 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMaPOI: A Collaborative Multi-Agent Framework for Next POI Prediction Bridging the Gap Between Trajectory and Language
May 28, 2025
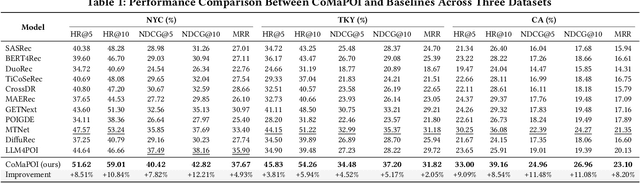
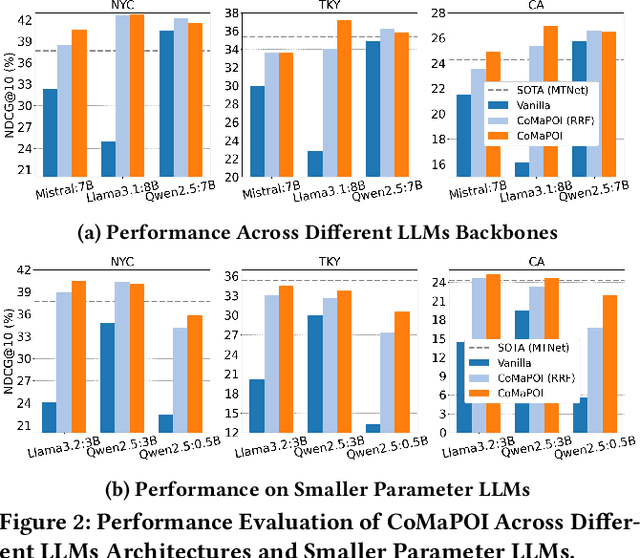
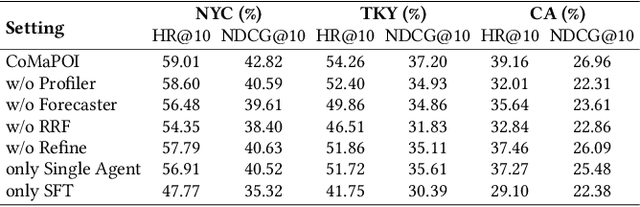
Large Language Models (LLMs) offer new opportunities for the next Point-Of-Interest (POI) prediction task, leveraging their capabilities in semantic understanding of POI trajectories. However, previous LLM-based methods, which are superficially adapted to next POI prediction, largely overlook critical challenges associated with applying LLMs to this task. Specifically, LLMs encounter two critical challenges: (1) a lack of intrinsic understanding of numeric spatiotemporal data, which hinders accurate modeling of users' spatiotemporal distributions and preferences; and (2) an excessively large and unconstrained candidate POI space, which often results in random or irrelevant predictions. To address these issues, we propose a Collaborative Multi Agent Framework for Next POI Prediction, named CoMaPOI. Through the close interaction of three specialized agents (Profiler, Forecaster, and Predictor), CoMaPOI collaboratively addresses the two critical challenges. The Profiler agent is responsible for converting numeric data into language descriptions, enhancing semantic understanding. The Forecaster agent focuses on dynamically constraining and refining the candidate POI space. The Predictor agent integrates this information to generate high-precision predictions. Extensive experiments on three benchmark datasets (NYC, TKY, and CA) demonstrate that CoMaPOI achieves state of the art performance, improving all metrics by 5% to 10% compared to SOTA baselines. This work pioneers the investigation of challenges associated with applying LLMs to complex spatiotemporal tasks by leveraging tailored collaborative agents.
MappedTrace: Tracing Pointer Remotely with Compiler-generated Maps
Jan 18, 2025Existing precise pointer tracing methods introduce substantial runtime overhead to the program being traced and are applicable only at specific program execution points. We propose MappedTrace that leverages compiler-generated read-only maps to accurately identify all pointers in any given snapshot of a program's execution state. The maps record the locations and types of pointers, allowing the tracer to precisely identify pointers without requiring the traced program to maintain bookkeeping data structures or poll at safe points, thereby reducing runtime overhead. By running the tracer from a different address space or machine, MappedTrace presents new opportunities to improve memory management techniques like memory leak detection and enables novel use cases such as infinite memory abstraction for resource-constrained environments.
