 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling
Oct 10, 2024
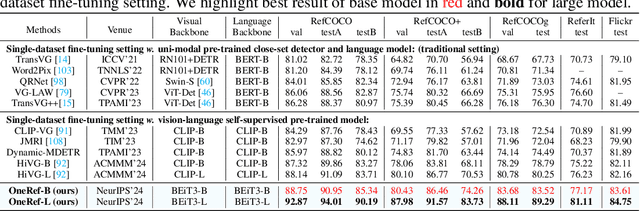
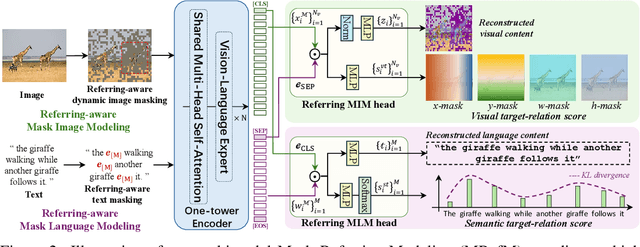
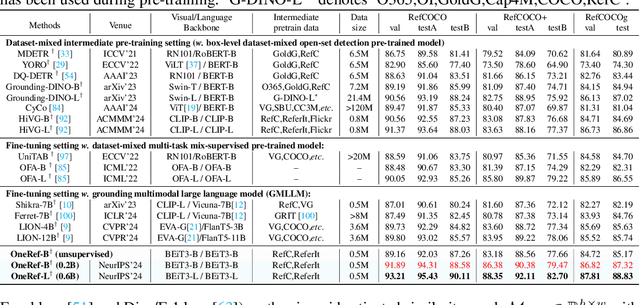
Constrained by the separate encoding of vision and language, existing grounding and referring segmentation works heavily rely on bulky Transformer-based fusion en-/decoders and a variety of early-stage interaction technologies. Simultaneously, the current mask visual language modeling (MVLM) fails to capture the nuanced referential relationship between image-text in referring tasks. In this paper, we propose OneRef, a minimalist referring framework built on the modality-shared one-tower transformer that unifies the visual and linguistic feature spaces. To modeling the referential relationship, we introduce a novel MVLM paradigm called Mask Referring Modeling (MRefM), which encompasses both referring-aware mask image modeling and referring-aware mask language modeling. Both modules not only reconstruct modality-related content but also cross-modal referring content. Within MRefM, we propose a referring-aware dynamic image masking strategy that is aware of the referred region rather than relying on fixed ratios or generic random masking schemes. By leveraging the unified visual language feature space and incorporating MRefM's ability to model the referential relations, our approach enables direct regression of the referring results without resorting to various complex techniques. Our method consistently surpasses existing approaches and achieves SoTA performance on both grounding and segmentation tasks, providing valuable insights for future research. Our code and models are available at https://github.com/linhuixiao/OneRef.
