 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Training Inference Mismatch in LLM Reinforcement Learning
May 14, 2026Modern LLM RL systems separate rollout generation from policy optimization. These two stages are expected to produce token probabilities that match exactly. However, implementation differences can make them assign different values to the same sequence under the same model weights, inducing Training-Inference Mismatch (TIM). TIM is difficult to inspect because it is entangled with off-policy drift and common stabilization mechanisms. In this work, we isolate TIM in a zero-mismatch diagnostic setting (VeXact), and show that small token-level numerical disagreements can independently cause training collapse. We further show that TIM changes the effective optimization problem, and identify a set of remedies that could mitigate TIM. Our results suggest that TIM is not benign numerical noise, but a systems-level perturbation that should be treated as a first-order factor in analyzing LLM RL stability.
TimelyLLM: Segmented LLM Serving System for Time-sensitive Robotic Applications
Dec 24, 2024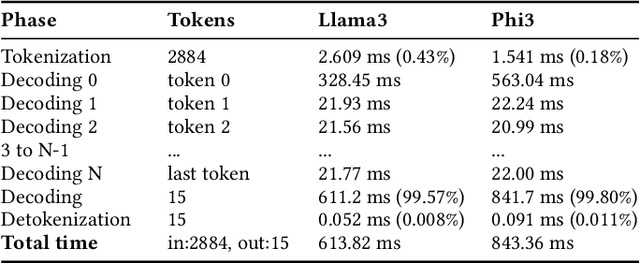
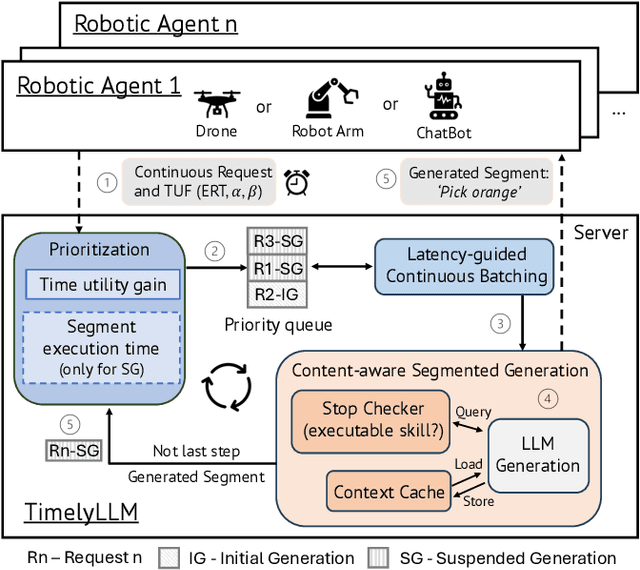
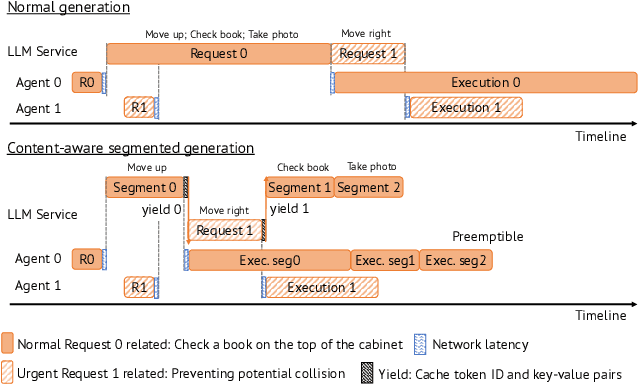
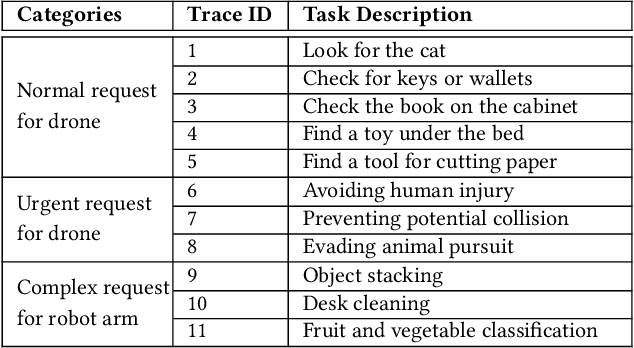
Large Language Models (LLMs) such as GPT-4 and Llama3 can already comprehend complex commands and process diverse tasks. This advancement facilitates their application in controlling drones and robots for various tasks. However, existing LLM serving systems typically employ a first-come, first-served (FCFS) batching mechanism, which fails to address the time-sensitive requirements of robotic applications. To address it, this paper proposes a new system named TimelyLLM serving multiple robotic agents with time-sensitive requests. TimelyLLM introduces novel mechanisms of segmented generation and scheduling that optimally leverage redundancy between robot plan generation and execution phases. We report an implementation of TimelyLLM on a widely-used LLM serving framework and evaluate it on a range of robotic applications. Our evaluation shows that TimelyLLM improves the time utility up to 1.97x, and reduces the overall waiting time by 84%.
