 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu DeepDiver: Adaptive Search Intensity Scaling via Open-Web Reinforcement Learning
May 30, 2025Information seeking demands iterative evidence gathering and reflective reasoning, yet large language models (LLMs) still struggle with it in open-web question answering. Existing methods rely on static prompting rules or training with Wikipedia-based corpora and retrieval environments, limiting adaptability to the real-world web environment where ambiguity, conflicting evidence, and noise are prevalent. These constrained training settings hinder LLMs from learning to dynamically decide when and where to search, and how to adjust search depth and frequency based on informational demands. We define this missing capacity as Search Intensity Scaling (SIS)--the emergent skill to intensify search efforts under ambiguous or conflicting conditions, rather than settling on overconfident, under-verification answers. To study SIS, we introduce WebPuzzle, the first dataset designed to foster information-seeking behavior in open-world internet environments. WebPuzzle consists of 24K training instances and 275 test questions spanning both wiki-based and open-web queries. Building on this dataset, we propose DeepDiver, a Reinforcement Learning (RL) framework that promotes SIS by encouraging adaptive search policies through exploration under a real-world open-web environment. Experimental results show that Pangu-7B-Reasoner empowered by DeepDiver achieve performance on real-web tasks comparable to the 671B-parameter DeepSeek-R1. We detail DeepDiver's training curriculum from cold-start supervised fine-tuning to a carefully designed RL phase, and present that its capability of SIS generalizes from closed-form QA to open-ended tasks such as long-form writing. Our contributions advance adaptive information seeking in LLMs and provide a valuable benchmark and dataset for future research.
Self-Adjust Softmax
Feb 25, 2025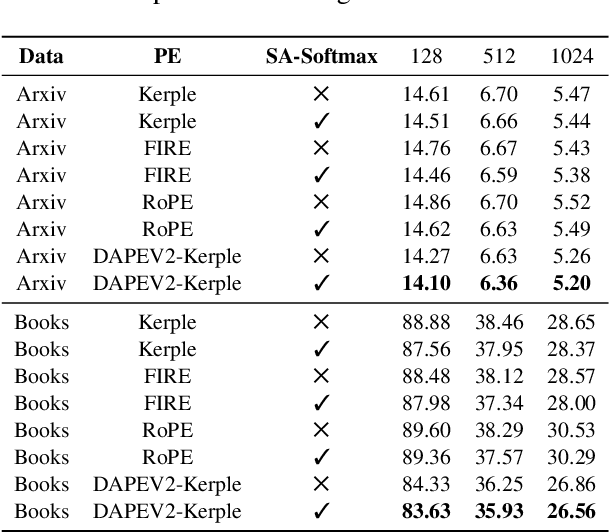
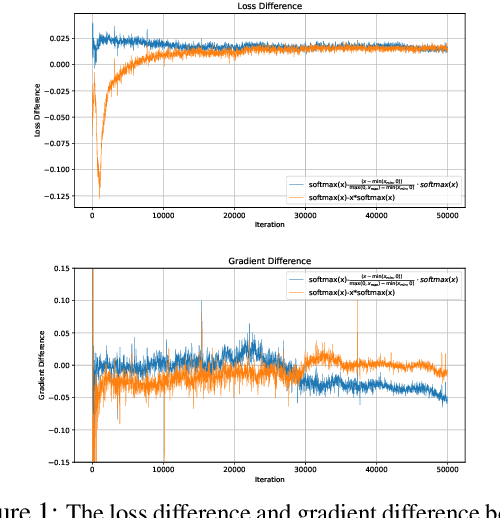
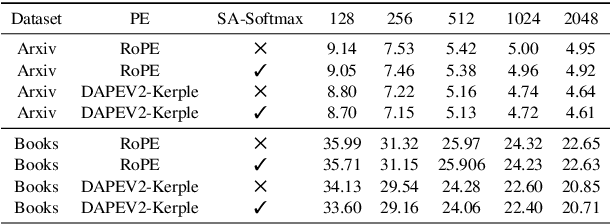
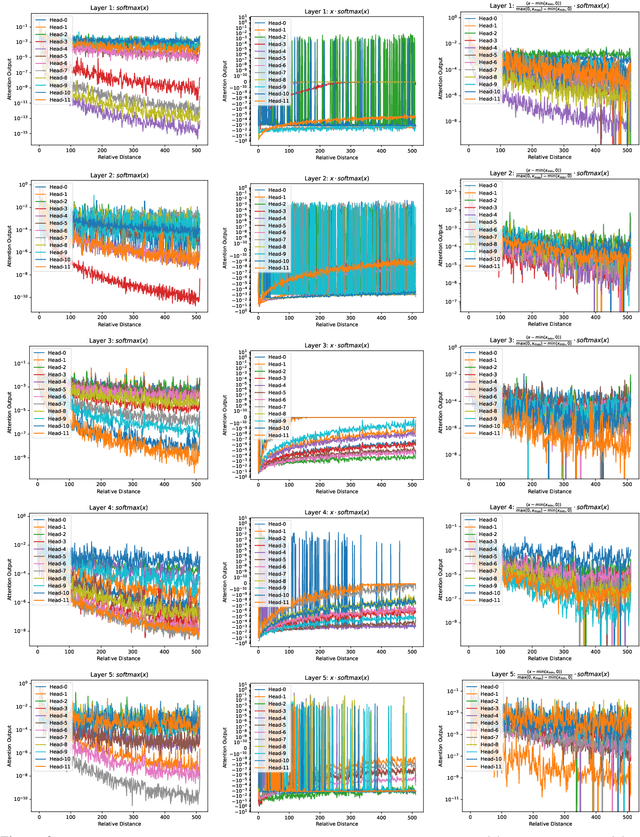
