 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Multimodal Federated Learning via Chained Modality Optimization
Jun 01, 2026Multimodal Federated Learning (MMFL) enables privacy-preserving collaborative learning across decentralized clients with heterogeneous data and modality availability. However, most existing MMFL methods cast multimodal training as a joint optimization problem, overlooking a key bottleneck: modality competition, where dominant modalities suppress weaker ones and lead to suboptimal global models. To address this, we propose FedMChain, a balanced MMFL framework that structures federated multimodal training as a chain of modality-wise phases. This phase-wise design gives each modality a dedicated local optimization window on multimodal clients to mitigate modality competition, and further promotes cross-modal complementarity via an error-compensated regularizer. On the server side, we employ a sparse sign-guided aggregation strategy that leverages directional sign agreement for robust intra-modality aggregation, avoids destructive averaging, and supports less frequent synchronization to reduce communication overhead. Extensive experiments on multimodal benchmarks demonstrate that FedMChain consistently improves predictive performance while requiring less frequent communication than baselines.
Towards Domain-Generalized Open-Vocabulary Object Detection: A Progressive Domain-invariant Cross-modal Alignment Method
Mar 29, 2026Open-Vocabulary Object Detection (OVOD) has achieved remarkable success in generalizing to novel categories. However, this success often rests on the implicit assumption of domain stationarity. In this work, we provide a principled revisit of the OVOD paradigm, uncovering a fundamental vulnerability: the fragile coupling between visual manifolds and textual embeddings when distribution shifts occur. We first systematically formalize Domain-Generalized Open-Vocabulary Object Detection (DG-OVOD). Through empirical analysis, we demonstrate that visual shifts do not merely add noise; they cause a collapse of the latent cross-modal space where novel category visual signals detach from their semantic anchors. Motivated by these insights, we propose Progressive Domain-invariant Cross-modal Alignment (PICA). PICA departs from uniform training by introducing a multi-level ambiguity and signal strength curriculum. It builds adaptive pseudo-word prototypes, refined via sample confidence and visual consistency, to enforce invariant cross-domain modality alignment. Our findings suggest that OVOD's robustness to domain shifts is intrinsically linked to the stability of the latent cross-modal alignment space. Our work provides both a challenging benchmark and a new perspective on building truly generalizable open-vocabulary systems that extend beyond static laboratory conditions.
A Step Toward Federated Pretraining of Multimodal Large Language Models
Mar 25, 2026The rapid evolution of Multimodal Large Language Models (MLLMs) is bottlenecked by the saturation of high-quality public data, while vast amounts of diverse multimodal data remain inaccessible in privacy-sensitive silos. Federated Learning (FL) offers a promising solution to unlock these distributed resources, but existing research focuses predominantly on fine-tuning, leaving the foundational pre-training phase largely unexplored. In this paper, we formally introduce the Federated MLLM Alignment (Fed-MA) task, a lightweight pre-training paradigm that freezes the vision encoder and LLM while collaboratively training the cross-modal projector. We identify two critical challenges in this setting: (i) parameter interference in aggregating local projectors; and (ii) gradient oscillations in one-pass collaborative SGD. To address these challenges, we propose Fed-CMP, a pioneering framework for federated MLLM pre-training. Fed-CMP employs Canonical Reliability-Aware Aggregation, which constructs a canonical space to decompose client projectors into a shared alignment basis and client-specific coefficients, then performs reliability-weighted fusion to suppress parameter interference. Furthermore, Fed-CMP introduces Orthogonality-Preserved Momentum, which applies momentum to the shared alignment basis via orthogonal projection, accumulating historical optimization directions while preserving geometric structure. We construct four federated pre-training scenarios based on public datasets, and extensive experiments validate that Fed-CMP significantly outperforms existing baselines.
Replacing Parameters with Preferences: Federated Alignment of Heterogeneous Vision-Language Models
Jan 31, 2026VLMs have broad potential in privacy-sensitive domains such as healthcare and finance, yet strict data-sharing constraints render centralized training infeasible. FL mitigates this issue by enabling decentralized training, but practical deployments face challenges due to client heterogeneity in computational resources, application requirements, and model architectures. We argue that while replacing data with model parameters characterizes the present of FL, replacing parameters with preferences represents a more scalable and privacy-preserving future. Motivated by this perspective, we propose MoR, a federated alignment framework based on GRPO with Mixture-of-Rewards for heterogeneous VLMs. MoR initializes a visual foundation model as a KL-regularized reference, while each client locally trains a reward model from local preference annotations, capturing specific evaluation signals without exposing raw data. To reconcile heterogeneous rewards, we introduce a routing-based fusion mechanism that adaptively aggregates client reward signals. Finally, the server performs GRPO with this mixed reward to optimize the base VLM. Experiments on three public VQA benchmarks demonstrate that MoR consistently outperforms federated alignment baselines in generalization, robustness, and cross-client adaptability. Our approach provides a scalable solution for privacy-preserving alignment of heterogeneous VLMs under federated settings.
Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation
Jun 05, 2025In recent years, Multimodal Large Language Models (MLLMs) have been extensively utilized for multimodal reasoning tasks, including Graphical User Interface (GUI) automation. Unlike general offline multimodal tasks, GUI automation is executed in online interactive environments, necessitating step-by-step decision-making based on real-time status of the environment. This task has a lower tolerance for decision-making errors at each step, as any mistakes may cumulatively disrupt the process and potentially lead to irreversible outcomes like deletions or payments. To address these issues, we introduce a pre-operative critic mechanism that provides effective feedback prior to the actual execution, by reasoning about the potential outcome and correctness of actions. Specifically, we propose a Suggestion-aware Gradient Relative Policy Optimization (S-GRPO) strategy to construct our pre-operative critic model GUI-Critic-R1, incorporating a novel suggestion reward to enhance the reliability of the model's feedback. Furthermore, we develop a reasoning-bootstrapping based data collection pipeline to create a GUI-Critic-Train and a GUI-Critic-Test, filling existing gaps in GUI critic data. Static experiments on the GUI-Critic-Test across both mobile and web domains reveal that our GUI-Critic-R1 offers significant advantages in critic accuracy compared to current MLLMs. Dynamic evaluation on GUI automation benchmark further highlights the effectiveness and superiority of our model, as evidenced by improved success rates and operational efficiency.
Harmony: A Unified Framework for Modality Incremental Learning
Apr 17, 2025Incremental learning aims to enable models to continuously acquire knowledge from evolving data streams while preserving previously learned capabilities. While current research predominantly focuses on unimodal incremental learning and multimodal incremental learning where the modalities are consistent, real-world scenarios often present data from entirely new modalities, posing additional challenges. This paper investigates the feasibility of developing a unified model capable of incremental learning across continuously evolving modal sequences. To this end, we introduce a novel paradigm called Modality Incremental Learning (MIL), where each learning stage involves data from distinct modalities. To address this task, we propose a novel framework named Harmony, designed to achieve modal alignment and knowledge retention, enabling the model to reduce the modal discrepancy and learn from a sequence of distinct modalities, ultimately completing tasks across multiple modalities within a unified framework. Our approach introduces the adaptive compatible feature modulation and cumulative modal bridging. Through constructing historical modal features and performing modal knowledge accumulation and alignment, the proposed components collaboratively bridge modal differences and maintain knowledge retention, even with solely unimodal data available at each learning phase.These components work in concert to establish effective modality connections and maintain knowledge retention, even when only unimodal data is available at each learning stage. Extensive experiments on the MIL task demonstrate that our proposed method significantly outperforms existing incremental learning methods, validating its effectiveness in MIL scenarios.
Towards Visual Grounding: A Survey
Dec 28, 2024



Visual Grounding is also known as Referring Expression Comprehension and Phrase Grounding. It involves localizing a natural number of specific regions within an image based on a given textual description. The objective of this task is to emulate the prevalent referential relationships in social conversations, equipping machines with human-like multimodal comprehension capabilities. Consequently, it has extensive applications in various domains. However, since 2021, visual grounding has witnessed significant advancements, with emerging new concepts such as grounded pre-training, grounding multimodal LLMs, generalized visual grounding, and giga-pixel grounding, which have brought numerous new challenges. In this survey, we initially examine the developmental history of visual grounding and provide an overview of essential background knowledge. We systematically track and summarize the advancements and meticulously organize the various settings in visual grounding, thereby establishing precise definitions of these settings to standardize future research and ensure a fair comparison. Additionally, we delve into several advanced topics and highlight numerous applications of visual grounding. Finally, we outline the challenges confronting visual grounding and propose valuable directions for future research, which may serve as inspiration for subsequent researchers. By extracting common technical details, this survey encompasses the representative works in each subtopic over the past decade. To the best, this paper presents the most comprehensive overview currently available in the field of grounding. This survey is designed to be suitable for both beginners and experienced researchers, serving as an invaluable resource for understanding key concepts and tracking the latest research developments. We keep tracing related works at https://github.com/linhuixiao/Awesome-Visual-Grounding.
OneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling
Oct 10, 2024
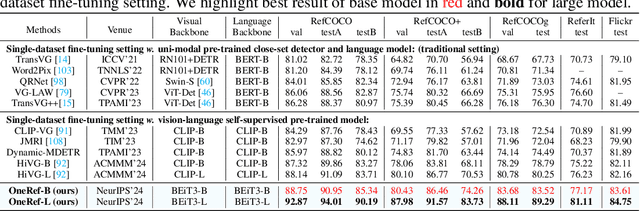
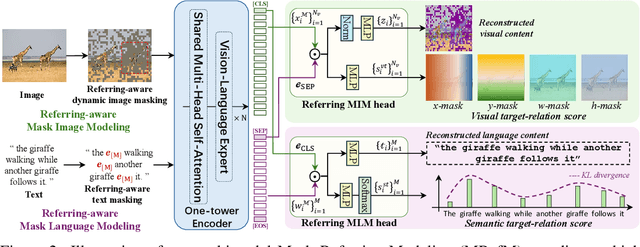
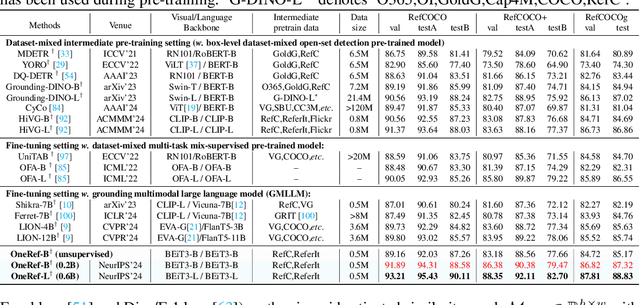
Constrained by the separate encoding of vision and language, existing grounding and referring segmentation works heavily rely on bulky Transformer-based fusion en-/decoders and a variety of early-stage interaction technologies. Simultaneously, the current mask visual language modeling (MVLM) fails to capture the nuanced referential relationship between image-text in referring tasks. In this paper, we propose OneRef, a minimalist referring framework built on the modality-shared one-tower transformer that unifies the visual and linguistic feature spaces. To modeling the referential relationship, we introduce a novel MVLM paradigm called Mask Referring Modeling (MRefM), which encompasses both referring-aware mask image modeling and referring-aware mask language modeling. Both modules not only reconstruct modality-related content but also cross-modal referring content. Within MRefM, we propose a referring-aware dynamic image masking strategy that is aware of the referred region rather than relying on fixed ratios or generic random masking schemes. By leveraging the unified visual language feature space and incorporating MRefM's ability to model the referential relations, our approach enables direct regression of the referring results without resorting to various complex techniques. Our method consistently surpasses existing approaches and achieves SoTA performance on both grounding and segmentation tasks, providing valuable insights for future research. Our code and models are available at https://github.com/linhuixiao/OneRef.
A Comprehensive Review of Few-shot Action Recognition
Jul 20, 2024



Few-shot action recognition aims to address the high cost and impracticality of manually labeling complex and variable video data in action recognition. It requires accurately classifying human actions in videos using only a few labeled examples per class. Compared to few-shot learning in image scenarios, few-shot action recognition is more challenging due to the intrinsic complexity of video data. Recognizing actions involves modeling intricate temporal sequences and extracting rich semantic information, which goes beyond mere human and object identification in each frame. Furthermore, the issue of intra-class variance becomes particularly pronounced with limited video samples, complicating the learning of representative features for novel action categories. To overcome these challenges, numerous approaches have driven significant advancements in few-shot action recognition, which underscores the need for a comprehensive survey. Unlike early surveys that focus on few-shot image or text classification, we deeply consider the unique challenges of few-shot action recognition. In this survey, we review a wide variety of recent methods and summarize the general framework. Additionally, the survey presents the commonly used benchmarks and discusses relevant advanced topics and promising future directions. We hope this survey can serve as a valuable resource for researchers, offering essential guidance to newcomers and stimulating seasoned researchers with fresh insights.
Libra: Building Decoupled Vision System on Large Language Models
May 16, 2024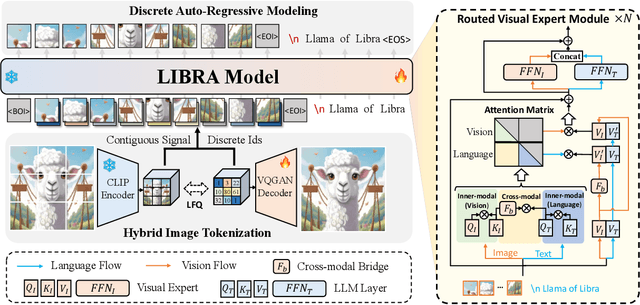



In this work, we introduce Libra, a prototype model with a decoupled vision system on a large language model (LLM). The decoupled vision system decouples inner-modal modeling and cross-modal interaction, yielding unique visual information modeling and effective cross-modal comprehension. Libra is trained through discrete auto-regressive modeling on both vision and language inputs. Specifically, we incorporate a routed visual expert with a cross-modal bridge module into a pretrained LLM to route the vision and language flows during attention computing to enable different attention patterns in inner-modal modeling and cross-modal interaction scenarios. Experimental results demonstrate that the dedicated design of Libra achieves a strong MLLM baseline that rivals existing works in the image-to-text scenario with merely 50 million training data, providing a new perspective for future multimodal foundation models. Code is available at https://github.com/YifanXu74/Libra.