TimelyLLM: Segmented LLM Serving System for Time-sensitive Robotic Applications
Dec 24, 2024
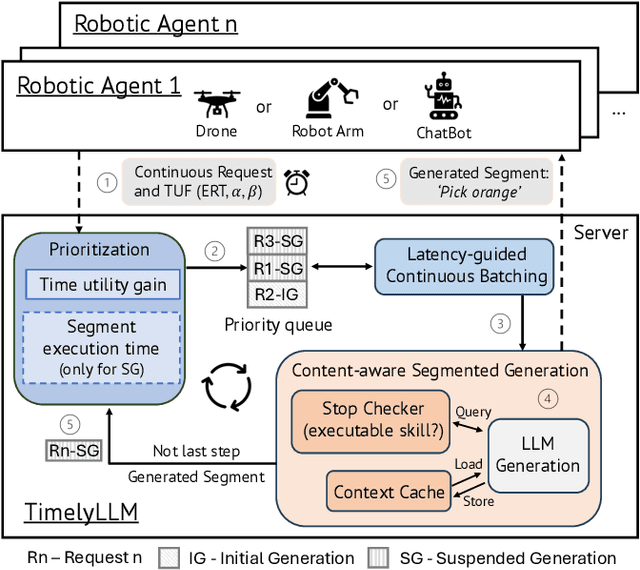
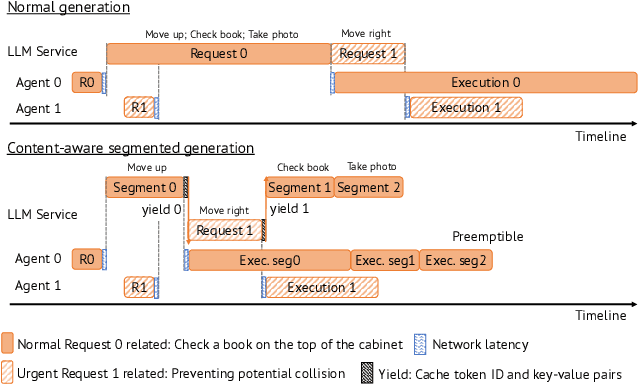
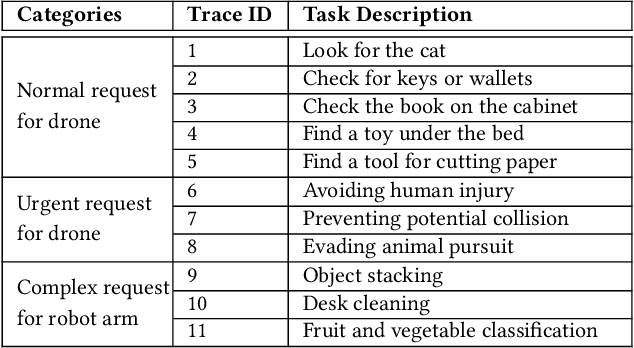
Large Language Models (LLMs) such as GPT-4 and Llama3 can already comprehend complex commands and process diverse tasks. This advancement facilitates their application in controlling drones and robots for various tasks. However, existing LLM serving systems typically employ a first-come, first-served (FCFS) batching mechanism, which fails to address the time-sensitive requirements of robotic applications. To address it, this paper proposes a new system named TimelyLLM serving multiple robotic agents with time-sensitive requests. TimelyLLM introduces novel mechanisms of segmented generation and scheduling that optimally leverage redundancy between robot plan generation and execution phases. We report an implementation of TimelyLLM on a widely-used LLM serving framework and evaluate it on a range of robotic applications. Our evaluation shows that TimelyLLM improves the time utility up to 1.97x, and reduces the overall waiting time by 84%.
Asynchronous LLM Function Calling
Dec 09, 2024Large language models (LLMs) use function calls to interface with external tools and data source. However, the current approach to LLM function calling is inherently synchronous, where each call blocks LLM inference, limiting LLM operation and concurrent function execution. In this work, we propose AsyncLM, a system for asynchronous LLM function calling. AsyncLM improves LLM's operational efficiency by enabling LLMs to generate and execute function calls concurrently. Instead of waiting for each call's completion, AsyncLM introduces an interrupt mechanism to asynchronously notify the LLM in-flight when function calls return. We design an in-context protocol for function calls and interrupts, provide fine-tuning strategy to adapt LLMs to the interrupt semantics, and implement these mechanisms efficiently on LLM inference process. We demonstrate that AsyncLM can reduce end-to-end task completion latency from 1.6x-5.4x compared to synchronous function calling on a set of benchmark tasks in the Berkeley function calling leaderboard (BFCL). Furthermore, we discuss how interrupt mechanisms can be extended to enable novel human-LLM or LLM-LLM interactions.