Soar: Design and Deployment of A Smart Roadside Infrastructure System for Autonomous Driving
Apr 21, 2024
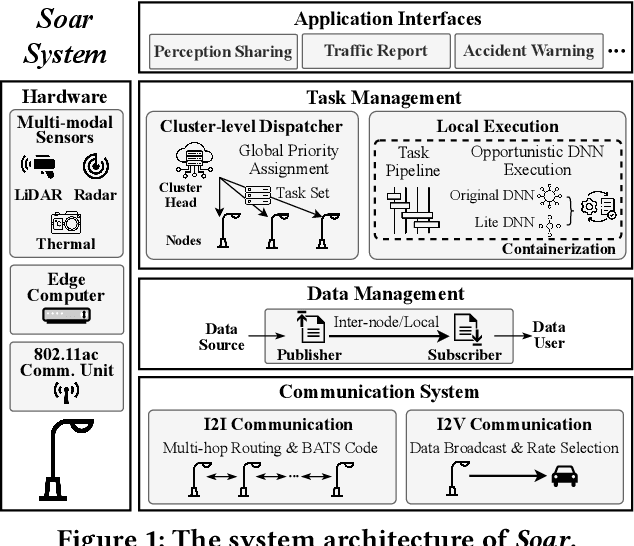
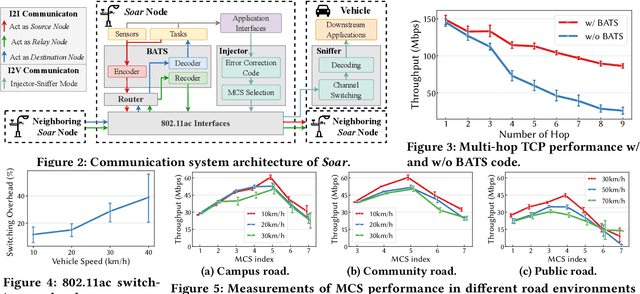
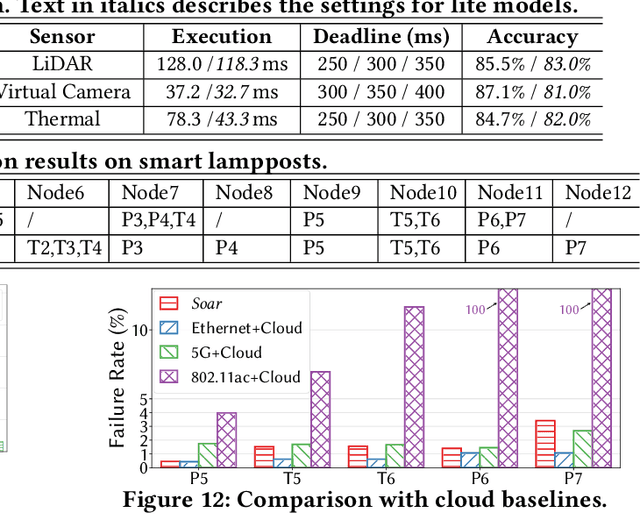
Recently,smart roadside infrastructure (SRI) has demonstrated the potential of achieving fully autonomous driving systems. To explore the potential of infrastructure-assisted autonomous driving, this paper presents the design and deployment of Soar, the first end-to-end SRI system specifically designed to support autonomous driving systems. Soar consists of both software and hardware components carefully designed to overcome various system and physical challenges. Soar can leverage the existing operational infrastructure like street lampposts for a lower barrier of adoption. Soar adopts a new communication architecture that comprises a bi-directional multi-hop I2I network and a downlink I2V broadcast service, which are designed based on off-the-shelf 802.11ac interfaces in an integrated manner. Soar also features a hierarchical DL task management framework to achieve desirable load balancing among nodes and enable them to collaborate efficiently to run multiple data-intensive autonomous driving applications. We deployed a total of 18 Soar nodes on existing lampposts on campus, which have been operational for over two years. Our real-world evaluation shows that Soar can support a diverse set of autonomous driving applications and achieve desirable real-time performance and high communication reliability. Our findings and experiences in this work offer key insights into the development and deployment of next-generation smart roadside infrastructure and autonomous driving systems.