SALI: Short-term Alignment and Long-term Interaction Network for Colonoscopy Video Polyp Segmentation
Jun 19, 2024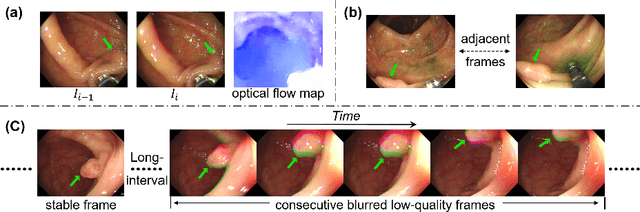
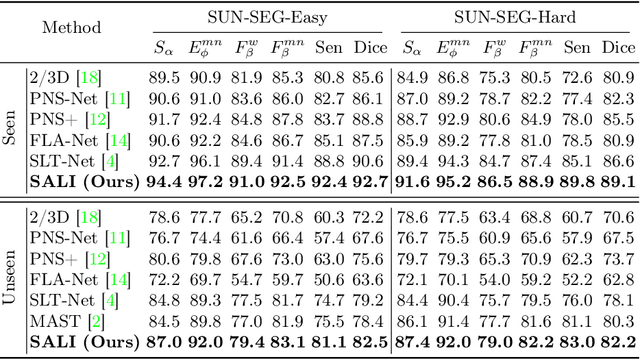
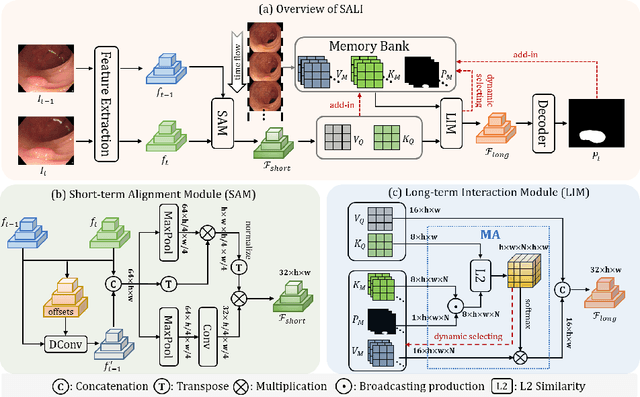
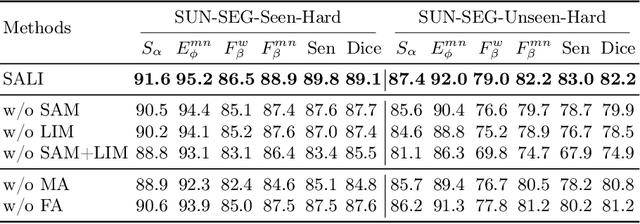
Colonoscopy videos provide richer information in polyp segmentation for rectal cancer diagnosis. However, the endoscope's fast moving and close-up observing make the current methods suffer from large spatial incoherence and continuous low-quality frames, and thus yield limited segmentation accuracy. In this context, we focus on robust video polyp segmentation by enhancing the adjacent feature consistency and rebuilding the reliable polyp representation. To achieve this goal, we in this paper propose SALI network, a hybrid of Short-term Alignment Module (SAM) and Long-term Interaction Module (LIM). The SAM learns spatial-aligned features of adjacent frames via deformable convolution and further harmonizes them to capture more stable short-term polyp representation. In case of low-quality frames, the LIM stores the historical polyp representations as a long-term memory bank, and explores the retrospective relations to interactively rebuild more reliable polyp features for the current segmentation. Combing SAM and LIM, the SALI network of video segmentation shows a great robustness to the spatial variations and low-visual cues. Benchmark on the large-scale SUNSEG verifies the superiority of SALI over the current state-of-the-arts by improving Dice by 2.1%, 2.5%, 4.1% and 1.9%, for the four test sub-sets, respectively. Codes are at https://github.com/Scatteredrain/SALI.
