 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiver-LLM: Large Language Model Seamless Exit Based on KV Share
Apr 20, 2026Large Language Models (LLMs) have demonstrated exceptional performance across diverse domains but are increasingly constrained by high inference latency. Early Exit has emerged as a promising solution to accelerate inference by dynamically bypassing redundant layers. However, in decoder-only architectures, the efficiency of Early Exit is severely bottlenecked by the KV Cache Absence problem, where skipped layers fail to provide the necessary historical states for subsequent tokens. Existing solutions, such as recomputation or masking, either introduce significant latency overhead or incur severe precision loss, failing to bridge the gap between theoretical layer reduction and practical wall-clock speedup. In this paper, we propose River-LLM, a training-free framework that enables seamless token-level Early Exit. River-LLM introduces a lightweight KV-Shared Exit River that allows the backbone's missing KV cache to be naturally generated and preserved during the exit process, eliminating the need for costly recovery operations. Furthermore, we utilize state transition similarity within decoder blocks to predict cumulative KV errors and guide precise exit decisions. Extensive experiments on mathematical reasoning and code generation tasks demonstrate that River-LLM achieves 1.71 to 2.16 times of practical speedup while maintaining high generation quality.
TimeBill: Time-Budgeted Inference for Large Language Models
Dec 26, 2025

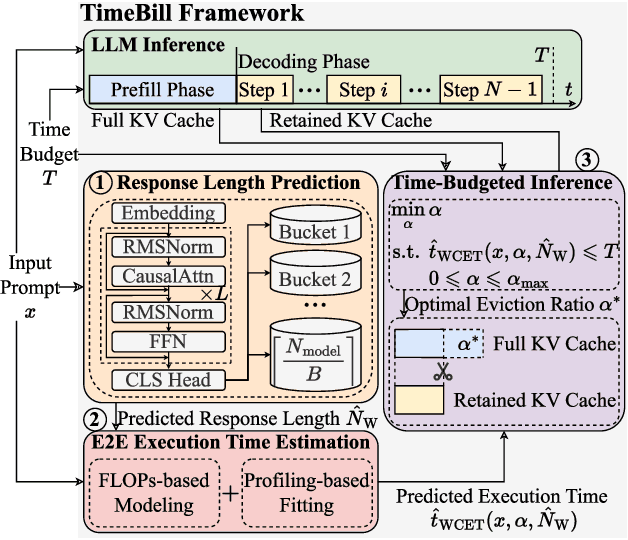

Large Language Models (LLMs) are increasingly deployed in time-critical systems, such as robotics, autonomous driving, embodied intelligence, and industrial automation, where generating accurate responses within a given time budget is crucial for decision-making, control, or safety-critical tasks. However, the auto-regressive generation process of LLMs makes it challenging to model and estimate the end-to-end execution time. Furthermore, existing efficient inference methods based on a fixed key-value (KV) cache eviction ratio struggle to adapt to varying tasks with diverse time budgets, where an improper eviction ratio may lead to incomplete inference or a drop in response performance. In this paper, we propose TimeBill, a novel time-budgeted inference framework for LLMs that balances the inference efficiency and response performance. To be more specific, we propose a fine-grained response length predictor (RLP) and an execution time estimator (ETE) to accurately predict the end-to-end execution time of LLMs. Following this, we develop a time-budgeted efficient inference approach that adaptively adjusts the KV cache eviction ratio based on execution time prediction and the given time budget. Finally, through extensive experiments, we demonstrate the advantages of TimeBill in improving task completion rate and maintaining response performance under various overrun strategies.