The softmax function is crucial in Transformer attention, which normalizes each row of the attention scores with summation to one, achieving superior performances over other alternative functions. However, the softmax function can face a gradient vanishing issue when some elements of the attention scores approach extreme values, such as probabilities close to one or zero. In this paper, we propose Self-Adjust Softmax (SA-Softmax) to address this issue by modifying $softmax(x)$ to $x \cdot softmax(x)$ and its normalized variant $\frac{(x - min(x_{\min},0))}{max(0,x_{max})-min(x_{min},0)} \cdot softmax(x)$. We theoretically show that SA-Softmax provides enhanced gradient properties compared to the vanilla softmax function. Moreover, SA-Softmax Attention can be seamlessly integrated into existing Transformer models to their attention mechanisms with minor adjustments. We conducted experiments to evaluate the empirical performance of Transformer models using SA-Softmax compared to the vanilla softmax function. These experiments, involving models with up to 2.7 billion parameters, are conducted across diverse datasets, language tasks, and positional encoding methods.
SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator
Dec 16, 2024



Large Language Models (LLMs) have exhibited exceptional performance across a spectrum of natural language processing tasks. However, their substantial sizes pose considerable challenges, particularly in computational demands and inference speed, due to their quadratic complexity. In this work, we have identified a key pattern: certain seemingly meaningless special tokens (i.e., separators) contribute disproportionately to attention scores compared to semantically meaningful tokens. This observation suggests that information of the segments between these separator tokens can be effectively condensed into the separator tokens themselves without significant information loss. Guided by this insight, we introduce SepLLM, a plug-and-play framework that accelerates inference by compressing these segments and eliminating redundant tokens. Additionally, we implement efficient kernels for training acceleration. Experimental results across training-free, training-from-scratch, and post-training settings demonstrate SepLLM's effectiveness. Notably, using the Llama-3-8B backbone, SepLLM achieves over 50% reduction in KV cache on the GSM8K-CoT benchmark while maintaining comparable performance. Furthermore, in streaming settings, SepLLM effectively processes sequences of up to 4 million tokens or more while maintaining consistent language modeling capabilities.
