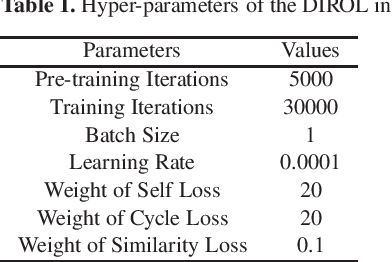
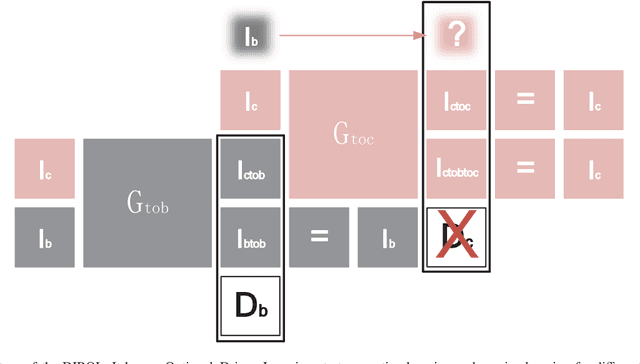
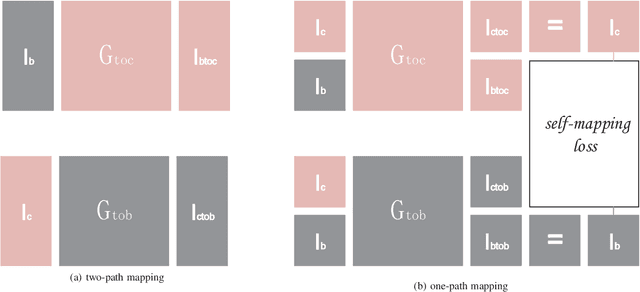

Image restoration methods are commonly used to improve the quality of astronomical images. In recent years, developments of deep neural networks and increments of the number of astronomical images have evoked a lot of data--driven image restoration methods. However, most of these methods belong to supervised learning algorithms, which require paired images either from real observations or simulated data as training set. For some applications, it is hard to get enough paired images from real observations and simulated images are quite different from real observed ones. In this paper, we propose a new data--driven image restoration method based on generative adversarial networks with option--driven learning. Our method uses several high resolution images as references and applies different learning strategies when the number of reference images is different. For sky surveys with variable observation conditions, our method can obtain very stable image restoration results, regardless of the number of reference images.