Confidential Prompting: Protecting User Prompts from Cloud LLM Providers
Sep 27, 2024

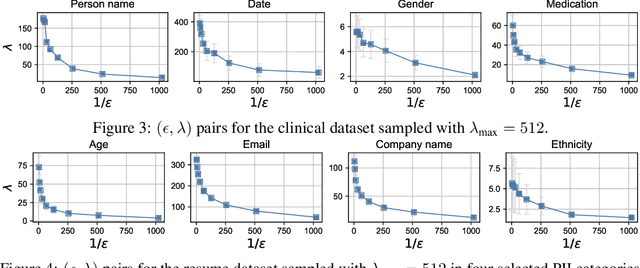
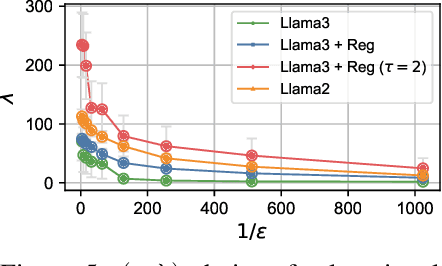
Our work tackles the challenge of securing user inputs in cloud-based large language model (LLM) services while ensuring output consistency, model confidentiality, and compute efficiency. We introduce Secure Multi-party Decoding (SMD), which leverages confidential computing to confine user prompts to a trusted execution environment, namely a confidential virtual machine (CVM), while allowing service providers to generate tokens efficiently. We also introduce a novel cryptographic method, Prompt Obfuscation (PO), to ensure robustness against reconstruction attacks on SMD. We demonstrate that our approach preserves both prompt confidentiality and LLM serving efficiency. Our solution can enable privacy-preserving cloud LLM services that handle sensitive prompts, such as clinical records, financial data, and personal information.
FedHCDR: Federated Cross-Domain Recommendation with Hypergraph Signal Decoupling
Mar 06, 2024In recent years, Cross-Domain Recommendation (CDR) has drawn significant attention, which utilizes user data from multiple domains to enhance the recommendation performance. However, current CDR methods require sharing user data across domains, thereby violating the General Data Protection Regulation (GDPR). Consequently, numerous approaches have been proposed for Federated Cross-Domain Recommendation (FedCDR). Nevertheless, the data heterogeneity across different domains inevitably influences the overall performance of federated learning. In this study, we propose FedHCDR, a novel Federated Cross-Domain Recommendation framework with Hypergraph signal decoupling. Specifically, to address the data heterogeneity across domains, we introduce an approach called hypergraph signal decoupling (HSD) to decouple the user features into domain-exclusive and domain-shared features. The approach employs high-pass and low-pass hypergraph filters to decouple domain-exclusive and domain-shared user representations, which are trained by the local-global bi-directional transfer algorithm. In addition, a hypergraph contrastive learning (HCL) module is devised to enhance the learning of domain-shared user relationship information by perturbing the user hypergraph. Extensive experiments conducted on three real-world scenarios demonstrate that FedHCDR outperforms existing baselines significantly.
TypeFly: Flying Drones with Large Language Model
Dec 08, 2023Commanding a drone with a natural language is not only user-friendly but also opens the door for emerging language agents to control the drone. Emerging large language models (LLMs) provide a previously impossible opportunity to automatically translate a task description in a natural language to a program that can be executed by the drone. However, powerful LLMs and their vision counterparts are limited in three important ways. First, they are only available as cloud-based services. Sending images to the cloud raises privacy concerns. Second, they are expensive, costing proportionally to the request size. Finally, without expensive fine-tuning, existing LLMs are quite limited in their capability of writing a program for specialized systems like drones. In this paper, we present a system called TypeFly that tackles the above three problems using a combination of edge-based vision intelligence, novel programming language design, and prompt engineering. Instead of the familiar Python, TypeFly gets a cloud-based LLM service to write a program in a small, custom language called MiniSpec, based on task and scene descriptions in English. Such MiniSpec programs are not only succinct (and therefore efficient) but also able to consult the LLM during their execution using a special skill called query. Using a set of increasingly challenging drone tasks, we show that design choices made by TypeFly can reduce both the cost of LLM service and the task execution time by more than 2x. More importantly, query and prompt engineering techniques contributed by TypeFly significantly improve the chance of success of complex tasks.
