 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Law for Language Models Training Considering Batch Size
Dec 02, 2024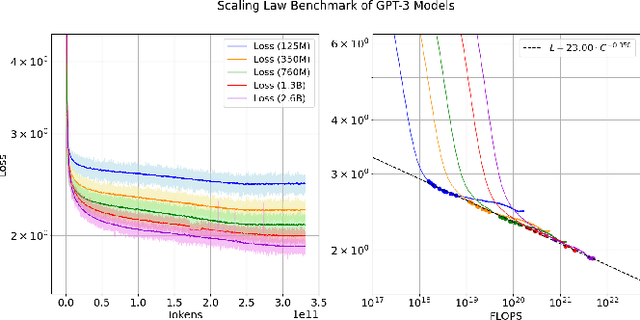
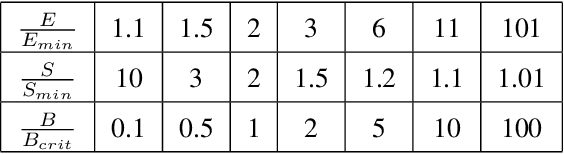

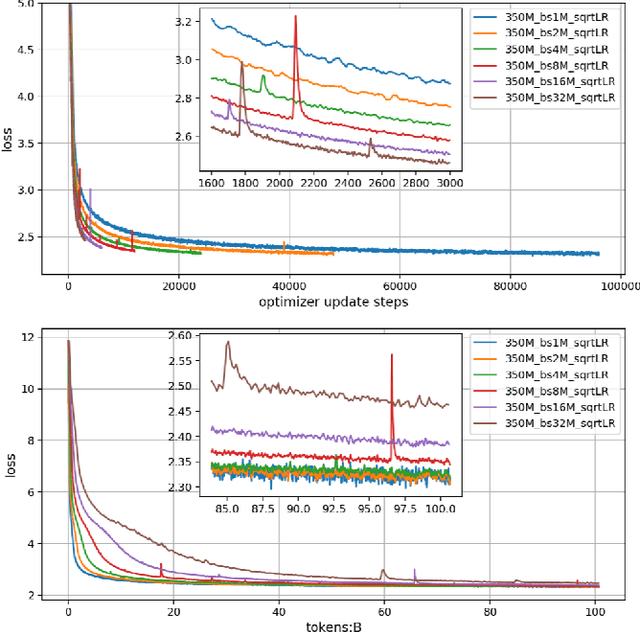
Large language models (LLMs) have made remarkable advances in recent years, with scaling laws playing a critical role in this rapid progress. In this paper, we empirically investigate how a critical hyper-parameter, i.e., the global batch size, influences the LLM training prdocess. We begin by training language models ranging from 125 million to 2.6 billion parameters, using up to 300 billion high-quality tokens. Through these experiments, we establish a basic scaling law on model size and training data amount. We then examine how varying batch sizes and learning rates affect the convergence and generalization of these models. Our analysis yields batch size scaling laws under two different cases: with a fixed compute budget, and with a fixed amount of training data. Extrapolation experiments on models of increasing sizes validate our predicted laws, which provides guidance for optimizing LLM training strategies under specific resource constraints.
EdgeFM: Leveraging Foundation Model for Open-set Learning on the Edge
Nov 23, 2023



Deep Learning (DL) models have been widely deployed on IoT devices with the help of advancements in DL algorithms and chips. However, the limited resources of edge devices make these on-device DL models hard to be generalizable to diverse environments and tasks. Although the recently emerged foundation models (FMs) show impressive generalization power, how to effectively leverage the rich knowledge of FMs on resource-limited edge devices is still not explored. In this paper, we propose EdgeFM, a novel edge-cloud cooperative system with open-set recognition capability. EdgeFM selectively uploads unlabeled data to query the FM on the cloud and customizes the specific knowledge and architectures for edge models. Meanwhile, EdgeFM conducts dynamic model switching at run-time taking into account both data uncertainty and dynamic network variations, which ensures the accuracy always close to the original FM. We implement EdgeFM using two FMs on two edge platforms. We evaluate EdgeFM on three public datasets and two self-collected datasets. Results show that EdgeFM can reduce the end-to-end latency up to 3.2x and achieve 34.3% accuracy increase compared with the baseline.
ADMarker: A Multi-Modal Federated Learning System for Monitoring Digital Biomarkers of Alzheimer's Disease
Oct 23, 2023



