 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARE: Towards Bias-Aware and Reasoning-Enhanced One-Tower Visual Grounding
Jan 04, 2026Visual Grounding (VG), which aims to locate a specific region referred to by expressions, is a fundamental yet challenging task in the multimodal understanding fields. While recent grounding transfer works have advanced the field through one-tower architectures, they still suffer from two primary limitations: (1) over-entangled multimodal representations that exacerbate deceptive modality biases, and (2) insufficient semantic reasoning that hinders the comprehension of referential cues. In this paper, we propose BARE, a bias-aware and reasoning-enhanced framework for one-tower visual grounding. BARE introduces a mechanism that preserves modality-specific features and constructs referential semantics through three novel modules: (i) language salience modulator, (ii) visual bias correction and (iii) referential relationship enhancement, which jointly mitigate multimodal distractions and enhance referential comprehension. Extensive experimental results on five benchmarks demonstrate that BARE not only achieves state-of-the-art performance but also delivers superior computational efficiency compared to existing approaches. The code is publicly accessible at https://github.com/Marloweeee/BARE.
RGBT-Ground Benchmark: Visual Grounding Beyond RGB in Complex Real-World Scenarios
Dec 31, 2025Visual Grounding (VG) aims to localize specific objects in an image according to natural language expressions, serving as a fundamental task in vision-language understanding. However, existing VG benchmarks are mostly derived from datasets collected under clean environments, such as COCO, where scene diversity is limited. Consequently, they fail to reflect the complexity of real-world conditions, such as changes in illumination, weather, etc., that are critical to evaluating model robustness and generalization in safety-critical applications. To address these limitations, we present RGBT-Ground, the first large-scale visual grounding benchmark built for complex real-world scenarios. It consists of spatially aligned RGB and Thermal infrared (TIR) image pairs with high-quality referring expressions, corresponding object bounding boxes, and fine-grained annotations at the scene, environment, and object levels. This benchmark enables comprehensive evaluation and facilitates the study of robust grounding under diverse and challenging conditions. Furthermore, we establish a unified visual grounding framework that supports both uni-modal (RGB or TIR) and multi-modal (RGB-TIR) visual inputs. Based on it, we propose RGBT-VGNet, a simple yet effective baseline for fusing complementary visual modalities to achieve robust grounding. We conduct extensive adaptations to the existing methods on RGBT-Ground. Experimental results show that our proposed RGBT-VGNet significantly outperforms these adapted methods, particularly in nighttime and long-distance scenarios. All resources will be publicly released to promote future research on robust visual grounding in complex real-world environments.
Towards Visual Grounding: A Survey
Dec 28, 2024



Visual Grounding is also known as Referring Expression Comprehension and Phrase Grounding. It involves localizing a natural number of specific regions within an image based on a given textual description. The objective of this task is to emulate the prevalent referential relationships in social conversations, equipping machines with human-like multimodal comprehension capabilities. Consequently, it has extensive applications in various domains. However, since 2021, visual grounding has witnessed significant advancements, with emerging new concepts such as grounded pre-training, grounding multimodal LLMs, generalized visual grounding, and giga-pixel grounding, which have brought numerous new challenges. In this survey, we initially examine the developmental history of visual grounding and provide an overview of essential background knowledge. We systematically track and summarize the advancements and meticulously organize the various settings in visual grounding, thereby establishing precise definitions of these settings to standardize future research and ensure a fair comparison. Additionally, we delve into several advanced topics and highlight numerous applications of visual grounding. Finally, we outline the challenges confronting visual grounding and propose valuable directions for future research, which may serve as inspiration for subsequent researchers. By extracting common technical details, this survey encompasses the representative works in each subtopic over the past decade. To the best, this paper presents the most comprehensive overview currently available in the field of grounding. This survey is designed to be suitable for both beginners and experienced researchers, serving as an invaluable resource for understanding key concepts and tracking the latest research developments. We keep tracing related works at https://github.com/linhuixiao/Awesome-Visual-Grounding.
OneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling
Oct 10, 2024
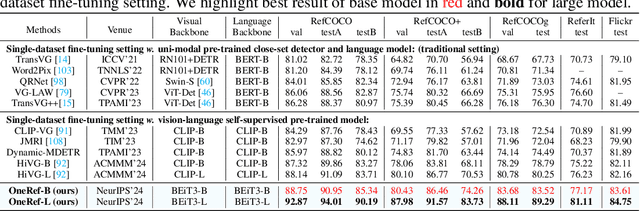
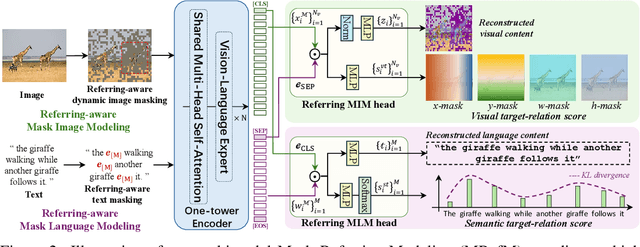
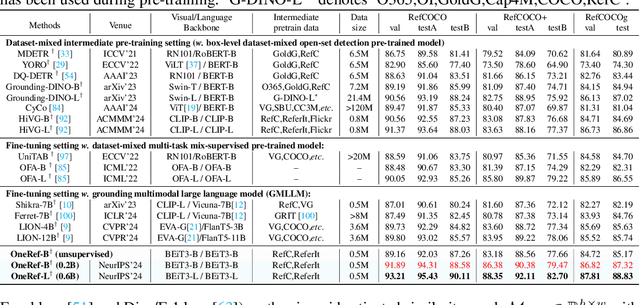
Constrained by the separate encoding of vision and language, existing grounding and referring segmentation works heavily rely on bulky Transformer-based fusion en-/decoders and a variety of early-stage interaction technologies. Simultaneously, the current mask visual language modeling (MVLM) fails to capture the nuanced referential relationship between image-text in referring tasks. In this paper, we propose OneRef, a minimalist referring framework built on the modality-shared one-tower transformer that unifies the visual and linguistic feature spaces. To modeling the referential relationship, we introduce a novel MVLM paradigm called Mask Referring Modeling (MRefM), which encompasses both referring-aware mask image modeling and referring-aware mask language modeling. Both modules not only reconstruct modality-related content but also cross-modal referring content. Within MRefM, we propose a referring-aware dynamic image masking strategy that is aware of the referred region rather than relying on fixed ratios or generic random masking schemes. By leveraging the unified visual language feature space and incorporating MRefM's ability to model the referential relations, our approach enables direct regression of the referring results without resorting to various complex techniques. Our method consistently surpasses existing approaches and achieves SoTA performance on both grounding and segmentation tasks, providing valuable insights for future research. Our code and models are available at https://github.com/linhuixiao/OneRef.
HiVG: Hierarchical Multimodal Fine-grained Modulation for Visual Grounding
Apr 20, 2024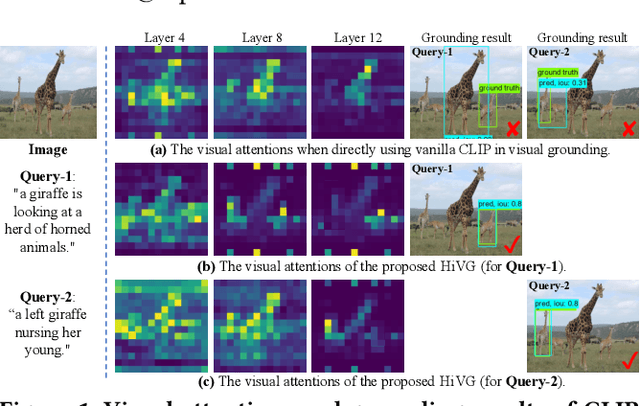
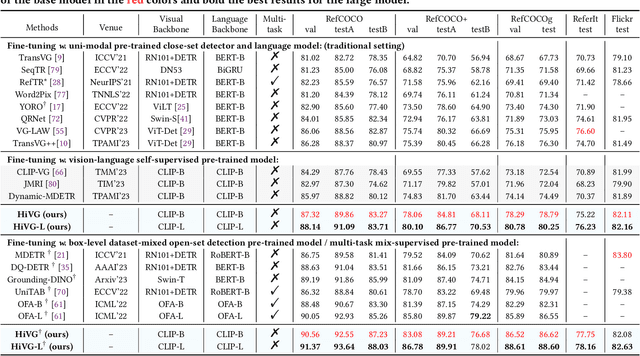
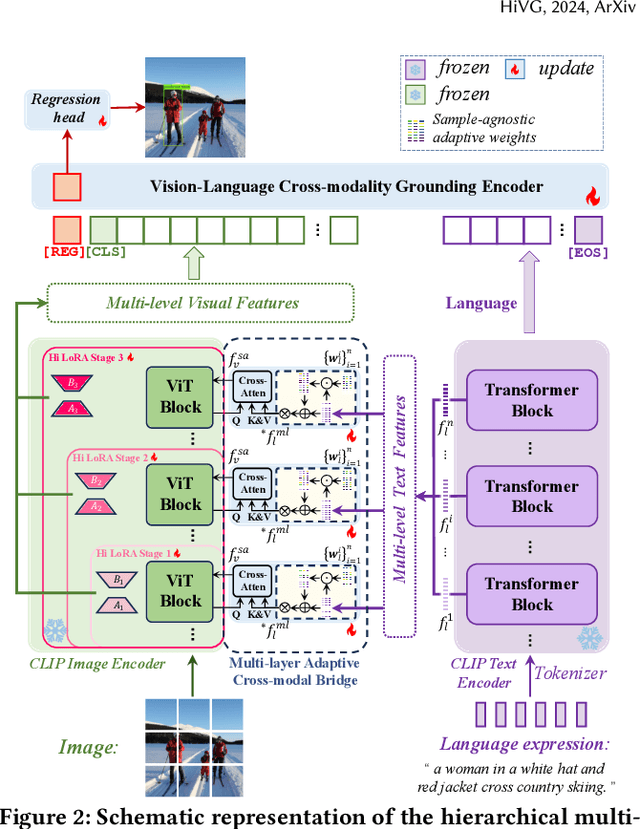
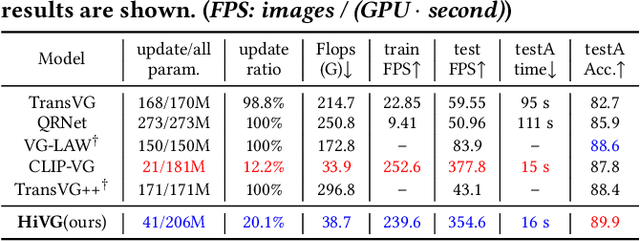
Visual grounding, which aims to ground a visual region via natural language, is a task that heavily relies on cross-modal alignment. Existing works utilized uni-modal pre-trained models to transfer visual/linguistic knowledge separately while ignoring the multimodal corresponding information. Motivated by recent advancements in contrastive language-image pre-training and low-rank adaptation (LoRA) methods, we aim to solve the grounding