Scaling Law for Language Models Training Considering Batch Size
Dec 02, 2024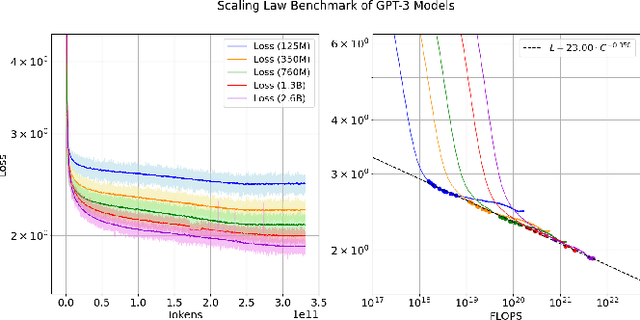
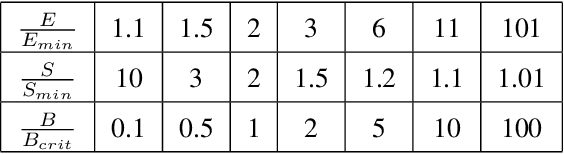

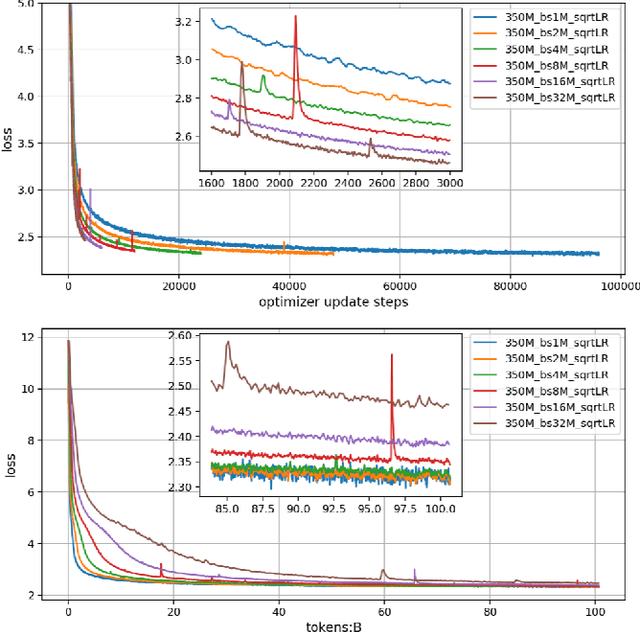
Large language models (LLMs) have made remarkable advances in recent years, with scaling laws playing a critical role in this rapid progress. In this paper, we empirically investigate how a critical hyper-parameter, i.e., the global batch size, influences the LLM training prdocess. We begin by training language models ranging from 125 million to 2.6 billion parameters, using up to 300 billion high-quality tokens. Through these experiments, we establish a basic scaling law on model size and training data amount. We then examine how varying batch sizes and learning rates affect the convergence and generalization of these models. Our analysis yields batch size scaling laws under two different cases: with a fixed compute budget, and with a fixed amount of training data. Extrapolation experiments on models of increasing sizes validate our predicted laws, which provides guidance for optimizing LLM training strategies under specific resource constraints.
DAPE V2: Process Attention Score as Feature Map for Length Extrapolation
Oct 07, 2024



The attention mechanism is a fundamental component of the Transformer model, contributing to interactions among distinct tokens, in contrast to earlier feed-forward neural networks. In general, the attention scores are determined simply by the key-query products. However, this work's occasional trial (combining DAPE and NoPE) of including additional MLPs on attention scores without position encoding indicates that the classical key-query multiplication may limit the performance of Transformers. In this work, we conceptualize attention as a feature map and apply the convolution operator (for neighboring attention scores across different heads) to mimic the processing methods in computer vision. Specifically, the main contribution of this paper is identifying and interpreting the Transformer length extrapolation problem as a result of the limited expressiveness of the naive query and key dot product, and we successfully translate the length extrapolation issue into a well-understood feature map processing problem. The novel insight, which can be adapted to various attention-related models, reveals that the current Transformer architecture has the potential for further evolution. Extensive experiments demonstrate that treating attention as a feature map and applying convolution as a processing method significantly enhances Transformer performance.
