 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Law for Language Models Training Considering Batch Size
Paper and Code
Dec 02, 2024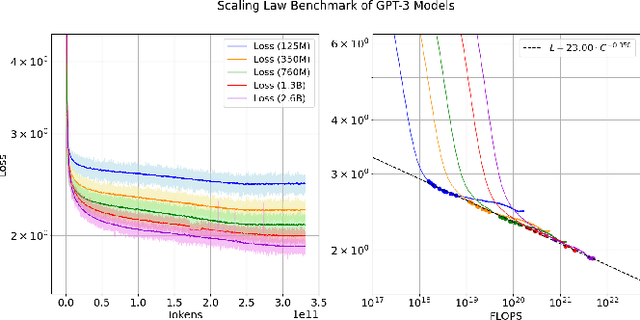

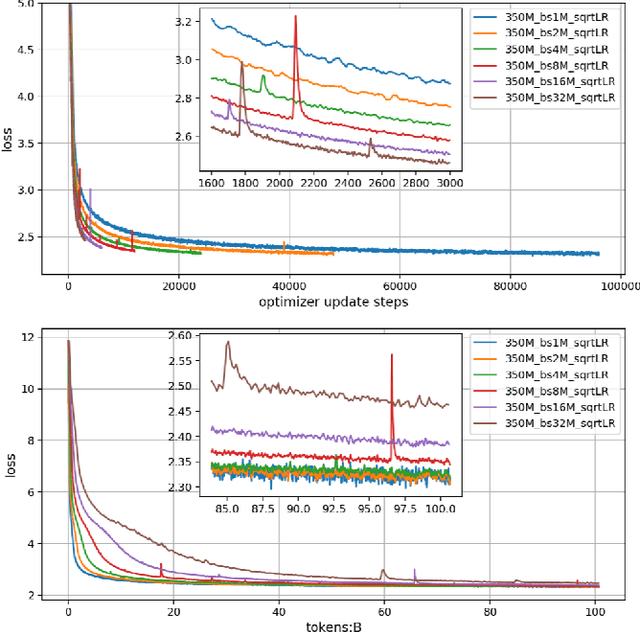
Large language models (LLMs) have made remarkable advances in recent years, with scaling laws playing a critical role in this rapid progress. In this paper, we empirically investigate how a critical hyper-parameter, i.e., the global batch size, influences the LLM training prdocess. We begin by training language models ranging from 125 million to 2.6 billion parameters, using up to 300 billion high-quality tokens. Through these experiments, we establish a basic scaling law on model size and training data amount. We then examine how varying batch sizes and learning rates affect the convergence and generalization of these models. Our analysis yields batch size scaling laws under two different cases: with a fixed compute budget, and with a fixed amount of training data. Extrapolation experiments on models of increasing sizes validate our predicted laws, which provides guidance for optimizing LLM training strategies under specific resource constraints.