task based on multimodal pre-training. However, there exists significant task gaps between pre-training and grounding. Therefore, to address these gaps, we propose a concise and efficient hierarchical multimodal fine-grained modulation framework, namely HiVG. Specifically, HiVG consists of a multi-layer adaptive cross-modal bridge and a hierarchical multimodal low-rank adaptation (Hi LoRA) paradigm. The cross-modal bridge can address the inconsistency between visual features and those required for grounding, and establish a connection between multi-level visual and text features. Hi LoRA prevents the accumulation of perceptual errors by adapting the cross-modal features from shallow to deep layers in a hierarchical manner. Experimental results on five datasets demonstrate the effectiveness of our approach and showcase the significant grounding capabilities as well as promising energy efficiency advantages. The project page: https://github.com/linhuixiao/HiVG.
CLIP-VG: Self-paced Curriculum Adapting of CLIP via Exploiting Pseudo-Language Labels for Visual Grounding
May 15, 2023



Visual Grounding (VG) refers to locating a region described by expressions in a specific image, which is a critical topic in vision-language fields. To alleviate the dependence on labeled data, existing unsupervised methods try to locate regions using task-unrelated pseudo-labels. However, a large proportion of pseudo-labels are noisy and diversity scarcity in language taxonomy. Inspired by the advances in V-L pretraining, we consider utilizing the VLP models to realize unsupervised transfer learning in downstream grounding task. Thus, we propose CLIP-VG, a novel method that can conduct self-paced curriculum adapting of CLIP via exploiting pseudo-language labels to solve VG problem. By elaborating an efficient model structure, we first propose a single-source and multi-source curriculum adapting method for unsupervised VG to progressively sample more reliable cross-modal pseudo-labels to obtain the optimal model, thus achieving implicit knowledge exploiting and denoising. Our method outperforms the existing state-of-the-art unsupervised VG method Pseudo-Q in both single-source and multi-source scenarios with a large margin, i.e., 6.78%~10.67% and 11.39%~24.87% on RefCOCO/+/g datasets, even outperforms existing weakly supervised methods. The code and models will be released at \url{https://github.com/linhuixiao/CLIP-VG}.