HiVG: Hierarchical Multimodal Fine-grained Modulation for Visual Grounding
Apr 20, 2024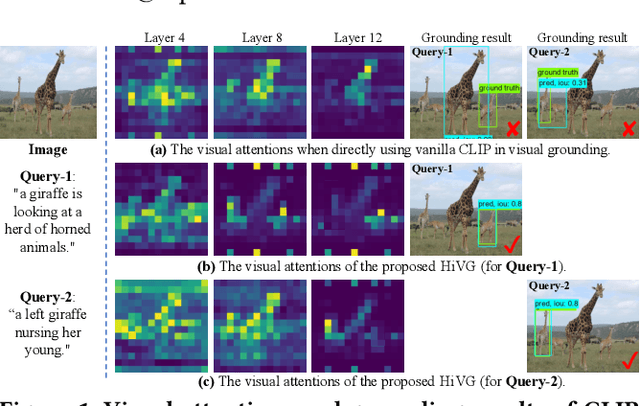
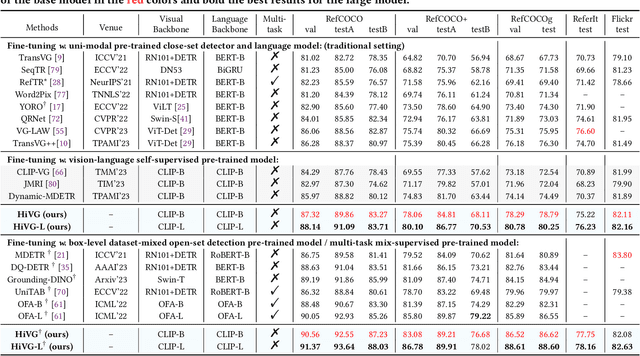
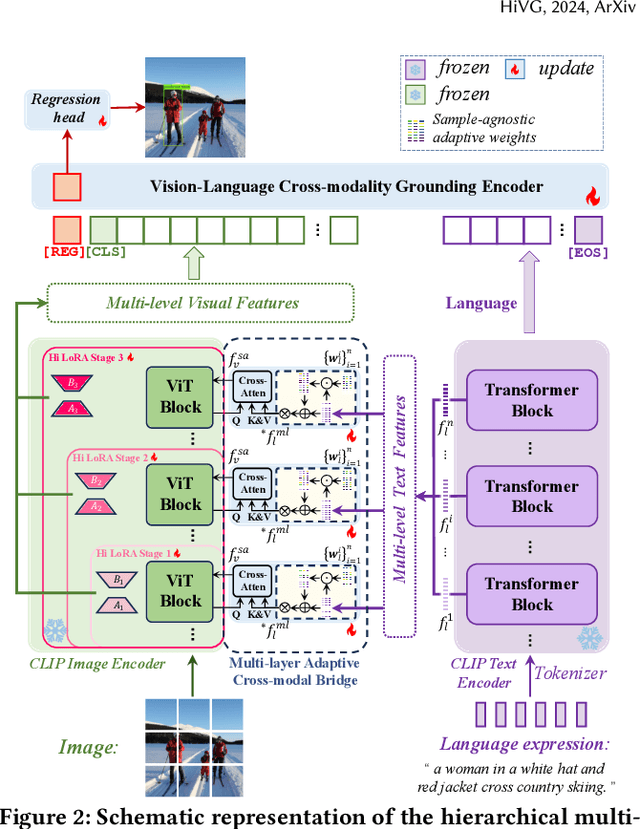
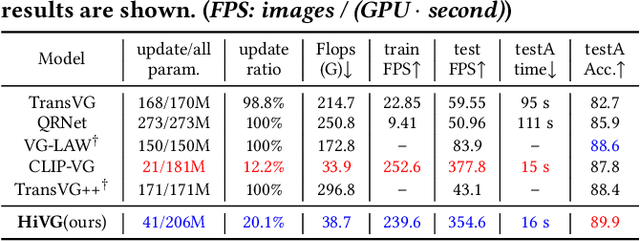
Visual grounding, which aims to ground a visual region via natural language, is a task that heavily relies on cross-modal alignment. Existing works utilized uni-modal pre-trained models to transfer visual/linguistic knowledge separately while ignoring the multimodal corresponding information. Motivated by recent advancements in contrastive language-image pre-training and low-rank adaptation (LoRA) methods, we aim to solve the grounding task based on multimodal pre-training. However, there exists significant task gaps between pre-training and grounding. Therefore, to address these gaps, we propose a concise and efficient hierarchical multimodal fine-grained modulation framework, namely HiVG. Specifically, HiVG consists of a multi-layer adaptive cross-modal bridge and a hierarchical multimodal low-rank adaptation (Hi LoRA) paradigm. The cross-modal bridge can address the inconsistency between visual features and those required for grounding, and establish a connection between multi-level visual and text features. Hi LoRA prevents the accumulation of perceptual errors by adapting the cross-modal features from shallow to deep layers in a hierarchical manner. Experimental results on five datasets demonstrate the effectiveness of our approach and showcase the significant grounding capabilities as well as promising energy efficiency advantages. The project page: https://github.com/linhuixiao/HiVG.