CUDA-LLM: LLMs Can Write Efficient CUDA Kernels
Jun 10, 2025



Large Language Models (LLMs) have demonstrated strong capabilities in general-purpose code generation. However, generating the code which is deeply hardware-specific, architecture-aware, and performance-critical, especially for massively parallel GPUs, remains a complex challenge. In this work, we explore the use of LLMs for the automated generation and optimization of CUDA programs, with the goal of producing high-performance GPU kernels that fully exploit the underlying hardware. To address this challenge, we propose a novel framework called \textbf{Feature Search and Reinforcement (FSR)}. FSR jointly optimizes compilation and functional correctness, as well as the runtime performance, which are validated through extensive and diverse test cases, and measured by actual kernel execution latency on the target GPU, respectively. This approach enables LLMs not only to generate syntactically and semantically correct CUDA code but also to iteratively refine it for efficiency, tailored to the characteristics of the GPU architecture. We evaluate FSR on representative CUDA kernels, covering AI workloads and computational intensive algorithms. Our results show that LLMs augmented with FSR consistently guarantee correctness rates. Meanwhile, the automatically generated kernels can outperform general human-written code by a factor of up to 179$\times$ in execution speeds. These findings highlight the potential of combining LLMs with performance reinforcement to automate GPU programming for hardware-specific, architecture-sensitive, and performance-critical applications.
Chain of Compression: A Systematic Approach to Combinationally Compress Convolutional Neural Networks
Mar 26, 2024Convolutional neural networks (CNNs) have achieved significant popularity, but their computational and memory intensity poses challenges for resource-constrained computing systems, particularly with the prerequisite of real-time performance. To release this burden, model compression has become an important research focus. Many approaches like quantization, pruning, early exit, and knowledge distillation have demonstrated the effect of reducing redundancy in neural networks. Upon closer examination, it becomes apparent that each approach capitalizes on its unique features to compress the neural network, and they can also exhibit complementary behavior when combined. To explore the interactions and reap the benefits from the complementary features, we propose the Chain of Compression, which works on the combinational sequence to apply these common techniques to compress the neural network. Validated on the image-based regression and classification networks across different data sets, our proposed Chain of Compression can significantly compress the computation cost by 100-1000 times with ignorable accuracy loss compared with the baseline model.
ONE-SA: Enabling Nonlinear Operations in Systolic Arrays for Efficient and Flexible Neural Network Inference
Feb 01, 2024



The computation and memory-intensive nature of DNNs limits their use in many mobile and embedded contexts. Application-specific integrated circuit (ASIC) hardware accelerators employ matrix multiplication units (such as the systolic arrays) and dedicated nonlinear function units to speed up DNN computations. A close examination of these ASIC accelerators reveals that the designs are often specialized and lack versatility across different networks, especially when the networks have different types of computation. In this paper, we introduce a novel systolic array architecture, which is capable of executing nonlinear functions. By encompassing both inherent linear and newly enabled nonlinear functions within the systolic arrays, the proposed architecture facilitates versatile network inferences, substantially enhancing computational power and energy efficiency. Experimental results show that employing this systolic array enables seamless execution of entire DNNs, incurring only a negligible loss in the network inference accuracy. Furthermore, assessment and evaluation with FPGAs reveal that integrating nonlinear computation capacity into a systolic array does not introduce extra notable (less than 1.5%) block memory memories (BRAMs), look-up-tables (LUTs), or digital signal processors (DSPs) but a mere 13.3% - 24.1% more flip flops (FFs). In comparison to existing methodologies, executing the networks with the proposed systolic array, which enables the flexibility of different network models, yields up to 25.73x, 5.21x, and 1.54x computational efficiency when compared to general-purpose CPUs, GPUs, and SoCs respectively, while achieving comparable (83.4% - 135.8%) performance with the conventional accelerators which are designed for specific neural network models.