Alzheimer's Disease (AD) and related dementia are a growing global health challenge due to the aging population. In this paper, we present ADMarker, the first end-to-end system that integrates multi-modal sensors and new federated learning algorithms for detecting multidimensional AD digital biomarkers in natural living environments. ADMarker features a novel three-stage multi-modal federated learning architecture that can accurately detect digital biomarkers in a privacy-preserving manner. Our approach collectively addresses several major real-world challenges, such as limited data labels, data heterogeneity, and limited computing resources. We built a compact multi-modality hardware system and deployed it in a four-week clinical trial involving 91 elderly participants. The results indicate that ADMarker can accurately detect a comprehensive set of digital biomarkers with up to 93.8% accuracy and identify early AD with an average of 88.9% accuracy. ADMarker offers a new platform that can allow AD clinicians to characterize and track the complex correlation between multidimensional interpretable digital biomarkers, demographic factors of patients, and AD diagnosis in a longitudinal manner.
Moses: Efficient Exploitation of Cross-device Transferable Features for Tensor Program Optimization
Jan 15, 2022
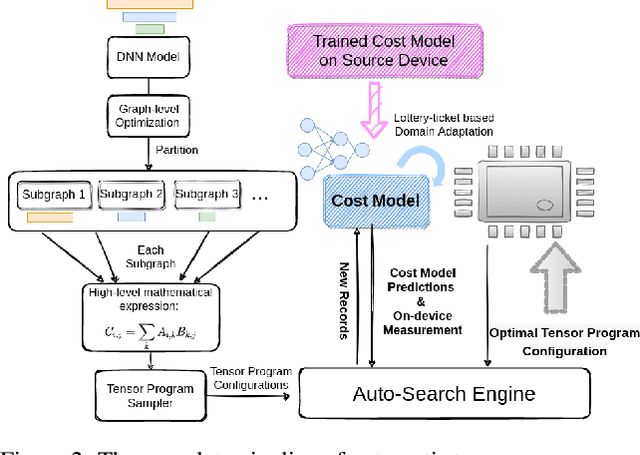
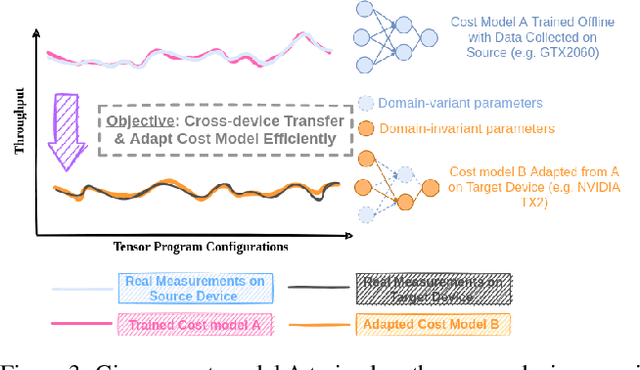
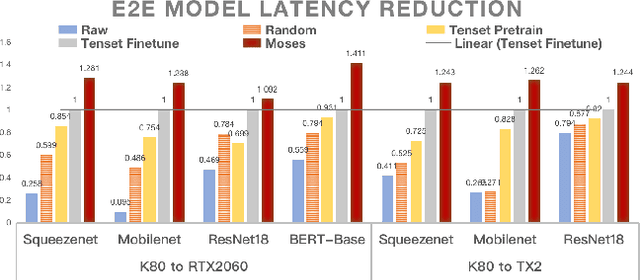
Achieving efficient execution of machine learning models has attracted significant attention recently. To generate tensor programs efficiently, a key component of DNN compilers is the cost model that can predict the performance of each configuration on specific devices. However, due to the rapid emergence of hardware platforms, it is increasingly labor-intensive to train domain-specific predictors for every new platform. Besides, current design of cost models cannot provide transferable features between different hardware accelerators efficiently and effectively. In this paper, we propose Moses, a simple and efficient design based on the lottery ticket hypothesis, which fully takes advantage of the features transferable to the target device via domain adaptation. Compared with state-of-the-art approaches, Moses achieves up to 1.53X efficiency gain in the search stage and 1.41X inference speedup on challenging DNN benchmarks.