CLIP-VG: Self-paced Curriculum Adapting of CLIP via Exploiting Pseudo-Language Labels for Visual Grounding
May 15, 2023



Visual Grounding (VG) refers to locating a region described by expressions in a specific image, which is a critical topic in vision-language fields. To alleviate the dependence on labeled data, existing unsupervised methods try to locate regions using task-unrelated pseudo-labels. However, a large proportion of pseudo-labels are noisy and diversity scarcity in language taxonomy. Inspired by the advances in V-L pretraining, we consider utilizing the VLP models to realize unsupervised transfer learning in downstream grounding task. Thus, we propose CLIP-VG, a novel method that can conduct self-paced curriculum adapting of CLIP via exploiting pseudo-language labels to solve VG problem. By elaborating an efficient model structure, we first propose a single-source and multi-source curriculum adapting method for unsupervised VG to progressively sample more reliable cross-modal pseudo-labels to obtain the optimal model, thus achieving implicit knowledge exploiting and denoising. Our method outperforms the existing state-of-the-art unsupervised VG method Pseudo-Q in both single-source and multi-source scenarios with a large margin, i.e., 6.78%~10.67% and 11.39%~24.87% on RefCOCO/+/g datasets, even outperforms existing weakly supervised methods. The code and models will be released at \url{https://github.com/linhuixiao/CLIP-VG}.
SgVA-CLIP: Semantic-guided Visual Adapting of Vision-Language Models for Few-shot Image Classification
Nov 28, 2022



Although significant progress has been made in few-shot learning, most of existing few-shot learning methods require supervised pre-training on a large amount of samples of base classes, which limits their generalization ability in real world application. Recently, large-scale self-supervised vision-language models (e.g., CLIP) have provided a new paradigm for transferable visual representation learning. However, the pre-trained VLPs may neglect detailed visual information that is difficult to describe by language sentences, but important for learning an effective classifier in few-shot classification. To address the above problem, we propose a new framework, named Semantic-guided Visual Adapting (SgVA), which can effectively extend vision-language pre-trained models to produce discriminative task-specific visual features by comprehensively using a vision-specific contrastive loss, a cross-modal contrastive loss, and an implicit knowledge distillation. The implicit knowledge distillation is designed to transfer the fine-grained cross-modal knowledge to guide the updating of the vision adapter. State-of-the-art results on 13 datasets demonstrate that the adapted visual features can well complement the cross-modal features to improve few-shot image classification.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021
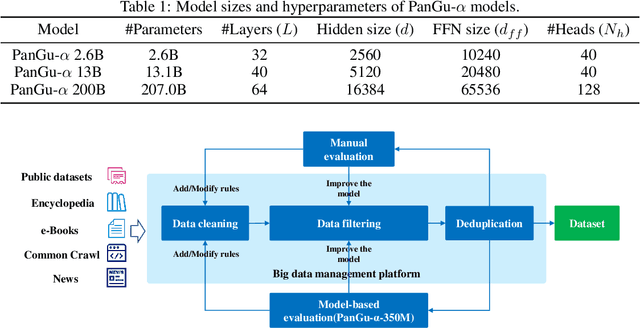
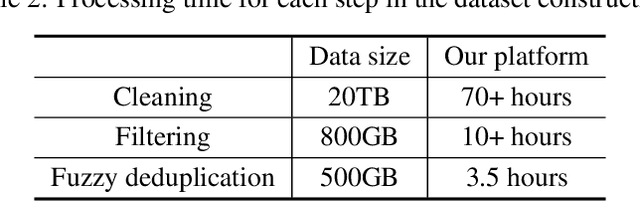
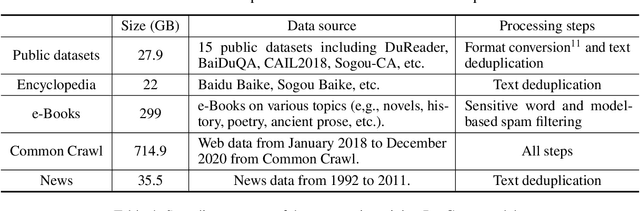
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.