NeuralMatrix: Moving Entire Neural Networks to General Matrix Multiplication for Efficient Inference
May 23, 2023In this study, we introduce NeuralMatrix, a novel framework that enables the computation of versatile deep neural networks (DNNs) on a single general matrix multiplication (GEMM) accelerator. The proposed approach overcomes the specificity limitations of ASIC-based accelerators while achieving application-specific acceleration levels compared to general-purpose processors such as CPUs and GPUs. We address the challenges of mapping both linear and nonlinear operations in DNN computation to general matrix multiplications and the impact of using a GEMM accelerator on DNN inference accuracy. Extensive experiments are conducted on various DNN models from three popular categories (i.e., CNN, Transformers, and GNN) as illustrative backbone models. Our results demonstrate that DNNs suffer only up to a 2.02% accuracy loss after being converted to general matrix multiplication, while achieving 113x to 19.44x improvements in throughput per power compared to CPUs and GPUs.
Predictive Exit: Prediction of Fine-Grained Early Exits for Computation- and Energy-Efficient Inference
Jun 09, 2022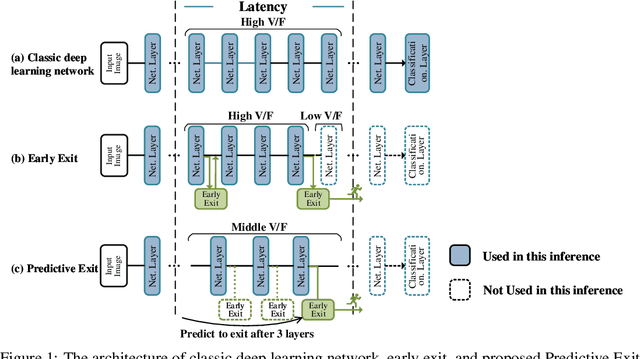
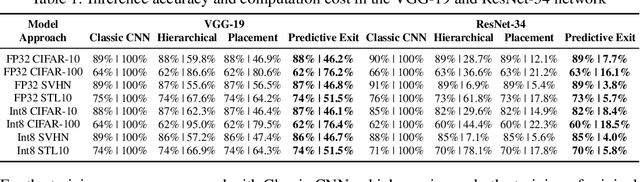
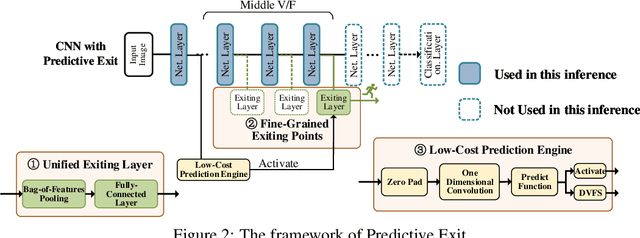
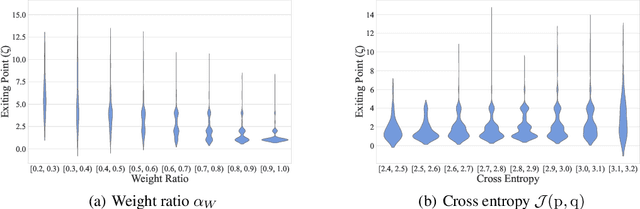
By adding exiting layers to the deep learning networks, early exit can terminate the inference earlier with accurate results. The passive decision-making of whether to exit or continue the next layer has to go through every pre-placed exiting layer until it exits. In addition, it is also hard to adjust the configurations of the computing platforms alongside the inference proceeds. By incorporating a low-cost prediction engine, we propose a Predictive Exit framework for computation- and energy-efficient deep learning applications. Predictive Exit can forecast where the network will exit (i.e., establish the number of remaining layers to finish the inference), which effectively reduces the network computation cost by exiting on time without running every pre-placed exiting layer. Moreover, according to the number of remaining layers, proper computing configurations (i.e., frequency and voltage) are selected to execute the network to further save energy. Extensive experimental results demonstrate that Predictive Exit achieves up to 96.2% computation reduction and 72.9% energy-saving compared with classic deep learning networks; and 12.8% computation reduction and 37.6% energy-saving compared with the early exit under state-of-the-art exiting strategies, given the same inference accuracy and latency.