Prompt Cache: Modular Attention Reuse for Low-Latency Inference
Nov 07, 2023



We present Prompt Cache, an approach for accelerating inference for large language models (LLM) by reusing attention states across different LLM prompts. Many input prompts have overlapping text segments, such as system messages, prompt templates, and documents provided for context. Our key insight is that by precomputing and storing the attention states of these frequently occurring text segments on the inference server, we can efficiently reuse them when these segments appear in user prompts. Prompt Cache employs a schema to explicitly define such reusable text segments, called prompt modules. The schema ensures positional accuracy during attention state reuse and provides users with an interface to access cached states in their prompt. Using a prototype implementation, we evaluate Prompt Cache across several LLMs. We show that Prompt Cache significantly reduce latency in time-to-first-token, especially for longer prompts such as document-based question answering and recommendations. The improvements range from 8x for GPU-based inference to 60x for CPU-based inference, all while maintaining output accuracy and without the need for model parameter modifications.
POD: A Smartphone That Flies
May 26, 2021

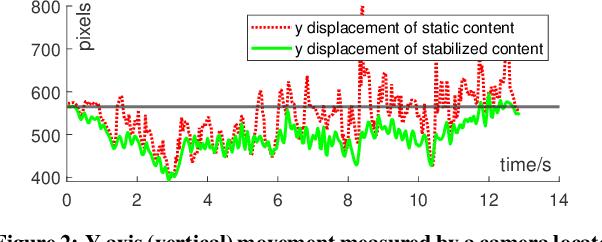
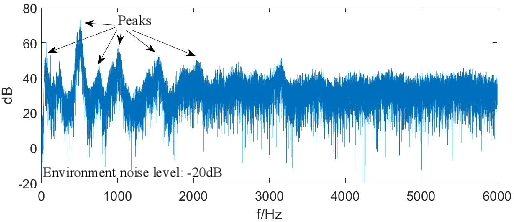
We present POD, a smartphone that flies, as a new way to achieve hands-free, eyes-up mobile computing. Unlike existing drone-carried user interfaces, POD features a smartphone-sized display and the computing and sensing power of a modern smartphone. We share our experience in building a prototype of POD, discuss the technical challenges facing it, and describe early results toward addressing them.
Privacy Adversarial Network: Representation Learning for Mobile Data Privacy
Jun 08, 2020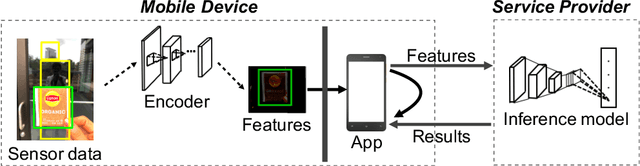

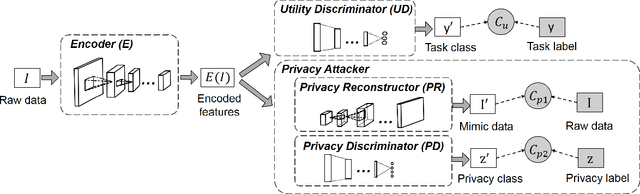
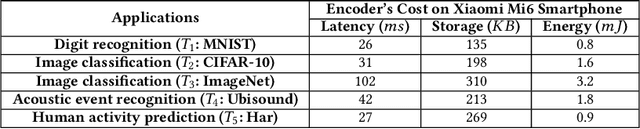
The remarkable success of machine learning has fostered a growing number of cloud-based intelligent services for mobile users. Such a service requires a user to send data, e.g. image, voice and video, to the provider, which presents a serious challenge to user privacy. To address this, prior works either obfuscate the data, e.g. add noise and remove identity information, or send representations extracted from the data, e.g. anonymized features. They struggle to balance between the service utility and data privacy because obfuscated data reduces utility and extracted representation may still reveal sensitive information. This work departs from prior works in methodology: we leverage adversarial learning to a better balance between privacy and utility. We design a \textit{representation encoder} that generates the feature representations to optimize against the privacy disclosure risk of sensitive information (a measure of privacy) by the \textit{privacy adversaries}, and concurrently optimize with the task inference accuracy (a measure of utility) by the \textit{utility discriminator}. The result is the privacy adversarial network (\systemname), a novel deep model with the new training algorithm, that can automatically learn representations from the raw data. Intuitively, PAN adversarially forces the extracted representations to only convey the information required by the target task. Surprisingly, this constitutes an implicit regularization that actually improves task accuracy. As a result, PAN achieves better utility and better privacy at the same time! We report extensive experiments on six popular datasets and demonstrate the superiority of \systemname compared with alternative methods reported in prior work.