EdgeFM: Leveraging Foundation Model for Open-set Learning on the Edge
Nov 23, 2023



Deep Learning (DL) models have been widely deployed on IoT devices with the help of advancements in DL algorithms and chips. However, the limited resources of edge devices make these on-device DL models hard to be generalizable to diverse environments and tasks. Although the recently emerged foundation models (FMs) show impressive generalization power, how to effectively leverage the rich knowledge of FMs on resource-limited edge devices is still not explored. In this paper, we propose EdgeFM, a novel edge-cloud cooperative system with open-set recognition capability. EdgeFM selectively uploads unlabeled data to query the FM on the cloud and customizes the specific knowledge and architectures for edge models. Meanwhile, EdgeFM conducts dynamic model switching at run-time taking into account both data uncertainty and dynamic network variations, which ensures the accuracy always close to the original FM. We implement EdgeFM using two FMs on two edge platforms. We evaluate EdgeFM on three public datasets and two self-collected datasets. Results show that EdgeFM can reduce the end-to-end latency up to 3.2x and achieve 34.3% accuracy increase compared with the baseline.
Timely Fusion of Surround Radar/Lidar for Object Detection in Autonomous Driving Systems
Sep 09, 2023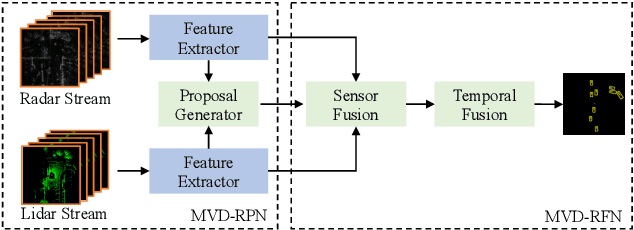
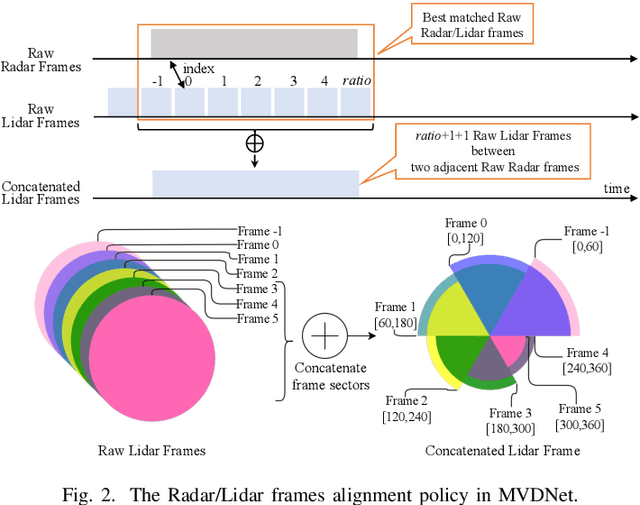
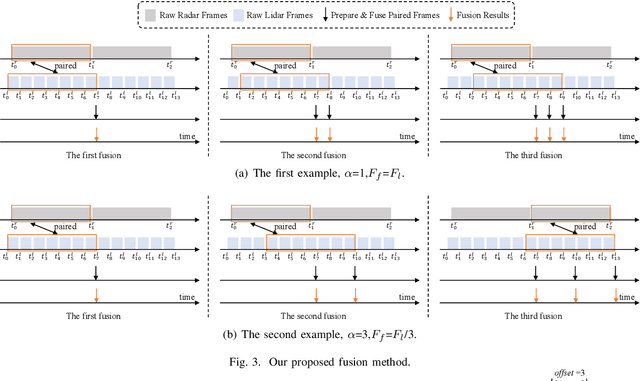
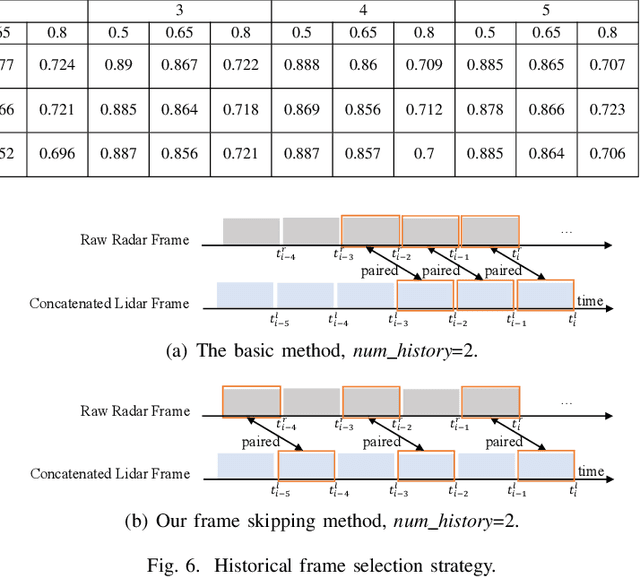
Fusing Radar and Lidar sensor data can fully utilize their complementary advantages and provide more accurate reconstruction of the surrounding for autonomous driving systems. Surround Radar/Lidar can provide 360-degree view sampling with the minimal cost, which are promising sensing hardware solutions for autonomous driving systems. However, due to the intrinsic physical constraints, the rotating speed of surround Radar, and thus the frequency to generate Radar data frames, is much lower than surround Lidar. Existing Radar/Lidar fusion methods have to work at the low frequency of surround Radar, which cannot meet the high responsiveness requirement of autonomous