CAPE: Context-Adaptive Positional Encoding for Length Extrapolation
May 23, 2024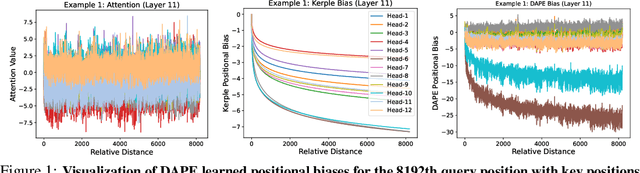
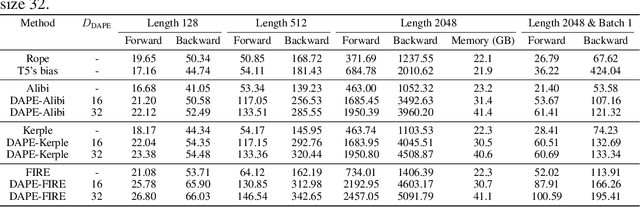
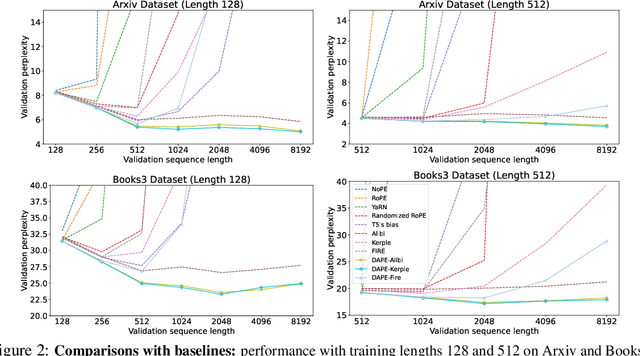
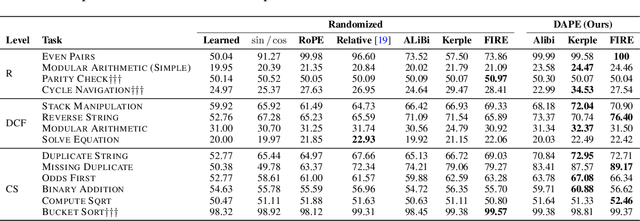
Positional encoding plays a crucial role in transformers, significantly impacting model performance and length generalization. Prior research has introduced absolute positional encoding (APE) and relative positional encoding (RPE) to distinguish token positions in given sequences. However, both APE and RPE remain fixed after model training regardless of input data, limiting their adaptability and flexibility. Hence, we expect that the desired positional encoding should be context-adaptive and can be dynamically adjusted with the given attention. In this paper, we propose a Context-Adaptive Positional Encoding (CAPE) method, which dynamically and semantically adjusts based on input context and learned fixed priors. Experimental validation on real-world datasets (Arxiv, Books3, and CHE) demonstrates that CAPE enhances model performances in terms of trained length and length generalization, where the improvements are statistically significant. The model visualization suggests that our model can keep both local and anti-local information. Finally, we successfully train the model on sequence length 128 and achieve better performance at evaluation sequence length 8192, compared with other static positional encoding methods, revealing the benefit of the adaptive positional encoding method.
PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
Mar 07, 2024



In this paper, we introduce PixArt-\Sigma, a Diffusion Transformer model~(DiT) capable of directly generating images at 4K resolution. PixArt-\Sigma represents a significant advancement over its predecessor, PixArt-\alpha, offering images of markedly higher fidelity and improved alignment with text prompts. A key feature of PixArt-\Sigma is its training efficiency. Leveraging the foundational pre-training of PixArt-\alpha, it evolves from the `weaker' baseline to a `stronger' model via incorporating higher quality data, a process we term "weak-to-strong training". The advancements in PixArt-\Sigma are twofold: (1) High-Quality Training Data: PixArt-\Sigma incorporates superior-quality image data, paired with more precise and detailed image captions. (2) Efficient Token Compression: we propose a novel attention module within the DiT framework that compresses both keys and values, significantly improving efficiency and facilitating ultra-high-resolution image generation. Thanks to these improvements, PixArt-\Sigma achieves superior image quality and user prompt adherence capabilities with significantly smaller model size (0.6B parameters) than existing text-to-image diffusion models, such as SDXL (2.6B parameters) and SD Cascade (5.1B parameters). Moreover, PixArt-\Sigma's capability to generate 4K images supports the creation of high-resolution posters and wallpapers, efficiently bolstering the production of high-quality visual content in industries such as film and gaming.
A Survey of Reasoning with Foundation Models
Dec 26, 2023


Reasoning, a crucial ability for complex problem-solving, plays a pivotal role in various real-world settings such as negotiation, medical diagnosis, and criminal investigation. It serves as a fundamental methodology in the field of Artificial General Intelligence (AGI). With the ongoing development of foundation models, there is a growing interest in exploring their abilities in reasoning tasks. In this paper, we introduce seminal foundation models proposed or adaptable for reasoning, highlighting the latest advancements in various reasoning tasks, methods, and benchmarks. We then delve into the potential future directions behind the emergence of reasoning abilities within foundation models. We also discuss the relevance of multimodal learning, autonomous agents, and super alignment in the context of reasoning. By discussing these future research directions, we hope to inspire researchers in their exploration of this field, stimulate further advancements in reasoning with foundation models, and contribute to the development of AGI.
EdgeFM: Leveraging Foundation Model for Open-set Learning on the Edge
Nov 23, 2023



Deep Learning (DL) models have been widely deployed on IoT devices with the help of advancements in DL algorithms and chips. However, the limited resources of edge devices make these on-device DL models hard to be generalizable to diverse environments and tasks. Although the recently emerged foundation models (FMs) show impressive generalization power, how to effectively leverage the rich knowledge of FMs on resource-limited edge devices is still not explored. In this paper, we propose EdgeFM, a novel edge-cloud cooperative system with open-set recognition capability. EdgeFM selectively uploads unlabeled data to query the FM on the cloud and customizes the specific knowledge and architectures for edge models. Meanwhile, EdgeFM conducts dynamic model switching at run-time taking into account both data uncertainty and dynamic network variations, which ensures the accuracy always close to the original FM. We implement EdgeFM using two FMs on two edge platforms. We evaluate EdgeFM on three public datasets and two self-collected datasets. Results show that EdgeFM can reduce the end-to-end latency up to 3.2x and achieve 34.3% accuracy increase compared with the baseline.
CAME: Confidence-guided Adaptive Memory Efficient Optimization
Jul 05, 2023



Adaptive gradient methods, such as Adam and LAMB, have demonstrated excellent performance in the training of large language models. Nevertheless, the need for adaptivity requires maintaining second-moment estimates of the per-parameter gradients, which entails a high cost of extra memory overheads. To solve this problem, several memory-efficient optimizers (e.g., Adafactor) have been proposed to obtain a drastic reduction in auxiliary memory usage, but with a performance penalty. In this paper, we first study a confidence-guided strategy to reduce the instability of existing memory efficient optimizers. Based on this strategy, we propose CAME to simultaneously achieve two goals: fast convergence as in traditional adaptive methods, and low memory usage as in memory-efficient methods. Extensive experiments demonstrate the training stability and superior performance of CAME across various NLP tasks such as BERT and GPT-2 training. Notably, for BERT pre-training on the large batch size of 32,768, our proposed optimizer attains faster convergence and higher accuracy compared with the Adam optimizer. The implementation of CAME is publicly available.