RTGPU: Real-Time GPU Scheduling of Hard Deadline Parallel Tasks with Fine-Grain Utilization
Jan 27, 2021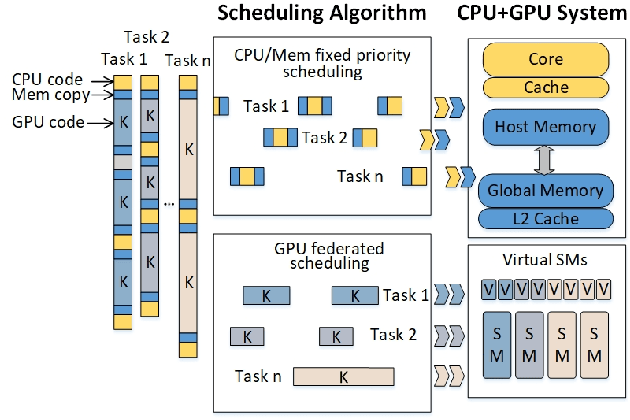
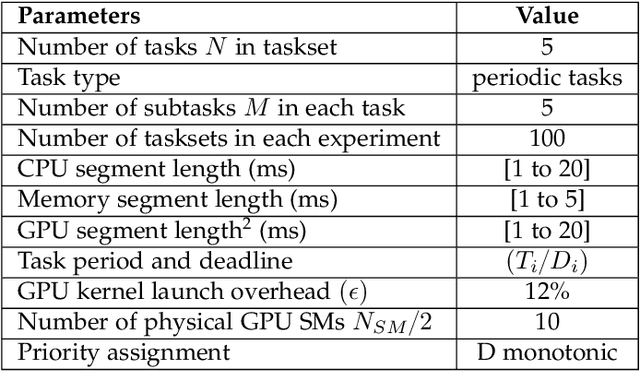
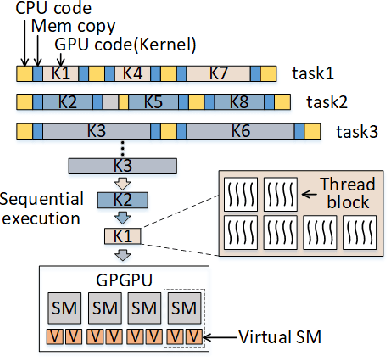
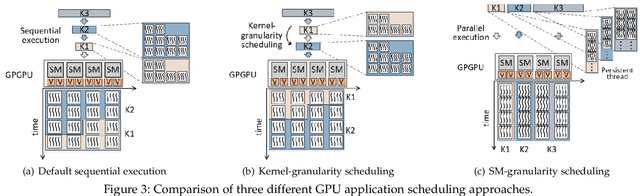
Many emerging cyber-physical systems, such as autonomous vehicles and robots, rely heavily on artificial intelligence and machine learning algorithms to perform important system operations. Since these highly parallel applications are computationally intensive, they need to be accelerated by graphics processing units (GPUs) to meet stringent timing constraints. However, despite the wide adoption of GPUs, efficiently scheduling multiple GPU applications while providing rigorous real-time guarantees remains a challenge. In this paper, we propose RTGPU, which can schedule the execution of multiple GPU applications in real-time to meet hard deadlines. Each GPU application can have multiple CPU execution and memory copy segments, as well as GPU kernels. We start with a model to explicitly account for the CPU and memory copy segments of these applications. We then consider the GPU architecture in the development of a precise timing model for the GPU kernels and leverage a technique known as persistent threads to implement fine-grained kernel scheduling with improved performance through interleaved execution. Next, we propose a general method for scheduling parallel GPU applications in real time. Finally, to schedule multiple parallel GPU applications, we propose a practical real-time scheduling algorithm based on federated scheduling and grid search (for GPU kernel segments) with uniprocessor fixed priority scheduling (for multiple CPU and memory copy segments). Our approach provides superior schedulability compared with previous work, and gives real-time guarantees to meet hard deadlines for multiple GPU applications according to comprehensive validation and evaluation on a real NVIDIA GTX1080Ti GPU system.