driving systems.This paper develops techniques to fuse surround Radar/Lidar with working frequency only limited by the faster surround Lidar instead of the slower surround Radar, based on the state-of-the-art object detection model MVDNet. The basic idea of our approach is simple: we let MVDNet work with temporally unaligned data from Radar/Lidar, so that fusion can take place at any time when a new Lidar data frame arrives, instead of waiting for the slow Radar data frame. However, directly applying MVDNet to temporally unaligned Radar/Lidar data greatly degrades its object detection accuracy. The key information revealed in this paper is that we can achieve high output frequency with little accuracy loss by enhancing the training procedure to explore the temporal redundancy in MVDNet so that it can tolerate the temporal unalignment of input data. We explore several different ways of training enhancement and compare them quantitatively with experiments.
Miriam: Exploiting Elastic Kernels for Real-time Multi-DNN Inference on Edge GPU
Jul 10, 2023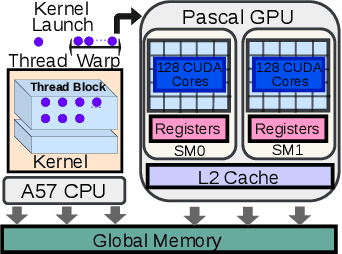

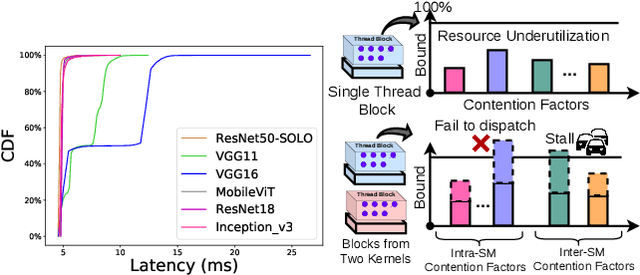

Many applications such as autonomous driving and augmented reality, require the concurrent running of multiple deep neural networks (DNN) that poses different levels of real-time performance requirements. However, coordinating multiple DNN tasks with varying levels of criticality on edge GPUs remains an area of limited study. Unlike server-level GPUs, edge GPUs are resource-limited and lack hardware-level resource management mechanisms for avoiding resource contention. Therefore, we propose Miriam, a contention-aware task coordination framework for multi-DNN inference on edge GPU. Miriam consolidates two main components, an elastic-kernel generator, and a runtime dynamic kernel coordinator, to support mixed critical DNN inference. To evaluate Miriam, we build a new DNN inference benchmark based on CUDA with diverse representative DNN workloads. Experiments on two edge GPU platforms show that Miriam can increase system throughput by 92% while only incurring less than 10\% latency overhead for critical tasks, compared to state of art baselines.
Moses: Efficient Exploitation of Cross-device Transferable Features for Tensor Program Optimization
Jan 15, 2022
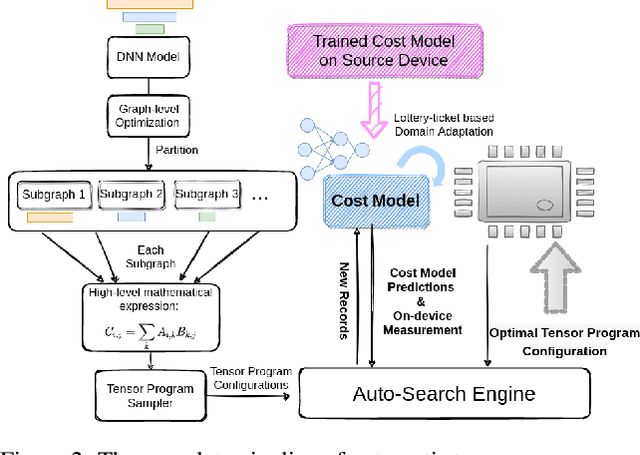
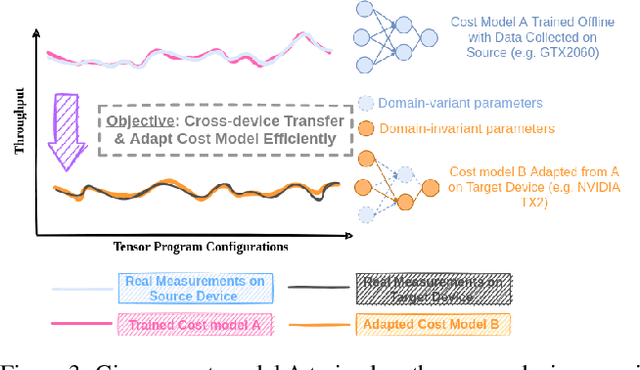
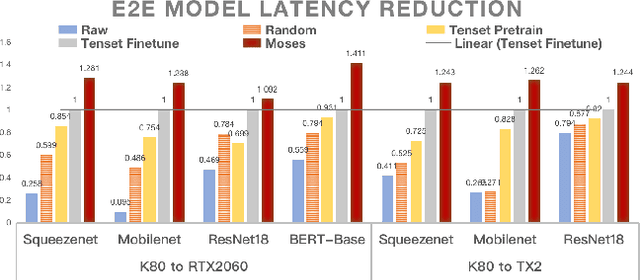
Achieving efficient execution of machine learning models has attracted significant attention recently. To generate tensor programs efficiently, a key component of DNN compilers is the cost model that can predict the performance of each configuration on specific devices. However, due to the rapid emergence of hardware platforms, it is increasingly labor-intensive to train domain-specific predictors for every new platform. Besides, current design of cost models cannot provide transferable features between different hardware accelerators efficiently and effectively. In this paper, we propose Moses, a simple and efficient design based on the lottery ticket hypothesis, which fully takes advantage of the features transferable to the target device via domain adaptation. Compared with state-of-the-art approaches, Moses achieves up to 1.53X efficiency gain in the search stage and 1.41X inference speedup on challenging DNN benchmarks.